今天给大家分享一下,在网络规模越来越大时,我们会遇到什么问题,以及如何使用tensorflow来应对。下面将会给大家分享一些有用的tips。
大规模网络的特征
首先我们来看一下用什么来衡量网络规模。
下图是alexnet的网络结构图,在2012年的imagenet图像分类挑战中,alexnet取得了80.2%的top-5正确率。
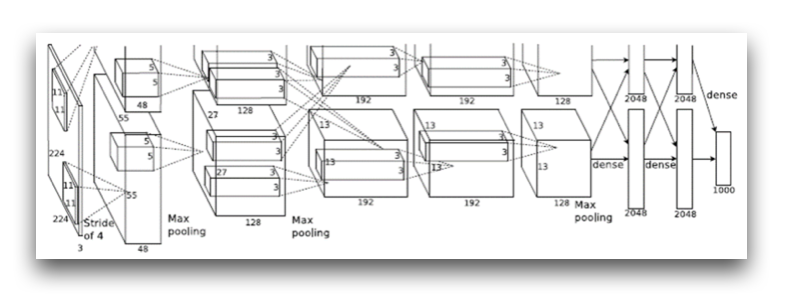
从图中可以看到网络一共分为8层,5个卷积层,3个全连接层。对比lenet的5层网络,可以发现alexnet在网络的深度上面表现为更深,实际上在imagenet挑战中性能更好的Incepiton模型网络层数更是达到了数十层。从这里我们可以看到随着网络规模的扩大,网络的层数在增加。
另一方面是网络结构的复杂度上,之前的网络从下到上逐层递进,演进为多分支的结构。
另外,神经元的个数也是网络的重要特征,大规模的网络通常参数个数也越多。AlexNet和Inception模型的网络参数就达到了上千万,VGGNet更是达到了上亿的参数个数。当然这相比人类的800亿级的神经元个数还是差几个数量级。
为了更高的精确度,我们通常需要规模更大的网络,那么在网络规模逐渐扩大的过程中,我们会遇到的主要挑战是什么呢?其实主要有两个:一是训练数据量越来越大,二是训练时间越来越长。我们下面就来看看如何使用tensorflow来应对这些问题。我们会介绍一些很有用的tips。
