最近在研究生成对抗网络,也对内对外做过一些分享。这里把分享过的内容整理一下,如有不对的地方,欢迎留言指出。也欢迎大家留言交流。这里是关于生成对抗网络的第一部分。
生成对抗网络介绍
什么是生成对抗网络?
从这个名称来看,我们可以了解到,这个网络是用一种对抗方法去生成数据的。和其他的机器学习模型相比,生成对抗网络里面最炫酷的理念莫过于给机器学习引入了对抗。纵观地球上的生物们的成长和发展路线就会发现,物竞天择,适者生存,万物都是在不停的和其他事物对抗中成长和发展的。生成对抗网络就像我们玩下面的格斗游戏一样,我们的学习过程就是,不断找其他对手对抗,在对抗中积累经验,提升自己的技能。

生成对抗网络的英文是Generative Adversarial Nets(以下简称GAN)。它是生成模型的一种,生成模型就是用机器学习去生成我们想要的数据,数学化一点来讲,就是获取训练样本并训练一个模型,该模型能按照我们定义的目标数据分布去生成数据。其实我们应该已经接触过不少生成模型了。比如autoencoder自编码器,它的decoding部分其实就是一种生成模型,它是在生成原数据。又比如seq2seq序列到序列模型,其实也是生成另一个我们想要的序列。Neural style transfer的目标其实也是生成图片。
我们这里研究的生成对抗网络包括两个部分,一个是生成器(generator),一个是判别器(discriminator)。他们的目标分别是:
- Generator:生成看起来’自然’的图像,与训练数据分布尽可能一致
- Discriminator:判断给定图像是否像是人为(机器)生成的
可以看到这里生成器和判别器就是相互竞争的关系。后面会了解到他们是如何进行相互对抗学习的。
为什么说生成对抗网络很重要呢?因为生成对抗网络事实上是无监督学习的一种,无监督学习能大大的降低对数据的需求,从而降低我们的AI研究成本。Facebook的AI团队主管Yann LeCun曾经用蛋糕比喻过机器学习里面的各种算法:
