Previous posts about Easy SQL
People like to use Scala because Scala provides powerful type inference and embraces various programming paradigms. People like to use Python because it’s clean, out-of-the-box, delicate and expressive. People like to use rust because rust provides modern language features and zero-cost abstract.
How to design a neat ETL programming language that people like to use? Let’s have a look at how Easy SQL does. (We will break this topic into two parts. This is the first part.)
Easy SQL defines a few customized syntax on top of SQL to add imperative characteristics.
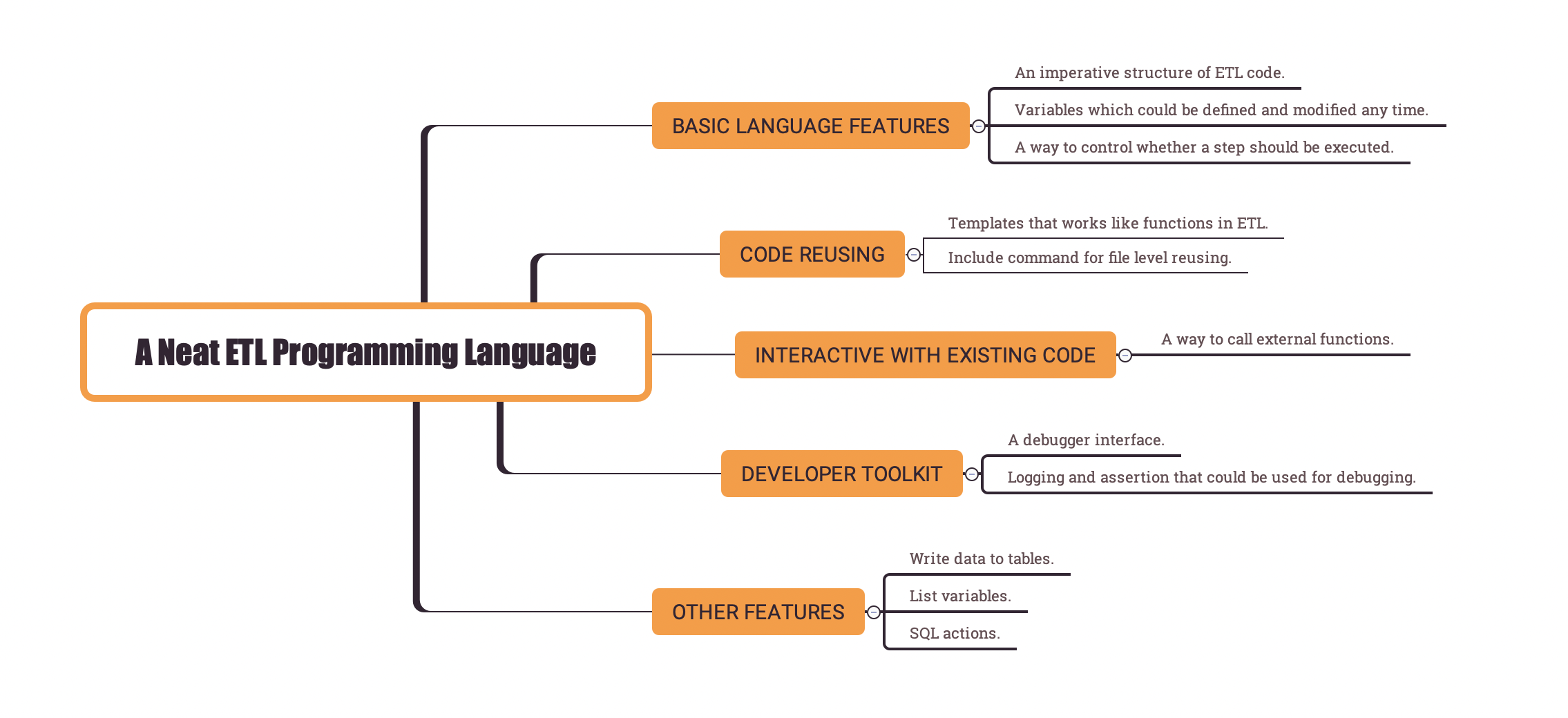
Language features in Easy SQL
For Easy SQL, guided by the design principles, there are a few simple language features added to support these imperative characteristics.