训练大规模网络的技巧
队列及多线程
试想一下,如果用于训练的数据量达到了100G,我们应该如何来应对呢?一个基本的想法就是我们可以把元数据读入到内存,真实的数据放磁盘,元数据通常很小,容易处理,而真实的数据,如图片,比较大,放磁盘上等需要的时候再读取。
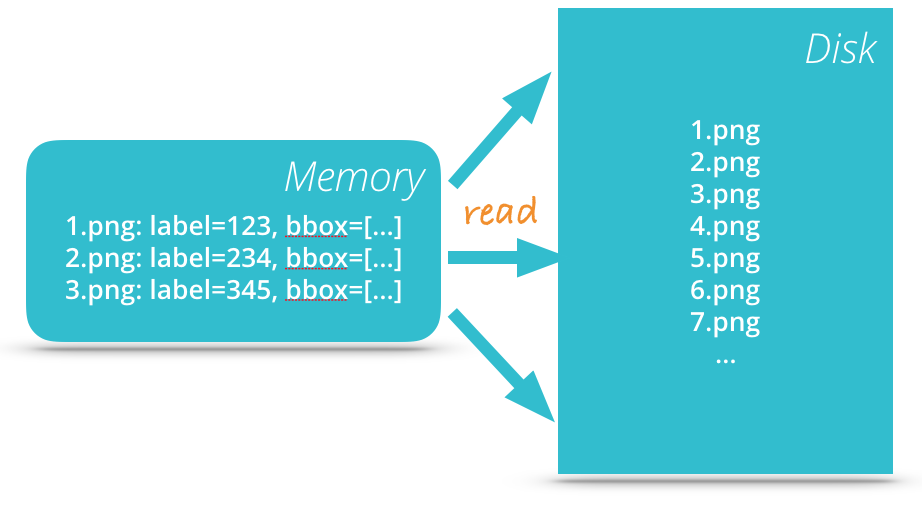
Tensorflow给我们提供了三种方法来输入训练数据。一是我们可以直接把数据全部读入到内存,然后使用这些数据进行训练;二是feeding的机制,就是每次迭代的时候把数据作为输入喂给模型,这种机制是可以解决我们的问题的,但是我们得自己编写代码来处理数据load的过程;第三种我们可以使用的机制就是队列,使用队列我们就可以很容易的实现上面的模型,因为tensorflow已经有实现好的代码可以让我们在需要的时候才读取数据。
在tensorflow里面,队列也是一个普通的操作,跟其他的操作一样,出队操作会返回一个tensor,然后就可以使用这个tensor进行后续的处理了。
请看这个gif图来理解tensorflow中的队列是如何工作的(来自tensorflow官网):

在构造图的过程中,我们构造了一个队列,以及4个节点分别处理入队、出队、递增、入队操作。通过gif图,我们可以看到在计算图运行的过程中队列里面的数据是如何变化的。
下面的图更清晰的演示了之前我们讨论的模型(来自tensorflow官网):