如果人工智能是一块蛋糕,那么强化学习是蛋糕上的一粒樱桃,监督学习是外面的一层糖霜,无监督学习则是蛋糕胚。
目前我们只知道如何制作糖霜和樱桃,却不知如何制作蛋糕胚。
从他的评价里面我们也可以看到当前在无监督学习领域的研究中,我们还有很长的路要走。同时他评价生成对抗网络为:
对抗性网络是“20年来机器学习领域最酷的想法”。
可以看到生成对抗网络是当前非常有前途的一种深度学习模型。
生成对抗网络的历史及发展?
生成对抗网络事实上是近几年才提出来,并得到大家的广泛关注的。当然,如今机器学习发展迅猛,短短几年之间,我们可以看到有很多很多优秀的相关研究论文发出来。下面的图里简要的列举了几篇比较有代表性的论文,从这里我们可以一窥生成对抗网络的历史及发展。
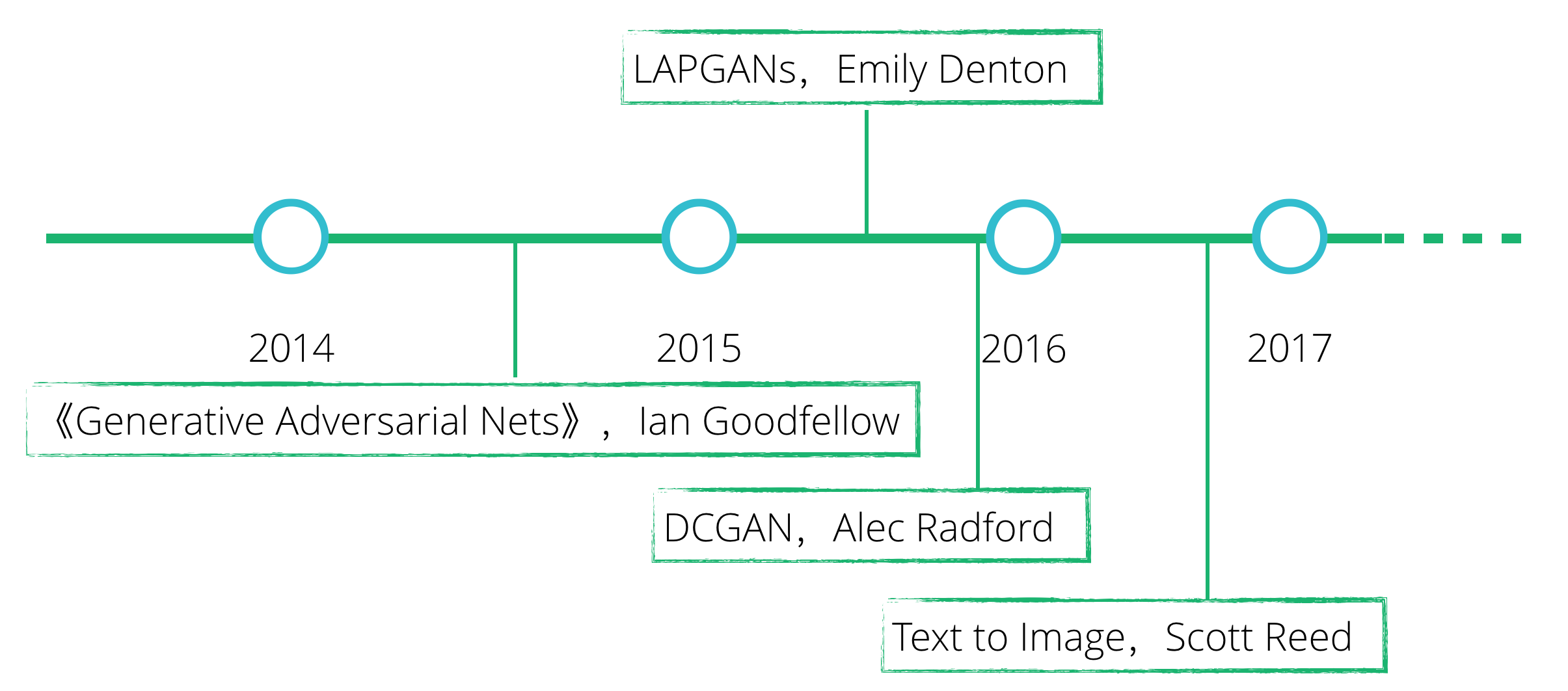
- 2014年的时候,Ian J Goodfellow提交了一篇论文,描述了他们设计的生成对抗网络,生成对抗网络在这里第一次出现。
- 随后以Facebook AI团队为主,发表了一篇论文,描述了一种拉普拉斯金字塔结构的网络,对生成对抗网络做出了很多改进。并使得生成对抗网络可以生成更清晰的图像。
- 后来他们还发表了一篇名为DCGAN的论文,他们充分利用了卷积神经网络模型的研究成果,让GAN模型的训练更快更稳定,而且他们还深入研究了这个模型所学到的东西,并将他们可视化了出来。
- 再之后,去年年末的时候,以密歇根大学为主,他们研究了如何通过一句话来生成想要的图片。
今年关于这个主题还有很多新的论文发出来,我们也可以看到很多相关的应用在不断出现在我们的眼前。总体上来讲,生成对抗这种思路是很有前景的,非常有希望能通过它来实现通用的人工智能。
生成对抗网络应用
那么生成对抗网络可以在哪些领域发挥作用呢?下图列举了部分可以应用的场景:

