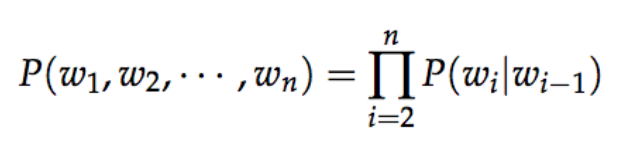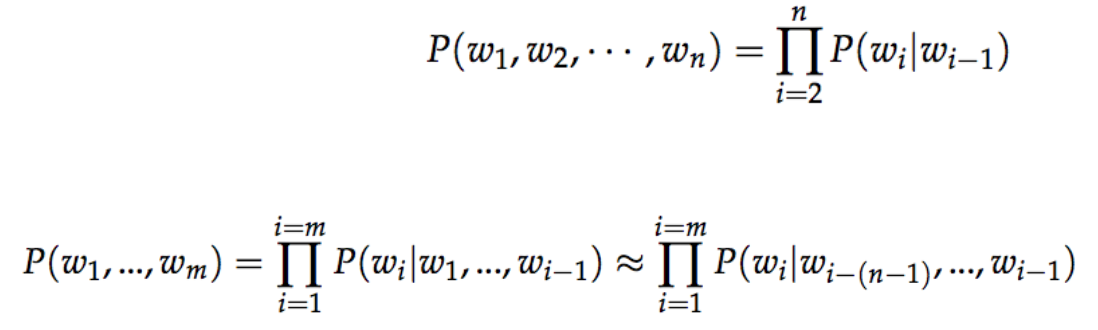defmaybe_download(filename, expected_bytes): """Download a file if not present, and make sure it's the right size.""" ifnot os.path.exists(filename): filename, _ = urlretrieve(url + filename, filename) statinfo = os.stat(filename) if statinfo.st_size == expected_bytes: print('Found and verified %s' % filename) else: print(statinfo.st_size) raise Exception( 'Failed to verify ' + filename + '. Can you get to it with a browser?') return filename
filename = maybe_download('text8.zip', 31344016)
defread_data(filename): """Extract the first file enclosed in a zip file as a list of words""" with zipfile.ZipFile(filename) as f: data = tf.compat.as_str(f.read(f.namelist()[0])).split() return data words = read_data(filename) print('Data size %d' % len(words))
defbuild_dataset(words): count = [['UNK', -1]] count.extend(collections.Counter(words).most_common(vocabulary_size - 1)) dictionary = dict() for word, _ in count: dictionary[word] = len(dictionary) data = list() unk_count = 0 for word in words: if word in dictionary: index = dictionary[word] else: index = 0# dictionary['UNK'] unk_count = unk_count + 1 data.append(index) count[0][1] = unk_count reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words) print('Most common words (+UNK)', count[:5]) print('Sample data', data[:10]) del words # Hint to reduce memory.
defgenerate_batch(batch_size, num_skips, skip_window): global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32) span = 2 * skip_window + 1# [ skip_window target skip_window ] buffer = collections.deque(maxlen=span) for _ inrange(span): buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) for i inrange(batch_size // num_skips): target = skip_window # target label at the center of the buffer targets_to_avoid = [ skip_window ] for j inrange(num_skips): while target in targets_to_avoid: target = random.randint(0, span - 1) targets_to_avoid.append(target) batch[i * num_skips + j] = buffer[skip_window] labels[i * num_skips + j, 0] = buffer[target] buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) return batch, labels
print('data:', [reverse_dictionary[di] for di in data[:8]])
for num_skips, skip_window in [(2, 1), (4, 2)]: data_index = 0 batch, labels = generate_batch(batch_size=8, num_skips=num_skips, skip_window=skip_window) print('\nwith num_skips = %d and skip_window = %d:' % (num_skips, skip_window)) print(' batch:', [reverse_dictionary[bi] for bi in batch]) print(' labels:', [reverse_dictionary[li] for li in labels.reshape(8)])
batch_size = 128 embedding_size = 128# Dimension of the embedding vector. skip_window = 1# How many words to consider left and right. num_skips = 2# How many times to reuse an input to generate a label. # We pick a random validation set to sample nearest neighbors. here we limit the # validation samples to the words that have a low numeric ID, which by # construction are also the most frequent. valid_size = 16# Random set of words to evaluate similarity on. valid_window = 100# Only pick dev samples in the head of the distribution. valid_examples = np.array(random.sample(range(valid_window), valid_size)) num_sampled = 64# Number of negative examples to sample.