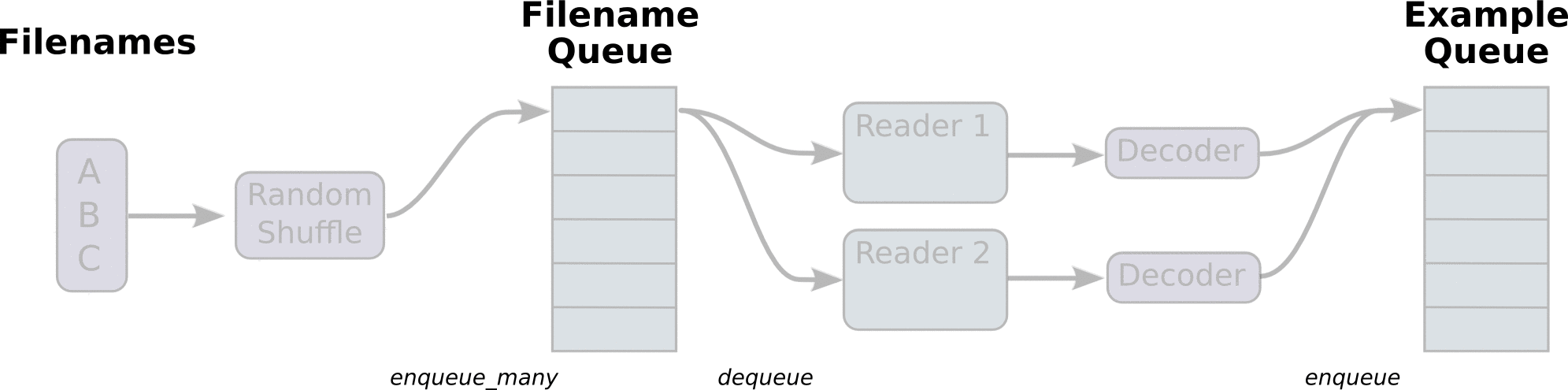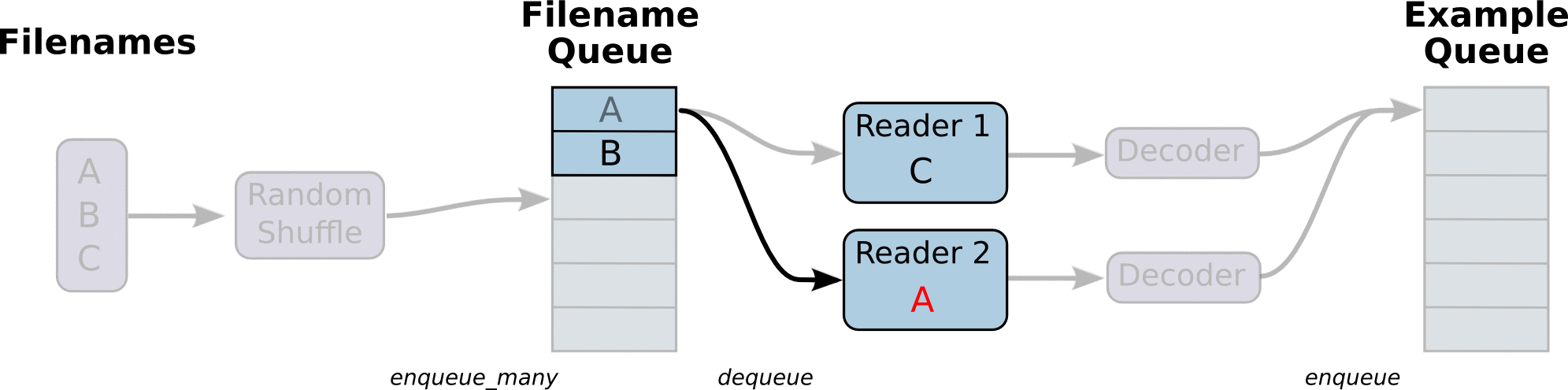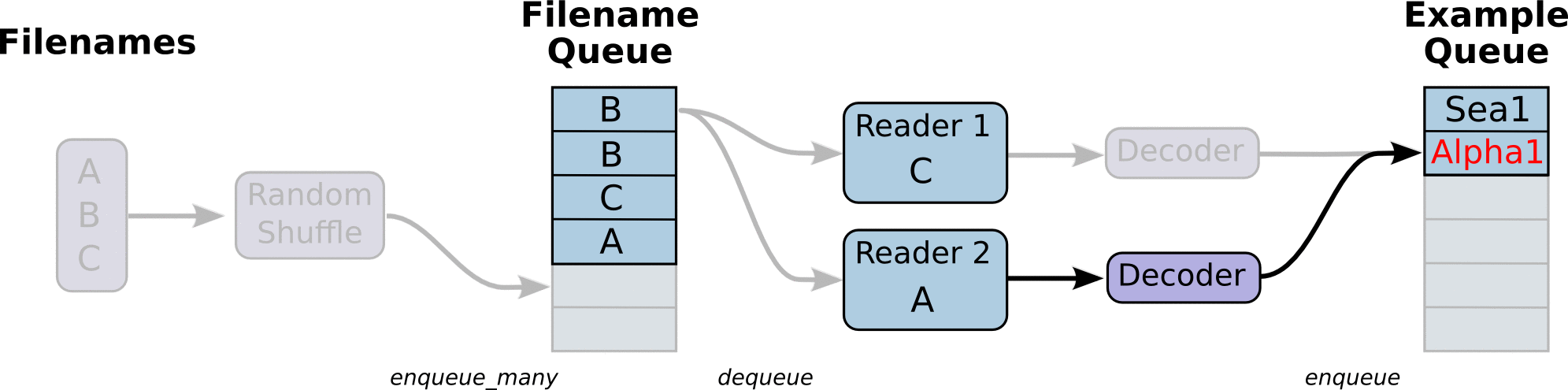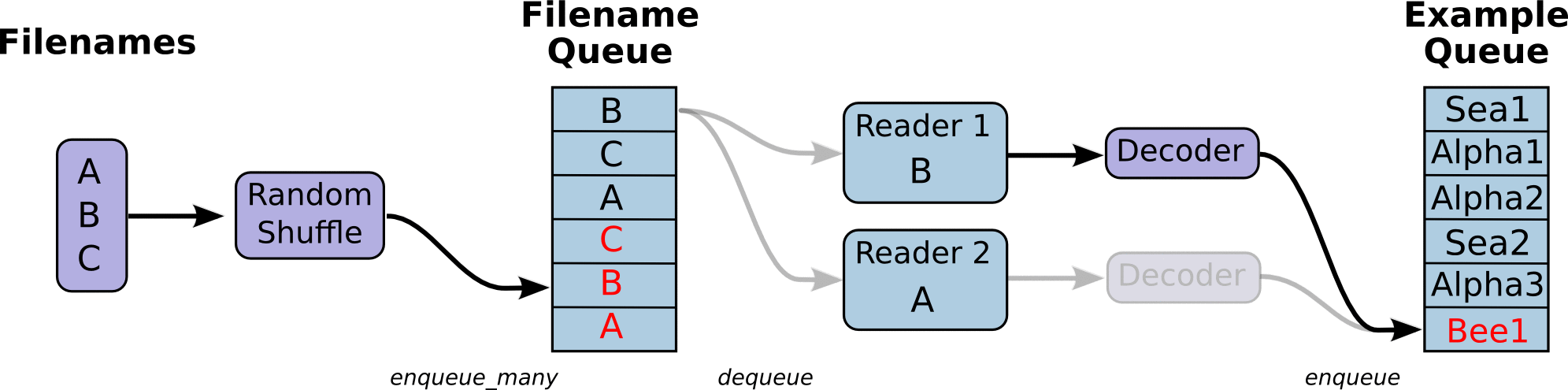
可以看到,我们有一个文件名的队列,里面存储了所有训练数据的文件名,即训练数据的元数据。然后多个reader并行从队列中读取数据并交给后面的decoder进行解码和预处理。之后再将解码后的数据输入到另一个队列中作为我们的训练数据队列。
创建一个包含队列的图的代码模板如下(来自tensorflow官网):
1 | example = ...ops to create one example... |
运行此图的代码如下(来自tensorflow官网):
1 | # Create a queue runner that will run 4 threads in parallel to enqueue |
分离训练和验证过程
第二个我们要一起来看的问题的是关于验证过程的。一般而言,在训练的同时,我们会想要同时验证模型的训练效果,以便知道模型的性能变化情况。但如果把验证过程和训练过程放到一张图里面进行运行,通常会导致训练的中断和训练时间延长。
