数据平台的一个重要功能是数据集成。数据集成听起来是要从分布式走向单体,似乎不太符合当前技术领域要尽可能分布式的趋势。
但是,数据集成常常是必要的。这种必要性可能来自于企业战略上希望打破数据孤岛,也可能来自于某些数据分析需要跨业务线跨系统进行。
实现数据集成的一个重要问题是跨系统的数据关联。为什么这个问题如此重要?这还要从企业发展过程说起。
跨系统数据关联问题
很多企业在业务发展到一定程度之后,会进行业务和部门的拆分。这种拆分常常按照产品线来,比如华为,内部有运营商业务线、终端产品业务线等,在银行业务中,通常有存款业务线、信用卡业务线、对公贷款业务线等等。如果是大件产品生产(比如车企),则常常按照业务阶段进行拆分,比如线索部门、销售部门、售后部门等等。
根据康威定律(设计系统的组织由于受到约束,最终的设计往往是组织内部沟通结构的副本)可知,软件系统的最终形态会跟组织结构保持一致。于是,我们就常常可以看到各个业务线或者部门均纷纷构建了自己的软件系统。这些系统或者通过直接购买产品或者通过自研而来,不管怎样,系统的孤立和隔离就形成了。
当要对各个孤立的系统中的数据进行联合分析时,就不得不解决首先解决跨系统数据关联问题。这一问题非常棘手,但又不得不解决。本文尝试分享一些可供参考的经验。
下文将重点关注不同系统间的客户数据的关联。
客户OneID
很多企业都希望能实现千人千面的个性化客户服务,从而提高客户满意度,进而提升业绩。如何做到呢?这就要依赖近几年大家都在谈论的客户画像应用了。
对于一个按照业务阶段进行拆分的组织,其数据存储在各个隔离的系统中,需要将这些系统的数据打通,才能得出一个全面的客户画像。对于按照产品线进行拆分的组织,打通各个系统,有利于各个产品中的客户信息相互补充,客户画像更立体。
基于客户ID进行跨系统数据关联是很多企业都希望解决的问题。业界对这个问题讨论很多,阿里的中台战略(参考这里)里面甚至把这个问题提高到了最核心的位置之一(OneModel/OneID/OneService一起构成了OneData体系)。在实现时,阿里通过电话号码、浏览器Cookie、手机IMEI与IDFA广告标识、淘宝账户、支付宝账户、邮箱等将各个产品的用户进行关联。