graph = tf.Graph()
with graph.as_default(), tf.device('/cpu:0'):
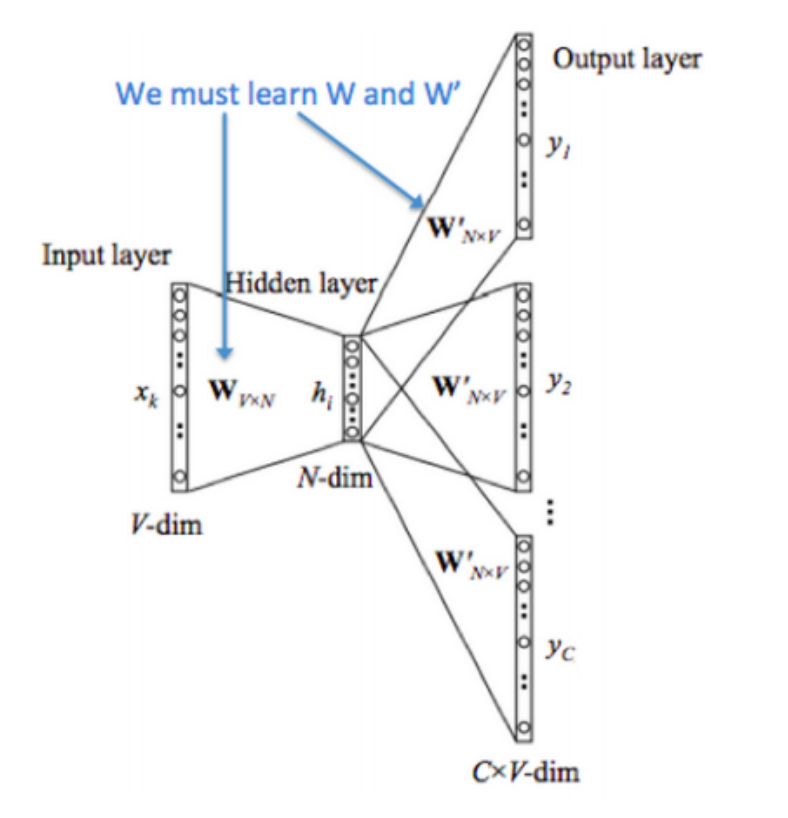
# Input data. train_dataset = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) valid_dataset = tf.constant(valid_examples, dtype=tf.int32) # Variables. embeddings = tf.Variable( tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) softmax_weights = tf.Variable( tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) softmax_biases = tf.Variable(tf.zeros([vocabulary_size])) # Model. # Look up embeddings for inputs. embed = tf.nn.embedding_lookup(embeddings, train_dataset) # embed.shape: (batch_size, embedding_size) # Compute the softmax loss, using a sample of the negative labels each time. loss = tf.reduce_mean( tf.nn.sampled_softmax_loss(softmax_weights, softmax_biases, embed, train_labels, num_sampled, vocabulary_size))
# Optimizer. # Note: The optimizer will optimize the softmax_weights AND the embeddings. # This is because the embeddings are defined as a variable quantity and the # optimizer's `minimize` method will by default modify all variable quantities # that contribute to the tensor it is passed. # See docs on `tf.train.Optimizer.minimize()` for more details. optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss)
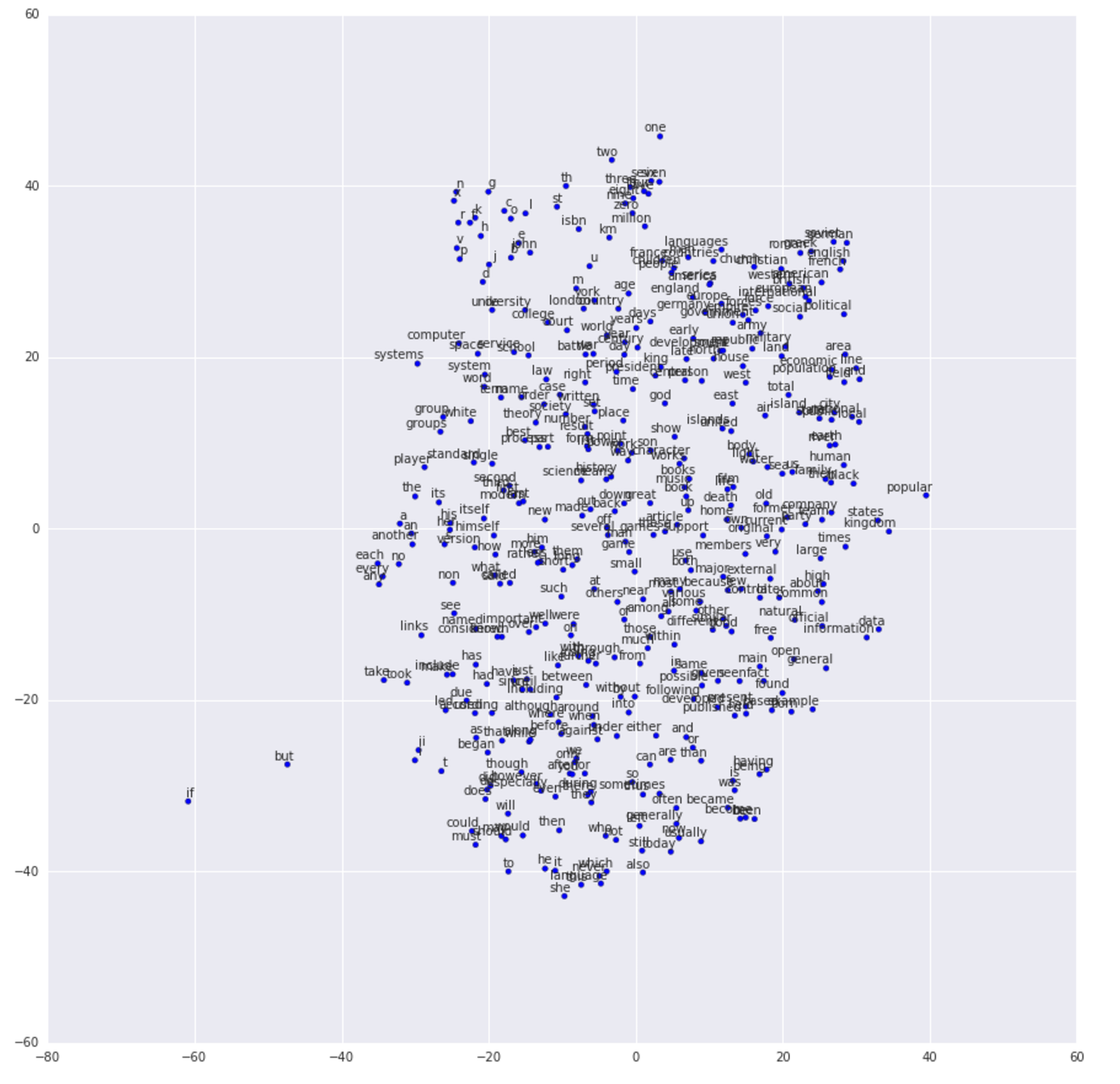
with tf.Session(graph=graph) as session: tf.global_variables_initializer().run() print('Initialized') average_loss = 0 for step inrange(num_steps): batch_data, batch_labels = generate_batch( batch_size, num_skips, skip_window) feed_dict = {train_dataset : batch_data, train_labels : batch_labels} _, l = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += l if step % 2000 == 0: if step > 0: average_loss = average_loss / 2000 # The average loss is an estimate of the loss over the last 2000 batches. print('Average loss at step %d: %f' % (step, average_loss)) average_loss = 0 # note that this is expensive (~20% slowdown if computed every 500 steps) if step % 10000 == 0: sim = similarity.eval() for