一个基本的思路就是,我们能不能让验证过程在单独的进程里面运行,这样就不会影响模型的训练过程了。为实现这一想法,我们可以考虑使用tensorflow提供的saver将模型定期保存到磁盘中,然后运行另一个进程来读取最新的模型进行模型验证。如果你只有一台机器来运行机器学习模型,独立进程的模式可以让我们把模型的训练过程放到gpu上运行,将验证过程放到cpu上运行,这样就可以最大化机器使用了。如果你有更多的机器,你甚至可以将验证过程和训练过程运行在不同的机器上面。
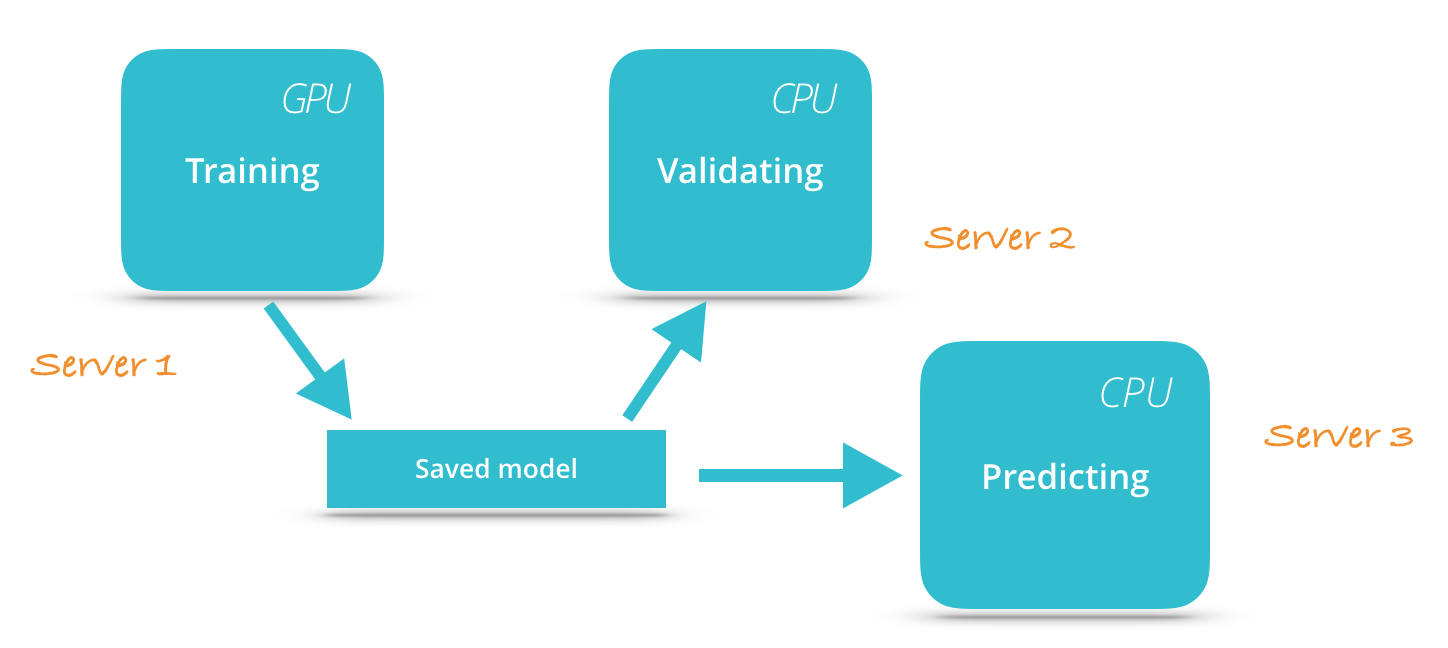
分布式执行
在训练大规模网络的时候,一个有效提高效率的办法就是分布式执行。在tensorflow中是如何支持分布式执行的呢?
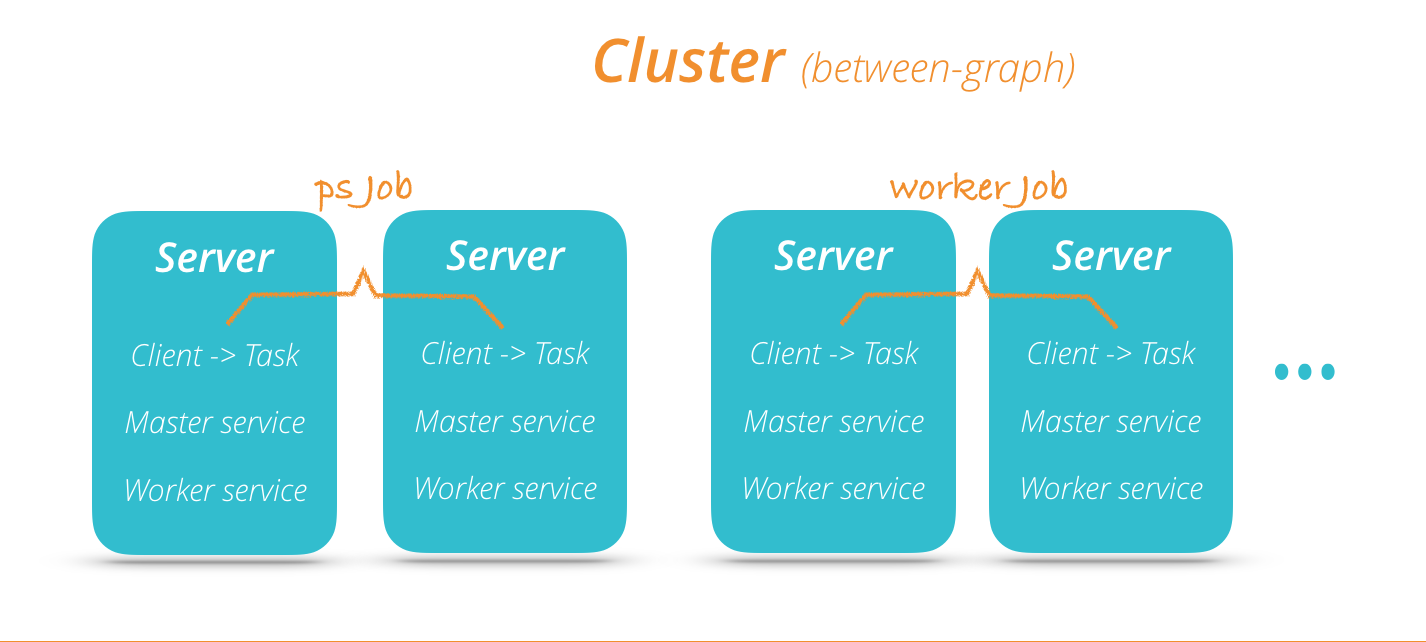
上图可以看出使用tensorflow的分布式模型是按照server进行组织的。tensorflow分布式模型中有几个概念比较重要。
- Server: 一般server会运行在一个独立的服务器上作为一个进程提供服务
- Worker Service: 一个Worker Service用于执行一个图的一部分
- Master Service: 负责协调Worker Service
- Task: 一个Task对应一个Server,属于某一个Job
- Job: 由一组Task构成,用于提供一些公共的服务,如在图中的参数服务PS Job,以及无状态的Worker Job
