在数据进入到数据平台之后,我们就可以正式开始构建数据应用了。一个常见的数据应用是数据报表和数据指标的开发。如何开发这样的数据应用呢?首先要决定的就是使用什么样的开发语言及如何构建开发环境。本文将结合我们的实践经验一起聊一聊这个话题。
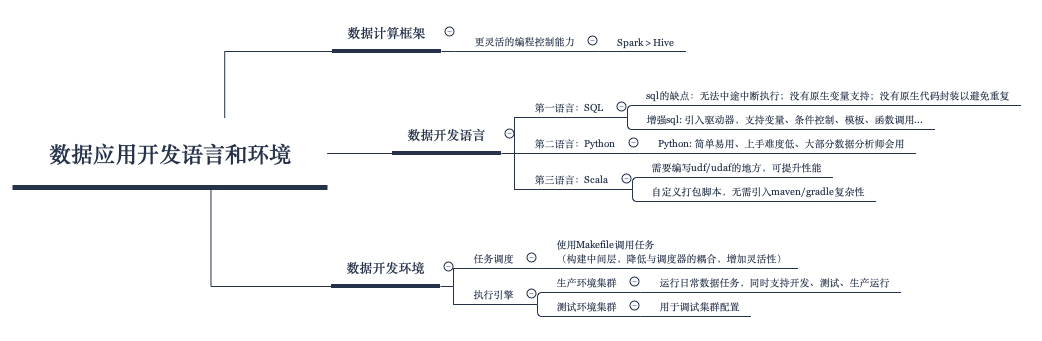
数据计算框架
在基于Hadoop的分布式数据平台的场景下,当前最流行的数据计算框架要算Spark了,相比Hive,它提供了更为可控的也更灵活的编程过程。根据需要,我们可以在Spark程序中随时获取到某一个计算结果,然后根据此结果进行后续计算,而Hive要想要实现这样的灵活性,可能不得不借助临时表或其他语言来充当驱动器程序了。
同时,由于Spark在设计之初就声明了兼容Hive,所以,我们完全可以把Spark和Hive联合起来使用。Hive用于在数据分析时随时执行sql查询,Spark用于将数据计算任务工程化。
我们在前面的文章中提到了数据仓库DWD层的构建,这一层的构建就可以通过Spark来实现。Spark同时提供了编程的DataFrame接口和sql接口,支持Java、Scala、Python、R等编程语言。
数据开发语言
应该选择什么样的接口进行数据开发呢?我们会建议主要使用sql而不是基于DataFrame的API,主要理由是:
sql是数据分析的通用语言,团队大部分人可以看懂sql,而要看懂Scala或Python代码则需要具备更多的编程知识DataFrameAPI可以和sql语法对应,使用sql也不会过多丢失DataFrameAPI的灵活性sql是独立于计算引擎存在的,如果以后希望替换计算引擎,可以更容易实现(比如,Presto是查询性能更好的一个OLAP引擎,将来可以考虑替换底层计算引擎为为Presto)
sql的缺点及应对
很多人会吐槽sql开发的缺点。究其原因,是由于sql是声明式的语言,需要先定义再执行,且执行过程不能中断。这样一来,直接使用原生的sql来编写复杂代码可能会十分不便。比如以下这些场景。
考虑需要进行流程控制的场景。比如,在数据量很大的情况下,一般需要调整分区数才可以更高效的并行执行。此时,我们需要在执行sql之前先判断数据量。如果直接用sql,这一过程将不容易实现。如果依赖调度工具进行这种流程判断又显得大材小用。
考虑需要使用变量的场景。比如,我们需要根据指定的日期进行指标计算。如果直接使用sql,我们可能要考虑先将此日期写入到一张临时数据表中,十分不便。
考虑需要重复多次的代码。比如,在空调销售的场景,我们需要同时按日计算销量指标,也需要按月计算销量指标(考虑到取消订单的情况,两者无累加关系,需要单独实现),这两个指标的大部分逻辑是相同的。使用原生的sql,将难以复用这些相同的计算逻辑。
如何应对上面这些问题呢?相信大家心里已经有答案了,那就是进行sql语言的增强。其实,我们只需要实现一个简单的sql执行器就可以解决上提到的大部分问题。
增强sql语法
针对上面的三个场景,我们可以为sql语言添加这些特性:变量、控制语句、模板。
这样增强后的sql可以编写成什么样子呢?采用TDD的思路,我们可以先写个测试,通过编写测试来辅助设计我们所期望的增强sql的使用方式。
考虑支持变量和控制语句,这样的测试sql可以编写如下:
1 | -- target=variables |
针对上面的增强sql语法实现一个驱动器程序应当不是难事。以下是驱动器实现的大致思路:
- 匹配字符串
-- target=,根据不同的值,执行不同的操作,如果target有if条件,则判断其取值,如果为false则跳过此步骤 - 如果当前
target为variables,驱动器应该执行sql,并将结果集保存为一个字典,作为后续代码的变量上下文 - 如果是
temp.xxx,替换sql中的变量,执行sql,将结果保存到名为xxx的tempview中 - 如果是
hive.xxdb.xxtable,替换sql中的变量,执行sql,将结果保存到名为xxtable的Hive数据xxdb中
模板可以很好的解决代码重复问题,如何支持模板呢?可以编写一个测试sql如下:
1 | -- target=template.a |
支持上述测试的驱动器实现的大致思路是:
- 匹配字符串
-- target=,根据不同的值,调用不同的函数 - 如果是
template.xxx,将内容保存下来,作为后续代码的模板上下文 - 对于其他类型的
target,比如hive或temp,执行sql之前先进行模板替换
(上面的测试用例只是覆盖了很小的一部分正常场景,要实现一个完整的驱动器,还需要定义更多的边界场景)
有了这个驱动器,相信前面提到的sql的缺点就不再是缺点了。这个增强版本的sql可以应对大部分的场景。在我们的实践过程中,还增加了一些其他的有用的特性,比如:
- 支持在变量中进行
Python函数调用,以便可以扩展任意复杂的逻辑 - 支持
target值为func.a(arg1, arg2, ...),当发现此类语法时,不执行sql,而是调用这个函数,这可以很容易的将Spark中的一些有用的函数暴露出来 - 支持在模板中定义参数和引用变量
第二语言
在决定使用sql作为第一语言之后,我们还需要考虑数据开发的第二语言。比如上述sql驱动器应该选择什么语言来实现呢?