i inrange(valid_size): valid_word = reverse_dictionary[valid_examples[i]] top_k = 8# number of nearest neighbors nearest = (-sim[i, :]).argsort()[1:top_k+1] # argsort will sort elements as ascended, so we need a minus symbol log = 'Nearest to %s:' % valid_word for k inrange(top_k): close_word = reverse_dictionary[nearest[k]] log = '%s %s,' % (log, close_word) print(log) final_embeddings = normalized_embeddings.eval()
defgenerate_batch(batch_size, num_skips, skip_window): global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size // num_skips, 1), dtype=np.int32) span = 2 * skip_window + 1# [ skip_window target skip_window ] buffer = collections.deque(maxlen=span) for _ inrange(span): buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) for i inrange(batch_size // num_skips): target = skip_window # target label at the center of the buffer targets_to_avoid = [ skip_window ] for j inrange(num_skips): while target in targets_to_avoid: target = random.randint(0, span - 1) targets_to_avoid.append(target) batch[i * num_skips + j] = buffer[target] labels[i, 0] = buffer[skip_window] buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) return batch, labels
print('data:', [reverse_dictionary[di] for di in data[:8]])
for num_skips, skip_window in [(2, 1), (4, 2)]: data_index = 0 batch, labels = generate_batch(batch_size=8, num_skips=num_skips, skip_window=skip_window) print('\nwith num_skips = %d and skip_window = %d:' % (num_skips, skip_window)) print(' batch:', [reverse_dictionary[bi] for bi in batch]) print(' labels:', [reverse_dictionary[li] for li in labels.reshape(8//num_skips)])
batch_size = 128 embedding_size = 128# Dimension of the embedding vector. skip_window = 1# How many words to consider left and right. num_skips = 2# How many times to reuse an input to generate a label. # We pick a random validation set to sample nearest neighbors. here we limit the # validation samples to the words that have a low numeric ID, which by # construction are also the most frequent. valid_size = 16# Random set of words to evaluate similarity on. valid_window = 100# Only pick dev samples in the head of the distribution. valid_examples = np.array(random.sample(range(valid_window), valid_size)) num_sampled = 64# Number of negative examples to sample.