在构造一个集群环境时,我们需要先根据配置构造一个ClusterSpec对象,用于提供集群信息。然后新建一个Server对象,并根据当前的job的类型来决定做什么。如果是参数服务,就什么都不用做,如果是工作服务就构造一个图来执行。
示例代码如下(来自tensorflow官网):
1 | import tensorflow as tf |
使用现成的模型
在开发机器学习的模型时,另一个有意思的问题是,我们能否基于已有的已经表现比较好的模型进行训练呢?如果可以,那么这样的办法将能非常有效的缩短训练时间,并提升模型效果。事实上这也是可以实现的,但是有一些条件。
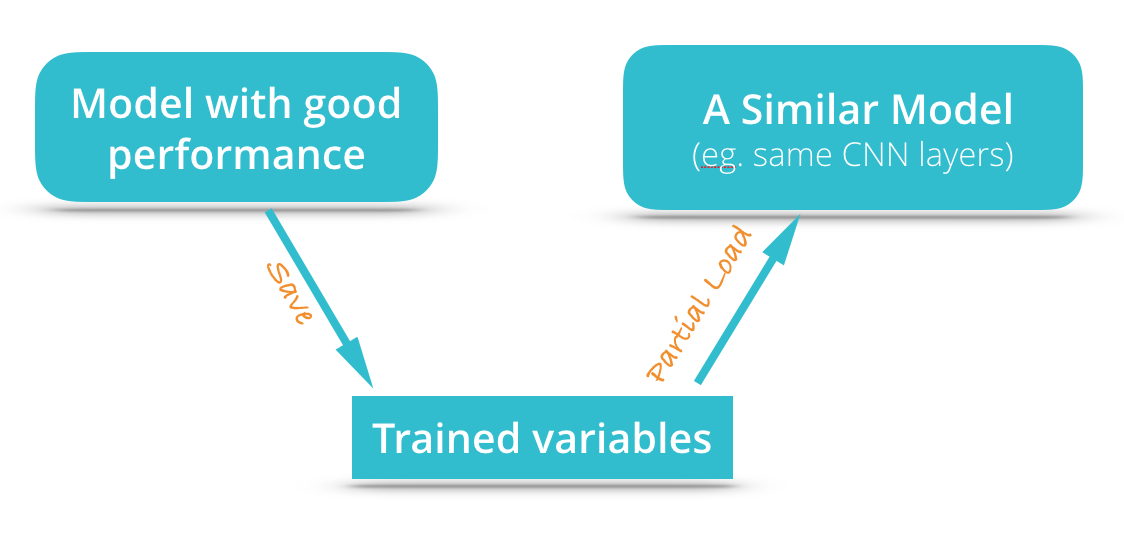
由于模型存储时,实际上存储的是模型的所有参数,既然如此,想要在已有的模型上面训练,我们就必须把模型的一部分实现为跟原来模型的一部分是一样的,否则将无法使用这些参数。
下面我们来看一个例子,这个例子来自于tensorflow的models项目,是基于论文【Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge】实现的。这个模型可以根据图片来生成标题。这个模型的训练就是使用现成的模型来进行的。它的模型图如下:
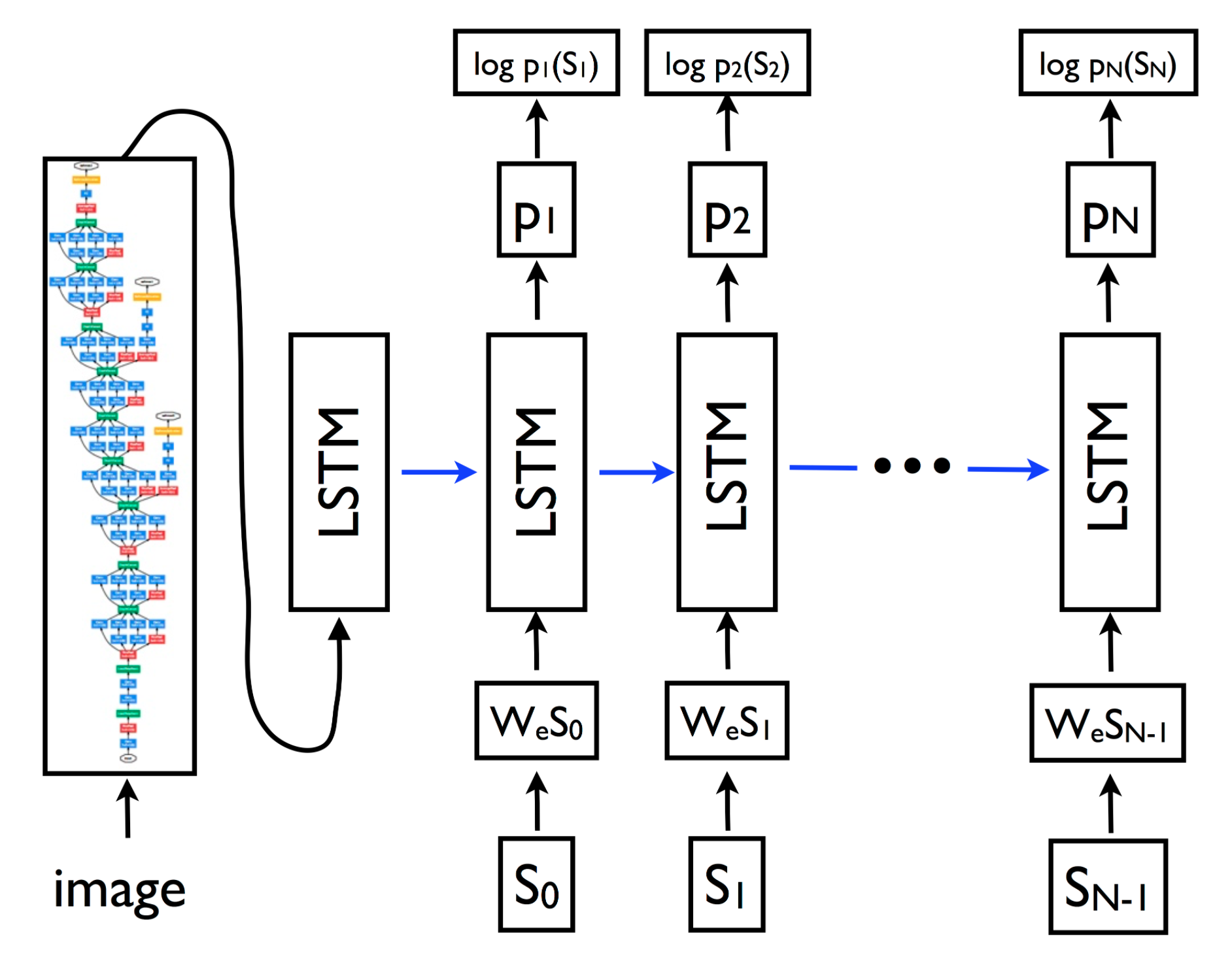
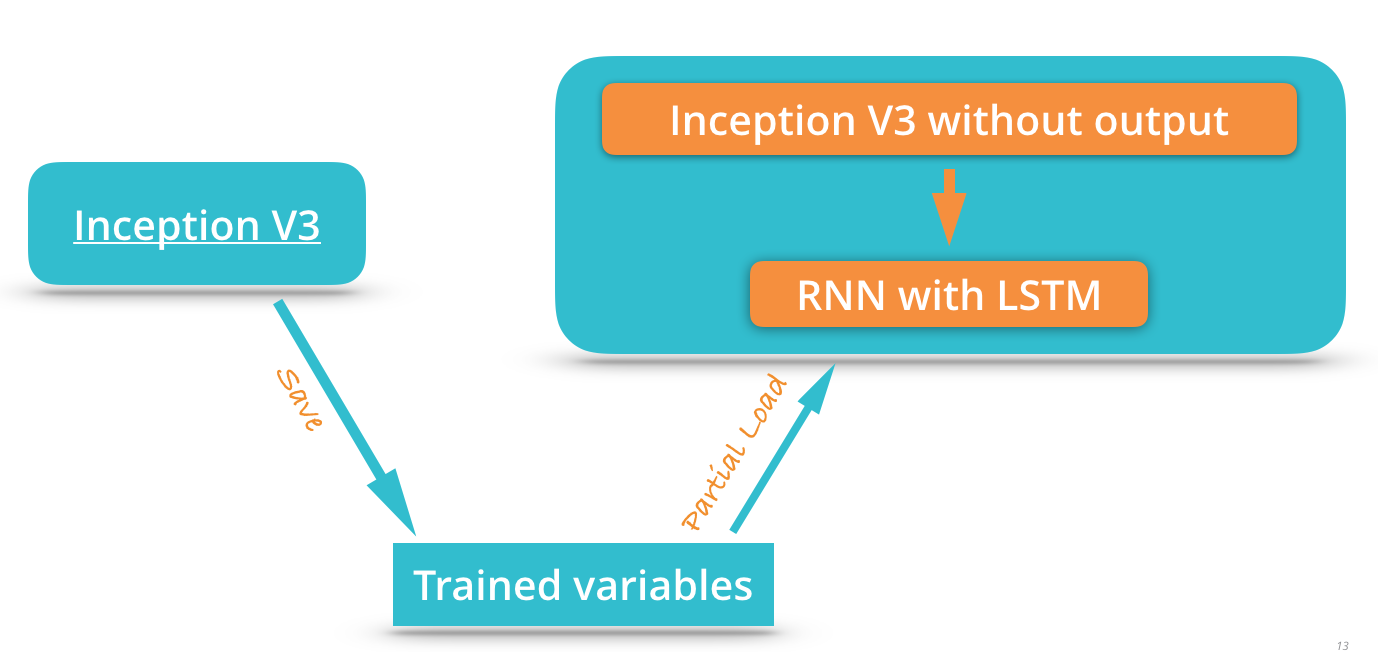