Spark支持得最好的语言是Scala和Python。Spark本身是使用Scala开发而成,所以二者有着无缝的互操作性。Python拥有庞大的数据分析师用户群体,为支持大规模数据分析而设计的Spark自然要好好支持Python。
在项目中,我们优先选择了Python语言,主要的理由是:
Python简单易用,无需像Scala一样需要配置复杂的开发环境- 依赖包管理更容易实现,如果使用
Scala,则常常需要解决Java的依赖包冲突问题(大数据环境下的依赖Jar包太多了) Python上手难度更低,Scala有着较高的学习成本- 数据分析师很容易看懂
Python代码,团队对代码的熟悉程度更高
当然是用Python也有其缺点,比如:
- 性能相对更差,因为
Python程序会启动Java进程来运行Spark代码 - 一些由
Java进程抛出的错误不容易理解,也难以对Java代码中进行断点调试 - 为了能正常运行某些程序,有时需要在所有节点安装
Python依赖包
相对而言,我们认为Python还是做数据开发的更好的选择。
当然,我们也拥抱Scala语言,一些udf的实现我们会建议使用Scala,主要的考虑是性能更好(无需在两种语言中进行数据的序列化和反序列化)。
通过udf/udaf扩展sql
另一个扩展sql语法的方式是udf,即自定义函数。
要编写一个Spark的自定义函数是非常简单的。如果代码逻辑比较简单,可能只需要一行代码即可。比如,假设我们要实现一个函数将两个数值相乘,只需要编写Scala代码spark.udf.register("multi", udf((a: Double, b: Double) => a * b))。得益于Scala具备强大的类型系统及类型推断能力,这里的代码才可以如此简洁。
除了udf,Spark还支持udaf扩展,即自定义聚合函数(在Group By聚合统计的场景下使用)。实现自定义聚合函数时,需要略微费事一点。大体上,需要实现reduce函数,把多个值聚合为一个值,然后实现merge函数,将多个reduce的结果合并为一个。
由于我们可以轻易的实现自定义函数和自定义聚合函数,因此,我们可以更多的借助udf/udaf的能力,把一些通用的计算通过udf/udaf进行封装和抽象。从而使得我们的sql代码更为简洁清晰。
前面提到了我们的第二开发语言是Python,那么Scala可以作为我们的第三开发语言,专门用来开发udf/udaf。在这种场景下使用Scala可以很好的提升程序性能,我们将从中获得很多益处。但是Scala程序的开发环境和依赖管理问题依然是比较麻烦的,如何缓解这个问题呢?