生成对抗网络可以广泛应用于图像生成,图像超分辨率,交互式图像生成,图像到图像生成,图像编辑以及文本转图像中。当然还有很多很多场景都可以应用这个模型,大家可以持续关注它的发展。
下面是伯克利大学和Adobe公司一起研发的一个原型应用:
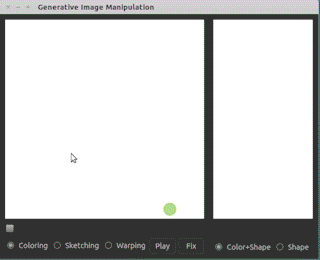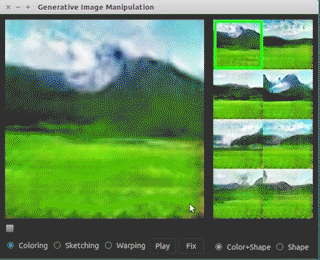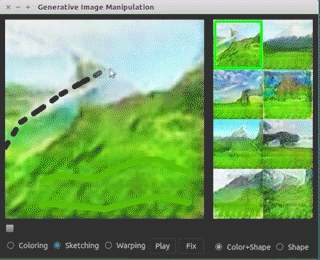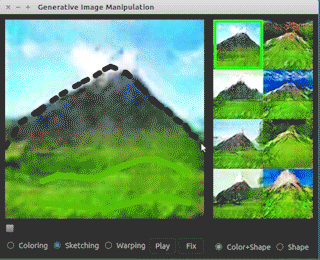
可以看到,设计师只需要寥寥几笔就可以修改图像并生成自己想要的图片了。
GAN的提出及详解
GAN的提出
GAN最初是由以Ian J. Goodfellow为主的研究团队在2014年6月提出的,他们提交的论文名是《Generative Adversarial Nets》。Ian Goodfellow 之前在 Google Brain 项目工作过,后来又去OpenAI从事研究工作。他提交的论文为数众多,被引用次数也很多,在机器学习领域很有名气。在这篇论文里面他们提到,他们提出了一种新的生成模型,模型通过对抗进行学习,在这个模型里面会同时对两个模型进行训练。

GAN的结构
他们在论文里面提到的结构如下:
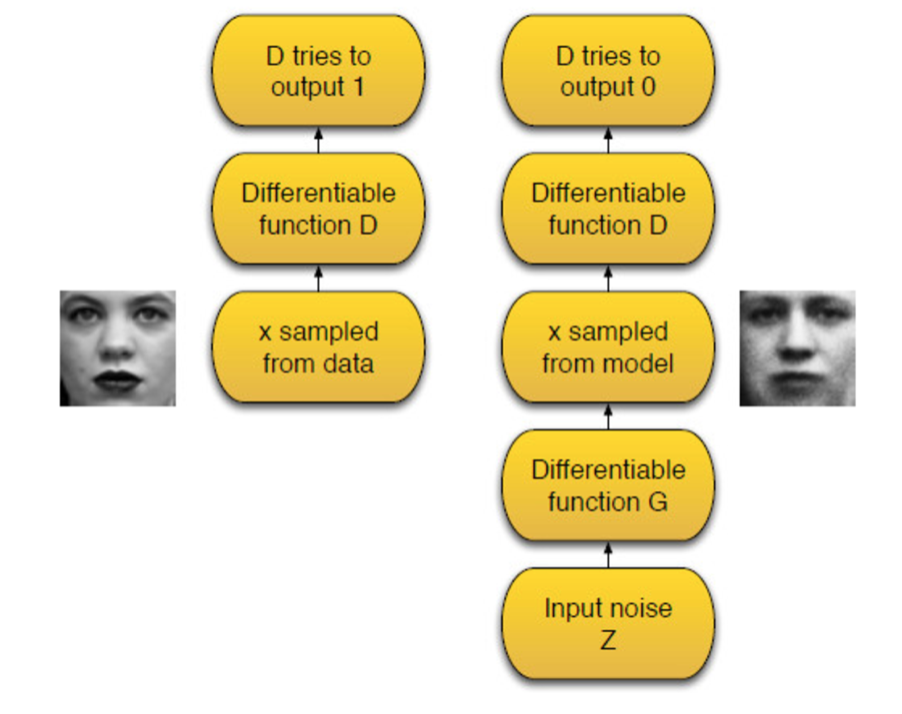
观察这个结构,我们可以看到两个可微的函数G和D,他们就分别表示生成器和判别器网络。他这里的描述中直接用函数代替了网络,我们可以体会到,深度神经网络其实就是一个有输入和输出的函数而已。结构里面的x表示一个训练数据向量,比如可以是一张真实的照片。x输入D网络,D网络应该要输出1,表示输入数据是真实数据。Z表示一个噪声向量,随机生成。以Z作为输入,在经过G网络之后,将会得到和x向量相同大小的向量,这个向量在经过D网络之后输出0,这表示判别器应该识别其为生成的数据。
