Previous posts about Easy SQL
- A new ETL language – Easy SQL
- A guide to write elegant ETL
- Neat syntax design of an ETL language (part 1)
People like to use Scala because Scala provides powerful type inference and embraces various programming paradigms. People like to use Python because it’s clean, out-of-the-box, delicate and expressive. People like to use rust because rust provides modern language features and zero-cost abstract.
How to design a neat ETL programming language that people like to use? Let’s have a look at how Easy SQL does. (This topic is broken into two parts. This is the second part.)
Easy SQL defines a few customized syntax on top of SQL to add imperative characteristics.
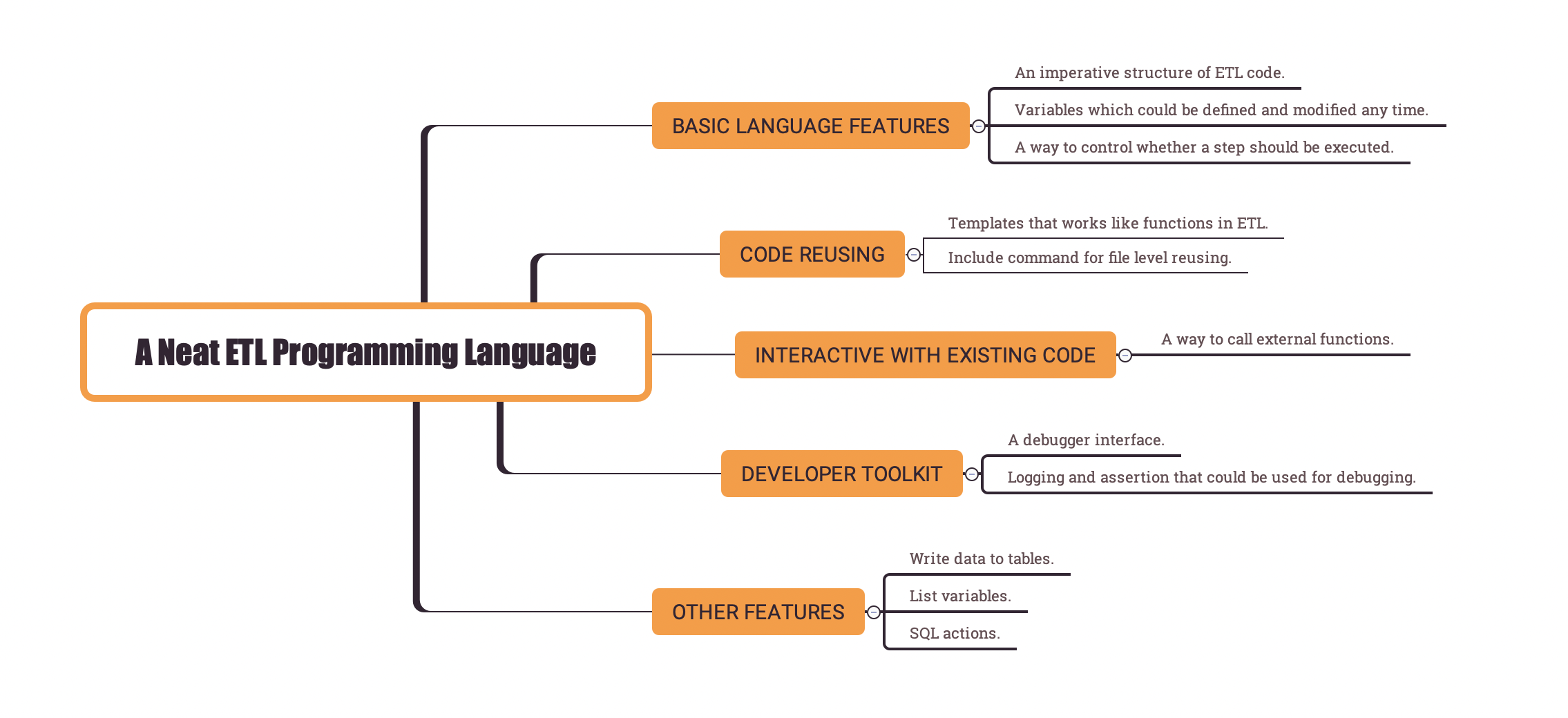
Language features in Easy SQL
For Easy SQL, guided by the design principles, there are a few simple language features added to support these imperative characteristics.
Below is a list of these features:
- An imperative structure of ETL code.
- Variables which could be defined and modified any time.
- A way to call external functions.
- A way to control whether a step should be executed.
- Templates that could be reused in the same ETL file.
- Include command that could be used to reuse code at file level.
- Debugging support: logging and assertion that could be used for debugging.
- A debugger interface.
- Other features:write data to tables; list variables; SQL actions.
Let’s have a look at the last five features.
Syntax in Easy SQL
Templates used to reuse code
To support reusing of code, templates have been introduced in Easy SQL.
Templates are similar to functions in general programming languages.
Functions could be called anywhere while templates could be used anywhere as well. This way, code is reused.
Just like functions, there are name, parameters and body for a template as well.
Below is a concrete example of templates:
1 | -- target=template.dim_cols |
There are two templates named ‘dim_cols’ and ‘join_conditions’ defined.
One with no parameters and one with one parameter named ‘right_table’.
This example is about a very common case when we’d like to merge two tables with the same dimension columns.
After the template is used, the dimension column names and join conditions are reused, just like how we reuse functions in general programming language.
From the example above, we could find a few things to note about templates:
- Template is a step in ETL. It is defined by a target with name ‘template’ and a following descriptive name. The descriptive name is the template name.
- The body of a template could be anything.