Below is a list of these features:
- An imperative structure of ETL code.
- Variables which could be defined and modified any time.
- A way to call external functions.
- A way to control whether a step should be executed.
- Templates that could be reused in the same ETL file.
- Include command that could be used to reuse code at file level.
- Debugging support: logging and assertion that could be used for debugging.
- A debugger interface.
- Other features:write data to tables; list variables; SQL actions.
Let’s have a look at the first four features.
Syntax in Easy SQL
The imperative structure
The most obvious characteristics of imperative programming is that code will be executed line by line (or piece by piece).
And the declarative way (standard SQL) suggests the opposite, which says, all logic should be defined first and then be executed in one final action.
The major task of designing the imperative structure is to introduce a way to execute SQL step by step.
If we look at Spark DataFrame API, we could find that it works in an imperative way.
For example, we can assign a DataFrame to some variable, then do something about the variable, then transform the variable and assign it to another variable.
In Easy SQL, a simple syntax is introduced as SQL comment, which is target= and -- target=SOME_TARGET in Easy SQL.
There are a few built-in types of targets, which are:
- variables
- temp
- cache
- broadcast
- func
- log
- check
- output
- template
- list_variables
- action
When used in Easy SQL ETL, it looks like below:
1 | -- target=variables |
There is a SQL query under every target statement.
It means the result of the SQL query is saved to the specified target.
Each target could be viewed as a step and will be executed one by one.
The syntax may seem obvious to most of you. If it is so, it means the design goal is achieved.
Let’s spend some time explaining what it does in the simple ETL above.
If you believe you got it already, please skip it.
- The first
targetstatement means the SQL query result,a=1 and b='2'in this case, will be saved to the variables target. After this step, the variables could be used. - The second
targetstatement means that the query from table_a will be saved to a cached table named ‘table_a’. Cache table is a concept borrowed from Spark and it means the query result will be cached and could be reused from the following steps to improve performance. - The third
targetstatement means that the query from table_b will be saved to a temporary table named ‘table_b’. And ‘table_b’ could be used in the following steps. - The forth
targetstatement means that the query from table_c will be saved to a broadcasted table named ‘table_c’. Broadcast table is also a concept borrowed from Spark and it means the table will be broadcasted to every node to improve performance. And the table ‘table_c’ could be used in the following steps too. - The fifth
targetstatement means that the joined query result of the above 3 tables will be saved to an output table named ‘some_table’ in ‘some_db’.
Variables
Variables could be defined and modified at any step. The syntax is as the case above.
If we’d like to modify the value of it, we can just add another variables target and write a query with the result of changed ‘a’ and ‘b’.
A simple example is as below:
1 | -- target=variables |
After the two steps, the value of a will be 2, and it will be 1 for the value of b.
Variables could be referenced anywhere in the following steps with syntax ‘${VAR_NAME}’.
There is a simple example below:
1 | -- target=variables |
When Easy SQL engine reaches the second step, it will do a variable lookup and simply replace the reference with the real value.
It will replace it with the string value of the variable and converts types when required.
The above example will result in variables: a=1, b=2, a1=11, ab=3.
Besides the user-defined variables, there are a few useful system-defined variables.
When we need to implement some complicated functions, we can use them.
Other things to note about variables:
- Variable name must be composed of chars ‘0-9a-zA-Z_’.
- Variable name is case-insensitive.
Temporary tables
Another common case is to save a query to a temporary table for later query. We have already seen a concrete example above.
It works simply as what you expected.
- The query result will be saved to a temporary table if the target is ‘temp’.