可以看到这个模型是基于Inception模型来实现的,它实际上是将Inception模型的输出层去掉,然后将模型的输出作为一个RNN模型的输入来构造计算图的。这个模型在训练的时候会读取已经训练好的Inception模型进行二次训练:
数据可视化
在设计和训练机器学习模型的时候,我们会有一个运行时的计算图,还有很多的参数数据,如果只是从代码层面去分析,实在不够直观。Tensorflow提供给了我们一个非常易用而且友好的可视化工具Tensorboard。使用这个工具,我们只需要简单几行代码,便可以将数据做成图表展示出来。
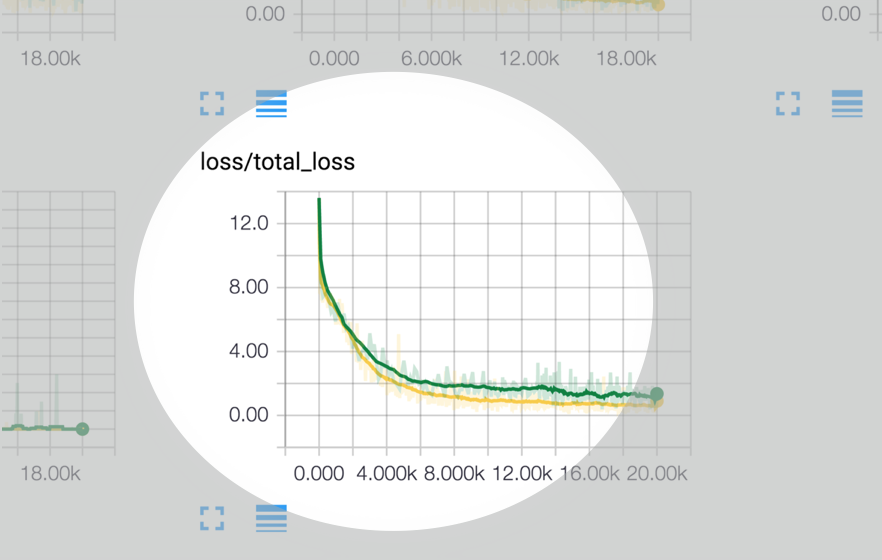
比如我们想要展示我们的损失值的变化情况,我们只需要如下代码就可以实现:
1 | total_loss = ... |
这个时候,我们运行tensorboard并将logdir指向我们配置的数据输出目录,然后打开浏览器就可以看到tensorflow展示的数据了。上面的例子中,我们统计了loss变化情况,在tensorboard里面我们将能看到如下的图表:
上面的例子可以用来展示数值型数据,如果我们想展示多维数据,如weight和bias数据,这个时候,我们可以借助tf.summary.histogram。如果我们需要统计所有的可训练的variable时:
1 | for var in tf.trainable_variables(): |