- If there are template parameters, no need to declare them, just use them by ‘#{PARAMETER_NAME}’. Easy SQL will extract these parameters for you at runtime.
- Templates could be used in any target with syntax ‘@{TEMPLATE_NAME}’. If there are template parameters, we need to pass them as named parameters.
Besides, there are some other notes:
- Variables can be referenced in template body, and the resolution of variables happens at the resolution time of the template (when the step with template reference is executing). This is useful since we can change the value of some variable between two targets referencing the same template.
- There should be no templates used in the body of templates. This is to make the resolution of templates to be simple.
Include other ETL code snippets
Template is designed for reusing code within one ETL. How to reuse code across ETLs?
One common way to reuse code is to create a temporary mid-table.
But it seems heavy since we need to create a real table and there might be data copying.
Easy SQL provides a way to reuse code from some other ETL file. This is the ‘include’ command.
Include looks similar to target. Below is an example:
1 | -- include=snippets/some_snippet.sql |
The file path is a path relative to the current working directory.
When Easy SQL processed the ‘include’ command, the content of the file will be expanded.
The result will be the same as when we write code in here directly.
For the example above, if we have the following content in some_snippets.sql:
1 | -- target=temp.some_table |
Then the content of the ETL will be the same as the content of some_snippets.sql since there is only one include command there.
Notes about ‘include’ command:
- Include command could be used at any line of code.
- When Easy SQL processed this ‘include’ command, the content of the file will simply be expanded.
Debugging support
In a complicated ETL, it is easy to introduce bugs.
A general programming language usually provides some ways to help with debugging.
The most commonly used way is about logging and assertion.
Developers can log variables anywhere to provide information about the executing step.
They can also set an assertion if there is any important assumption made in the following code.
To do logging and assertion in Python, the code looks like below:
1 | logger.info(f'some thing happened, check the variables: var_a={var_a}') |
Easy SQL provides a similar way to do logging and assertion. They’re both provided by a type of target.
Check the example below to see its usage.
1 | -- target=log.i_would_like_to_log_something |
From the example above, we know that:
- When using the ‘log’ target, we need to specify a message about what to log.
- The log message format is the same as a variable. I.e. It should be composed of chars ‘0-9a-zA-Z_’.
- There should be exactly one row returned from the query of some ‘log’ target. If there is more than one row returned, only the first row will be logged.
- There are two formats of ‘check’ target. One is to specify a check message with a query. The other is to call a function, which returns a boolean value.
- When the ‘check’ target is used as a message with a query, the returned value of the query must be one row with two columns named ‘actual’ and ‘expected’.
Debugger interface
There is a debugger interface provided by Easy SQL. It could be used with Jupyter to debug interactively. Follow the steps below to start debugging.
- Install
Jupyterfirst with commandpip install jupyterlab. - Create a file named
debugger.pywith contents like below:
(A more detailed sample could be found here.)
1 | from typing import Dict, Any |
- Create a file named
test.sqlwith contents as here. - Then start jupyter lab with command:
jupyter lab. - Start debugging like below:
For details of the APIs, we can refer to API doc here.
Write data
If we need to write data to some table, we could use another type of target. The name of the target is ‘output’.
There should be a query statement following the ‘output’ target. And the result of the query will be written to the output table.
Below is an example:
1 | -- target=temp.result |
After the execution of the ETL above, there will be one row written to table ‘some_db.some_table’.
Things to note about ‘output’ target:
- There must be a full table name (both database name and table name specified) after the ‘output’ keyword in the target definition.
- The table must be created before writing data.
- If we’d like to create tables automatically, we need to define a special variable named ‘__create_output_table__’ with value equals to 1.
- If we’d like to write data to some static partition of the output table, we need to define a special variable named ‘__partition__’ with partition column name followed by. An example could be ‘__partition__data_date’. Then the partition column is ‘data_date’. The value of the variable will be the partition value when writing data.
- If we’d like to write data to some static partition of the output table, we can only define one partition value at the moment.
- If the query returns more columns than what is defined by the real table, the extra columns will be ignored.
- If the query returns less columns than what is defined by the real table, an error will be raised.
List variables
There are list variables supported in Easy SQL as well.
List variables are different from variables mentioned previously.
The main difference is that the values of these variables are lists.
So that list variables could not be used in SQL statements, since we cannot simply convert a list to a string and do variable resolution.
List variables can only be used as function parameters right now.
Below is an example of list variables.
1 |
|
If we have function implementation like below:
1 | def print_list_variables(a: List[str]): |
Then the function output will be: [1, 2, 3]
SQL actions
There are some cases where we’d like to just execute some SQL statement without anything to do about its result. We can use ‘action’ in these cases.
This usually happens when we want to execute some DDL statement. Examples would be like to create table, to drop partition of some table etc.
Action is a type of target as well and it follows target syntax. Below is an example of ‘action’ target:
1 | -- target=action.create_some_table |
Things to note about actions:
- There should be a descriptive name for an action. The name should be composed of chars ‘0-9a-zA-Z_’ and follow the ‘action’ keyword.
- In the body of an action target, templates and variables can be used as in any other target.
Summary
In this post, we talked about the last five language features.
- Templates that could be reused in the same ETL file.
- Include command that could be used to reuse code at file level.
- Debugging support: logging and assertion that could be used for debugging.
- A debugger interface.
- Other features:write data to tables; list variables; SQL actions.
Now we have finished all the language features provided by Easy SQL. But there are a lot more useful features in Easy SQL for us to find out.
You may already find it useful and would like to have a try. You can get all the information required to get started from the GitHub repo here and the docs here.
If you find any issues, you’re welcome to raise it in GitHub Issues and PRs are welcomed as well!