graph = tf.Graph()
with graph.as_default(), tf.device('/cpu:0'):
# Input data. train_dataset = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size//num_skips, 1]) valid_dataset = tf.constant(valid_examples, dtype=tf.int32) # Variables. embeddings = tf.Variable( tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) softmax_weights = tf.Variable( tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) softmax_biases = tf.Variable(tf.zeros([vocabulary_size])) # Model. # Look up embeddings for inputs. embed = tf.nn.embedding_lookup(embeddings, train_dataset) # embed.shape: (batch_size, embedding_size) segment_ids = tf.constant([i//num_skips for i inrange(batch_size)], dtype=tf.int32) embed = tf.segment_mean(embed, segment_ids) # Compute the softmax loss, using a sample of the negative labels each time. loss = tf.reduce_mean( tf.nn.sampled_softmax_loss(softmax_weights, softmax_biases, embed, train_labels, num_sampled, vocabulary_size))
# Optimizer. # Note: The optimizer will optimize the softmax_weights AND the embeddings. # This is because the embeddings are defined as a variable quantity and the # optimizer's `minimize` method will by default modify all variable quantities # that contribute to the tensor it is passed. # See docs on `tf.train.Optimizer.minimize()` for more details. optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss) # Compute the similarity between minibatch examples and all embeddings. # We use the cosine distance: norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm valid_embeddings = tf.nn.embedding_lookup( normalized_embeddings, valid_dataset) similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings)) # similarity.shape: (valid_size, vocabulary_size)