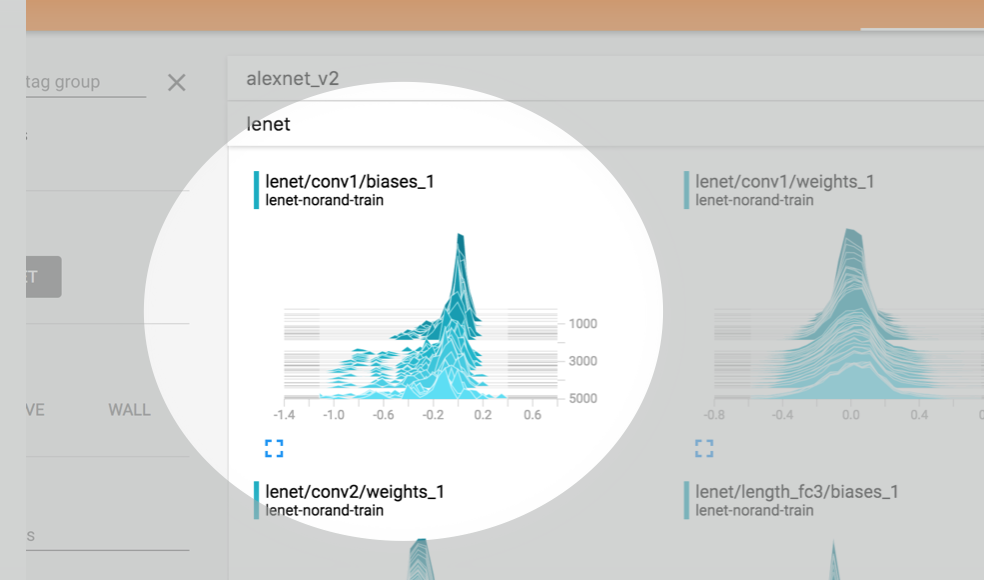
在加入这样几行代码之后,我们在tensorboard的histogram项目下看到如下所示的统计图表:
同时tensorboard会自动绘制我们的运行时的计算图,请看下图中的例子:
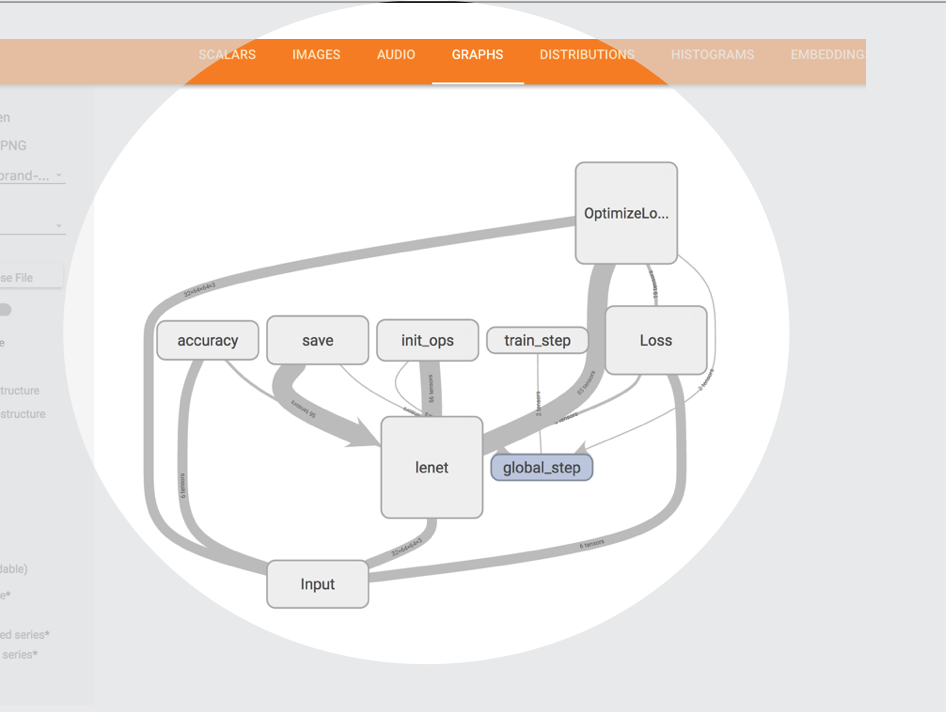
在这个例子中,我们可以使用了tf.name_scope()来将一些逻辑内聚的子图封装到一个节点进行显示,如lenet节点,其内部是一个lenet的网络。同时图中各个节点之间的连线粗细即表示节点直接的数据量大小。通过查看这个图可以很直观的看到我们运行时的计算图的结构,这将非常便于我们分析和展示我们设计的网络结构。
测试和调试
编写tensorflow的模型其实和写普通的代码没什么区别。那么问题来了,我们该怎么做测试呢,甚至是如何做TDD呢?
其实tensorflow已经提供给了我们不少方便测试的工具函数。在我们要做单元测试时,我们可以让我们的测试类继承至tf.test.TestCase,就可以使用self.test_session来方便的创建测试环境了。如以下代码所示:
1 | import tensorflow as tf |
tensorflow给我们提供的有用的测试辅助函数有(仅列举部分):
1 | TestCase.assertAllClose(…) |