我们建立了这样几个原则:
- 一般情况下,只允许引用
Spark及其相关的依赖 - 由于
Scala代码并不多,不在团队中统一使用IDE来支持开发,而是通过编写shell脚本来实现Scala代码的编译和打包 - 通过
Web IDE来支持开发中的语法诊断、代码调试等 - 在
Python代码中将udf/udaf注册到Spark,通过在Python的测试用例中测试Sql来达到测试udf/udaf的目的
有了这样的原则,我们可以很好的享受到Scala代码带来的好处,同时可以避免Scala带来的工程管理复杂度。
实现Scala代码的编译和打包的shell脚本可以参考如下:
1 | SPARK_JAR_PATH=/usr/local/lib/python3.8/site-packages/pyspark/jars/* |
构建开发环境
任务调度器
一个大的数据应用常常会被拆分为很多小的独立的数据计算任务,比如一张报表,里面的每个指标的计算可能对应一个的任务。我们需要一个调度器将这些任务按照依赖关系周期性的调度运行。这些调度任务一般可以组成一个有向无环图,即DAG,我们也把这样的图称作数据流水线。
当前可以使用的开源调度器种类很多,比如Airflow,作为Airbnb开源的任务调度系统,由于其可以使用代码来定义数据流水线且与其他开源生态有很好的集成而深受广大开发者喜爱。
使用Makefile实现任务管理
如何将任务集成到调度系统里面呢?一般可以使用Shell命令将任务集成到调度系统。我们会建议使用Makefile先进行一层任务封装,然后再使用Shell命令集成到调度系统。相比直接使用Shell命令进行集成,这一实践有以下几个优势:
Makefile有任务的概念,可以将要执行的命令组合成一个一个功能更强大的任务,Shell则只能自己编写代码实现Makefile的任务中任意一行命令运行失败将导致任务失败,这使得我们可以更早的感知到失败,从而更早的进行修复,Shell则无此特性Makefile原生就可以在执行中把运行的命令打印出来,从而便于我们诊断问题,Shell则需要手动进行配置
除此之外,Makefile作为c/c++的构建工具,使用非常广泛,与Shell一样非常轻量级,容易获取和安装。这使得我们使用Makefile成本很低。
大多数调度系统都提供了除Shell外的其他编程语言的集成,比如Airflow提供了Python代码的集成方式。但我们并不建议使用这一方式进行集成,主要理由是:
- 增加了调度系统和计算任务之间的耦合性,这会带来一些不便,比如,如果要修改任务参数配置,则需要修改流水线才能实现
- 丢失了中间层的灵活性,比如,如果是
Makefile,我们的任务可以随时在Shell中运行,无需依赖任何的调度系统(在调试代码时,这将非常便利) - 降低了对调度系统的依赖,这使得调度器在需要时可以很容易的被替换(一般而言,我们可以将大部分参数配置放到
Makefile这样的中间层,和调度系统的集成部分将会更少)
构建任务运行环境
Spark程序需要运行在一个支持环境中,随之而来的一个问题就是,我们需要几套环境来支持数据开发、测试及上线运行?
由于分布式环境的构建和管理维护并不是一件容易的事,且常常需要较高的成本投入,我们并不建议去搭建多套集群。当然,如果企业内部有独立的运维团队负责集群的日常管理,那情况会不一样,我们可以根据需要来选择使用几套环境。
在我们看来,一般使用两套集群就可以足够满足数据项目的推进了。一套是用于进行集群配置测试的,可以称为测试环境。另一套用于运行日常的数据任务,同时支持数据开发、测试及生产运行(周期性调度运行),可以称作生产环境。
测试环境可以应对很多集群配置调整的问题,我们可以先在测试环境中从容的进行集群配置的调整和测试,在修改好了之后,再将配置迁移到生产环境。
有人可能会担心一套环境同时用于支持开发、测试及生产运行会带来问题。比如数据的隔离性,数据的安全性,对生产运行的任务的稳定性造成影响等。但是,事实上,集群已经提供了很多的功能来帮助我们解决这个问题。比如:
- 基于
Hive的数据仓库,可以建立开发和测试用的数据库,数据生成到这些数据库中,从而更好的与生产运行的数据进行隔离 - 基于
Hive的数据仓库,通过配置权限,可以使得以开发人员的账号运行的任务无法将数据写入到生产运行的数据库,这也实现了与生产运行的数据进行隔离 - 基于
Hive的数据仓库,通过配置权限,可以使得开发人员的账号只能访问到非敏感数据,比如,可以禁止读取某些列,对另一些列用hash处理等 - 基于
Hadoop的分布式计算环境本身就提供了基于队列的任务调度管理。可以设计一个占用资源更少优先级更低的队列供开发测试使用,从而避免对生产运行的任务的稳定性造成影响
使用一套集群同时支持开发、测试及生产运行还有以下好处:
- 无需花费额外的集群管理成本(这常常会花费团队大量的精力,而体现的价值却很有限)。
- 无需进行集群间数据同步和迁移(或测试数据构造),开发和测试可以直接使用生产数据,降低了成本,也提高了效率(如果担心数据量太大的问题,可以在开发测试过程中事先对数据进行抽样;如果担心数据安全问题,可以对开发和测试人员账号配置数据脱敏)。
- 可以更容易的在开发和测试中发现真实数据中的边界场景,从而编写逻辑更完善的程序。
- 更重要的是,使用一套集群可以提前发现数据任务中的运行性能问题,这些问题通常难以解决,需要花费大量的时间。提前暴露这样的问题,让我们可以更早的去应对风险,不至于生产运行时发现问题导致手足无措。
总结
本文讨论了在数据应用开发开始之前需要进行的工作,包括进行编程语言的选择和开发环境的构建。这两方面的相关决策将在很大程度上影响后续数据开发的组织和管理。如果决策得当,后续数据开发将能够很轻松的开展起来,否则,则可能将团队带入泥潭。
本文分享了我们在实践过程中的一些思考和选择,这些经验对于我们是很受用的。总结起来,就是:
- 尽量首选
sql进行数据开发,其次选择Python,再次Scala - 扩展
sql语法,增强其功能以应对复杂的计算逻辑 - 使用
Makefile与调度系统进行集成 - 不要构建太多集群环境