不仅阿里,国内的各大互联网公司都有自己的客户ID关联实践。美团使用手机号、微信、微博、美团账号等进行关联,58同城则使用基于账号和设备的方式进行客户ID关联。(参考:https://www.163.com/dy/article/FQ8VSFJ10511805E.html)
业界把客户ID关联的过程叫做ID Mapping,关联的结果是形成了一个统一的基于“自然人”的客户ID,即客户OneID。在生成客户OneID的过程中所使用的标识信息,如手机号、证件号、邮箱等,下文称为候选标识。
客户OneID构建
在数据平台中进行OneID构建,有很多的挑战,比如:
- 各个系统的ID生成方式不统一,无法直接关联
- 各个系统搜集的候选标识(如手机号/邮箱等)信息不准确或者存在较多缺失
- 存在一个人多个手机号、邮箱的现实情况
- 各个系统中候选标识的可信度不同,比如在线索系统中可能手机号比较准确但是邮箱是可选的,还比如在销售系统中证件号码比较准确但是手机号、邮箱等是不准确的
- 用户的候选标识可能会随时间变更,各个系统的变更频率不同
这些问题在不同的企业上下文可能完全不一样,所以构建的方式与难度也会非常不一样。
比如,如果系统都是近几年构建的,那么可能都使用手机号作为客户的标识,手机号即可直接作为桥梁将多个系统的数据关联起来。这种情况实现客户OneID就非常容易。
但是,如果系统允许用于以游客身份访问,或者线索系统中仅记录了邮箱,或者售后系统可以有多个相关用户交替参与(比如汽车保养场景),此时实现客户OneID就可能非常困难。
基于一些实际项目经验来看,对于比较复杂的客户OneID构建,可以参考以下步骤和方法来构建客户OneID。
搜集信息
在开始之前,需要尽可能做调研,以便了解更多的背景信息,这些信息可以为后续制定合理的客户OneID构建策略提供输入。
在构建客户OneID时,一般需要更多的了解对应系统的操作方式,识别并梳理各类候选标识信息的录入方式,这样可以从业务角度了解各类信息的可信度。
除了从业务角度分析,还应基于现有的数据进行分析,通过探查各个各类候选标识信息的质量了解其可信度。一些基本的统计信息,如缺失率、唯一值比率、合法数据比率等是值得参考的指标。
在搜集了足够的背景信息之后,可将这些信息汇总成一个表格,示例如下:
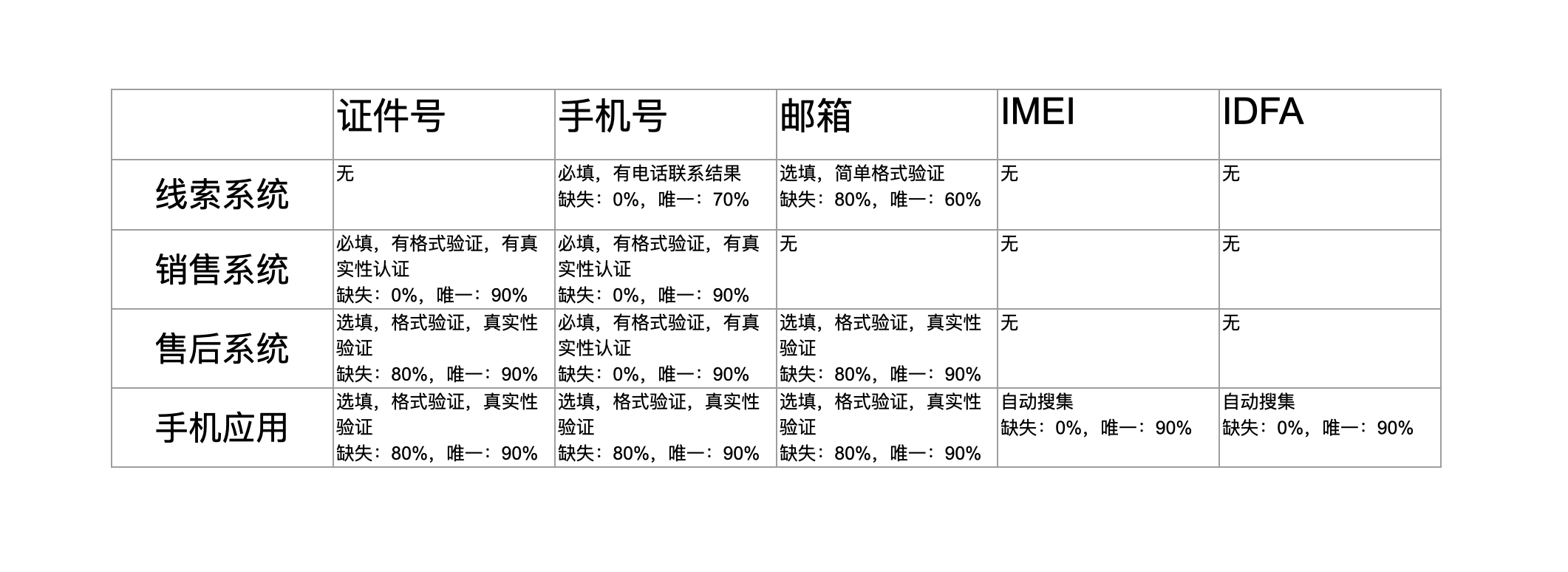
制定方案
有了上面表格中的信息就可以开始制定OneID关联方案了。
OneID方案主要包括两个步骤:
- 关联策略:一个基本策略是尽量用不同系统可信度最高的候选标识信息进行关联。
- 关联之后的数据合并策略:比如,不同的系统都搜集了客户的基本信息(如年龄、性别等),以哪一个为准呢?一般可以根据信息可信度、数据质量、数据更新时间等进行选择。
实践时,可以这样操作:
- 针对不同系统中的可用候选标识信息,按照可信度降序排列
- 选择不同系统之间的关联属性,制定统一的字段关联优先级
- 将数据按照关联优先级进行关联
- 根据信息可信度、数据质量、数据更新时间等制定数据合并策略
- 按照合并策略将数据合并到最后的数据表
实现
其中的关联过程可能是比较复杂的,一般可以有两种方式完成关联。
数据表关联
这种方式用SQL代码即可实现,步骤如下:
- 建立一个临时表
T1,设置其字段为所有系统整合得到的候选字段,并附加系统ID及系统业务ID字段 - 从所有系统提取数据,然后放入这个临时表
T1 - 根据候选字段优先级,从
T1中选出下一优先级的字段C1,根据此字段筛选出有效数据,然后按照此字段进行分组排序(用partition by表达式),筛选出某一系统ID及系统业务ID字段,根据这个数据生成OneID,得到表T2 - 从上一步骤得到的数据B中寻找已经计算过的数据的下一优先级字段
C2,根据此字段筛选出有效数据,得到表T3 - 从A中查找没有在B中且
C2为有效值的数据,和表T3合并,得到表T4 - 在
T4中根据字段C2进行分组(用partition by表达式),如果组内已有OneID,则优先用已有OneID,否则排序,筛选出某一系统ID及系统业务ID字段,根据这个数据生成OneID,得到表T5 - 将
T5表与T2表合并,得到T6 - 将
T6视为T2,重复步骤4-7,直到所有字段均计算完毕 - 将得到的最后的
T2表与T1表关联,并根据数据合并策略将数据筛选出来
连通图算法
应用连通图算法进行OneID关联的基本原理是:
- 将各个系统的数据,抽象为图的顶点。
- 根据可关联的候选字段,在不同的系统数据间进行关联,能关联上,就形成一条连接两个顶点的边。