- The query result will be saved to a cached temporary table if the target is ‘cache’.
- The query result will be saved to a broadcasted temporary table if the target is ‘broadcast’.
Speaking of implementation, if the backend is Spark, ‘temp’ ‘cache’ and ‘broadcast’ behave the same as that in Spark,
and with a global temporary table created or replaced with the specified name.
For the other backends in which there is no support of caching and broadcasting of temporary tables,
Easy SQL just create views with the specified name in a temporary default database.
Since there is no actual loading of data for temporary tables, to define a temporary table is a very light-weight operation.
You can create as many temporary tables as you wish.
There are a few things to note when creating temporary tables for different backends.
- For Spark backend, the name of the temporary table can be reused, but it cannot be reused for the other backends since we cannot create two database views with the same name in the same default database.
- For BigQuery backend, we have to specify names like
${temp_db}.SOME_TEMP_TABLE_NAMEwhen query the created temporary table. You guessed it, the ‘temp_db’ is a pre-defined variable provided by Easy SQL engine. This limitation is introduced by BigQuery since there is no such concept of a default database (named dataset in BigQuery).
Function calls
Function calls is another feature introduced by Easy SQL. It is used to expand the ability of SQL, so that we could do anything in SQL.
Function is defined in Python code and registered before the execution of the ETL.
The syntax to call a function is very intuitive if you have experience of some other programming languages.
Below is an example of function calls.
1 | -- target=func.plus(1, 1) |
From the ETL code above, we can find a few things about function calls:
- Function calls could be used as a ‘func’ target.
- The result of function calls could be used as a variable.
- Parameters of function calls could be variables.
Besides these, there are a few other things to note:
- One function call expression must be in one line of code.
- When functions are called, all non-variable parameters are passed as strings even if it looks like an integer. In the function implementation, we need to convert types from string to its real type.
- There should be no chars from any of
,()in literal parameters. If there is, we need to define a variable before the function call and pass in the variable as a parameter. - Any user-defined variable will be converted to string and passed to functions as string value. We may need to convert types in the function implementation.
- All functions in the Python
builtinmodule andoperatorsmodule are automatically registered, so we can use a lot of Python functions without providing an implementation.
Before execution of the above ETL, we need to define the functions referenced in the ETL. Followed by the above rules, an example of the function implementations could be:
1 | def plus(a: str, b: str) -> int: |
And then after the execution of the ETL, the value of the variables will be: a=4, b=6.
Control execution flow
For an imperative language, providing a way to control execution flow is important.
Back to the top, there is a case mentioned that
‘we would like to use large computing resources when we’re handling data in the first partition since the amount of data there is far larger than that in the other partitions’.
In order to implement this in ETL, we need to control the execution flow to configure a large computing resource.
A common way in general programming language to handle this is to provide some ‘if’ statement.
And we need to provide a condition expression for ‘if’ statement.
The inner action of ‘if’ statement is then executed according to the true or false value of the condition expression.
Easy SQL provides a similar way to control execution flow.
We can control if a step needs to be executed by providing a ‘if’ statement after any step definition.
Below is an example:
1 | -- target=func.do_some_thing(), if=bool() |
From the example, we know the following things about ‘if’ statement in Easy SQL:
- There must be a function call following the ‘if’ statement.
- The function call must return a boolean value to indicate if the step needs to be executed.
- Any step could be controlled by a ‘if’ statement, including ‘func’ ‘temp’ ‘variables’ and so on.
Summary
In this post, we talked about the first 4 language features.
- An imperative structure of ETL code.
- Variables which could be defined and modified any time.
- A way to call external functions.
- A way to control whether a step should be executed.
For the other features, let’s talk about it in a post later on.
You may already find it useful and would like to have a try. You can get all the information required to get started from the GitHub repo here and the docs here.
If you find any issues, you’re welcome to raise it in GitHub Issues and PRs are welcomed as well!