有了这些,我们就可以愉快的TDD了。
tensorflow的代码调试会有什么问题呢?
tensorflow的代码一般是分为两个过程,一是计算图的构建,二是计算图的运行。
计算图的构建过程很简单,就是执行普通的python代码,我们可以借住IDE提供给我们的调试工具来进行调试,可以打断点查看各个变量的值。
那么如何调试一个运行中的计算图呢?其实计算图的构建类似编写计算图的静态代码,而计算图的运行则类似代码真正执行的过程。一般而言,我们是无法中断tensorflow的计算图的执行,或者在某处断点调试的。那么,如果计算图运行时出现错误该怎么样来调试呢?其实也很简单,回想一下,我们没有IDE也没有gdb的时候是如何调试的–打log啊。对,就是log。tensorflow提供给我们一个特殊的函数tf.Print,我们可以传入一个tensor,和一些要打印的其他tensor,该函数会在计算图运行时打印消息,并返回这个tensor,这个tensor可以用于进行后续计算了。
示例代码如下:
1 | dequeued_img = tf.image.decode_png( dequeued_record_string, channels) |
总结
以上分享了六个tensorflow的技巧:队列及多线程、分离训练和验证过程、分布式执行、使用现成的模型、数据可视化、测试和调试。使用这些技巧可以给我们设计和调优tensorflow模型带来很多方便。