- 上述顶点和边构成了一个图结构,从图结构中查找连通图,可找到一组关联的数据。
用图形表示如下:
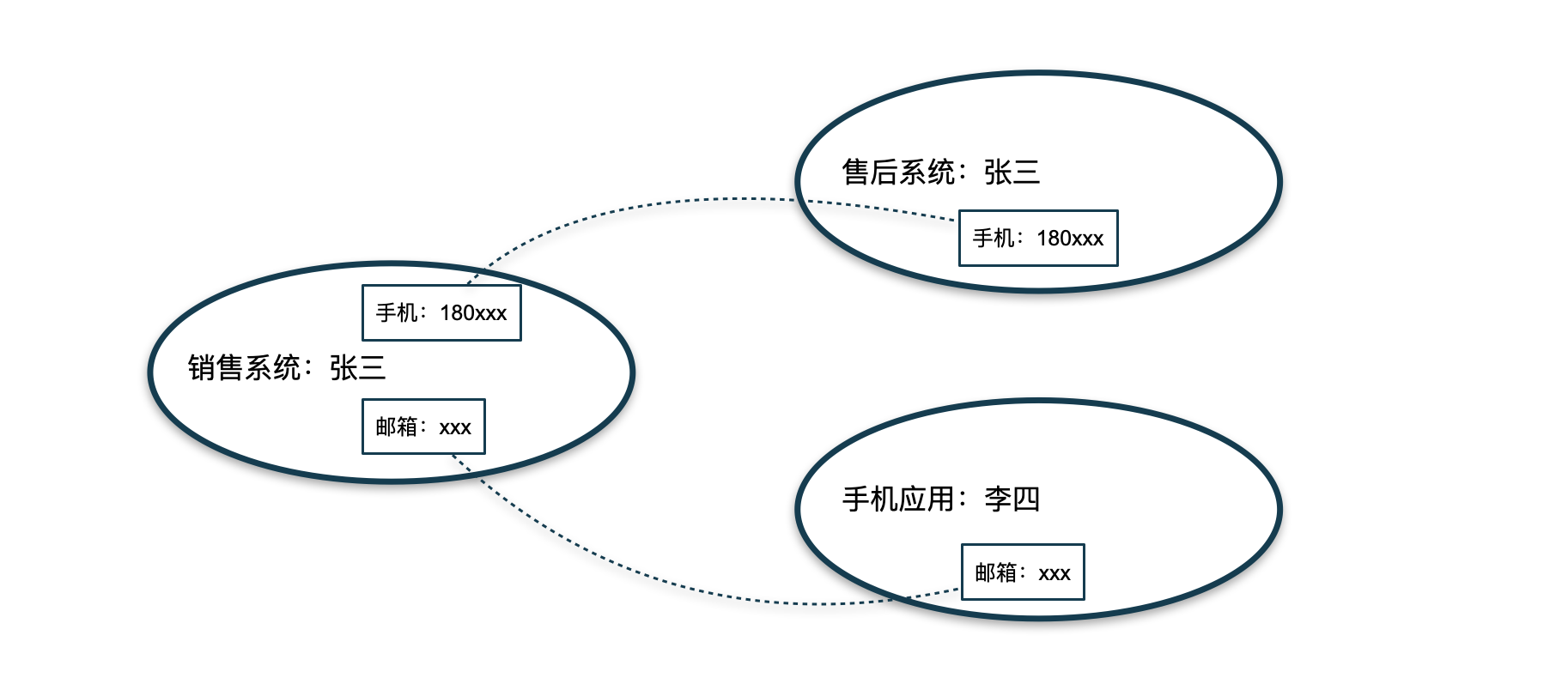
这种方式需要借助一些图计算的库(比如基于Spark的GraphX库,参考这里)进行实现。在实际实现时,由于需要应对大规模的数据,需要充分利用分布式计算的能力。运行于Spark之上的库就是一个不错的选择。
关键代码可参考以下示例:
1 | val vertices = spark.sql("select long_value(id), id").rdd |
这里识别出的OneID是整个连通图中的最小ID,如果希望OneID的编码有一定业务意义,可以通过这个映射表将所有的数据找出来,然后再重新生成一个OneID。
识别出了映射之后,下一步还需要根据合并规则进行基础数据合并,这时候与之前基于数据表关联的算法就没什么差别了。
在数据平台中实现
事实上,上述OneID构建过程都可以实现为ETL,然后纳入数据平台的统一调度系统进行定期调度执行。
基于数据表关联的算法,采用前面文章《数据应用开发语言和环境》中提到的ETL开发语言很容易实现。基于连通图算法的ETL,可以将这里的函数调用封装为一个函数,然后在一个统一的基于ETL开发语言的ETL文件中调用此函数计算OneID。
可以发现基于数据表关联的算法中存在一个循环,如果直接写SQL进行实现,则可能存在大量重复代码。如果用前文提到的ETL开发语言来实现,可以将大部分的代码封装为模板,然后调用模板来避免重复。也可以尝试用通用模板语言(如Jinja)定义出一个带循环的模板,然后再根据配置调用模板生成代码。
总结
本文讨论了如何在数据平台中进行OneID的实现。介绍了OneID的背景及业界的一些实践。最后,结合一个示例,分析了如何进行OneID实现。
OneID的关联算法算是比较复杂的算法了,在实现过程中,由于涉及的数据量特别大,还常常容易出现性能问题。不过,如果借助Spark的能力,我们将可以深入到细节(比如使用RDD的API)对执行过程进行控制,从而可以从更多方面进行优化。
本文主要给出了大致的实现机制,可以为企业OneID应用提供一个不错的起点。真正落地时,还有很多细节需要结合业务场景、数据量等等进行深入分析。