在训练过程中,G网络的目标是让D生成的数据趋近于1。这就是GAN的结构,我们可以看到生成器和判别器各司其职,又相互竞争,D想要区分出G生成的数据和真实的数据,而G网络的目标是不让G网络能区分出自己生成的数据是假数据。也就是G网络想要学习到真实数据的分布情况。
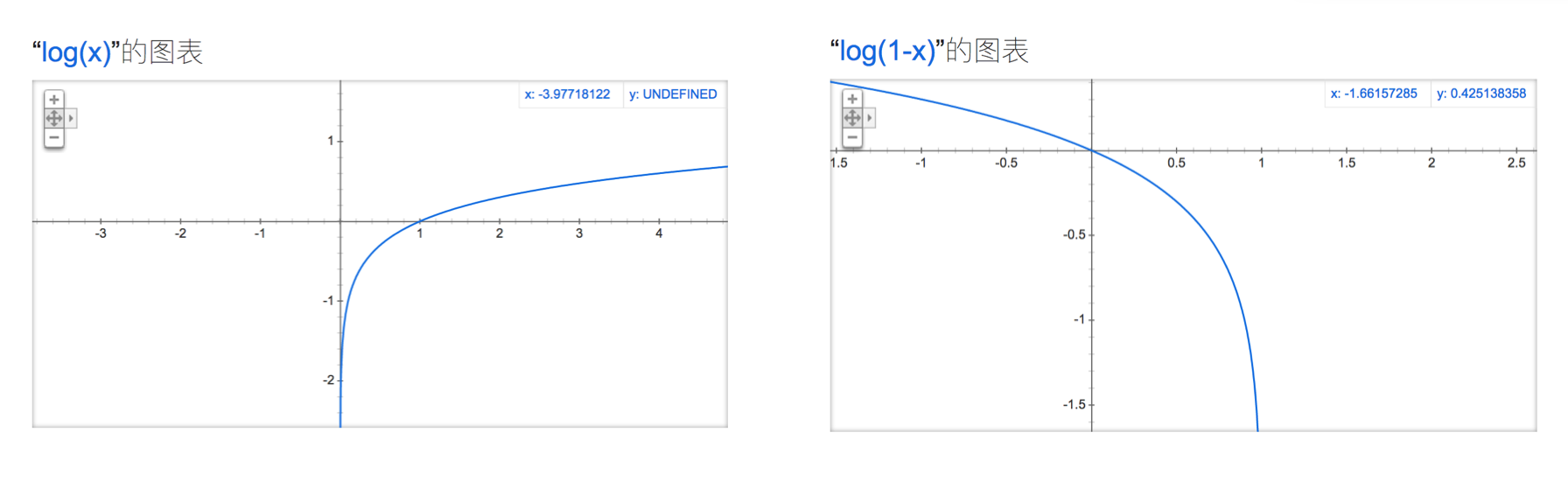
log函数回顾
那么GAN网络的loss函数是什么呢?在看这个函数之前,我们先回顾一下log函数的曲线。下图中是以10为底的对数函数,其取值区间负无穷到正无穷的。log(x)单调递增,log(1-x)单调递减。在0-1的区间里面,他们的值域都是负无穷到0。
有了这些了解之后,我们下面看看GAN的损失函数。
损失函数
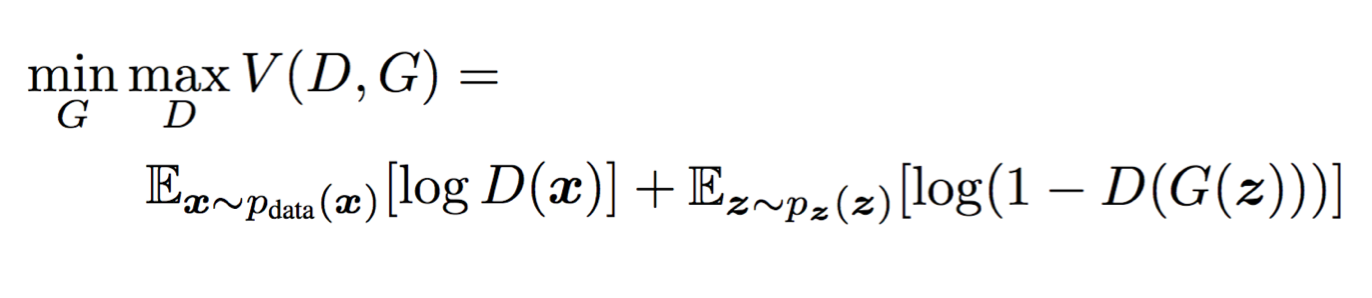
这个公式是GAN论文里面给出来的Loss函数公式,这个只是判别器网络的公式。这个公式包含两部分内容,前一部分表示真实数据在经过判别器之后的输出,然后应用log(x)函数。后一部分表示生成的数据在经过判别器之后的输出,然后应用log(1-x)函数。这里的目标是要优化我们的判别器,让这个公式取值越大越好,从这个角度来看,它并不是损失函数,称为价值函数可能更合适,但是为了不引入更多的术语,我们还是称为损失函数吧。如何才能越大呢,由前面分析过的log函数曲线,我们知道,当D(x)尽量大,同时D(G(x))尽量小的时候,值就越大。这也就是公式前面有一个min(G)和max(D)的原因。
生成器网络的损失函数是什么呢,其实就是上面公司的后半部分了。不过对生成器而言,它的目标是要让后半部分公式的值越小越好。也就是说它的目标是让判别器识别它生成的图片为真实的图片。
那么我们的模型会在什么时候收敛呢?论文里面给出了很长的很细致的证明,这里就略过,有兴趣的可能直接看原文。下图给出了当这个函数收敛的时候相关参数的值。
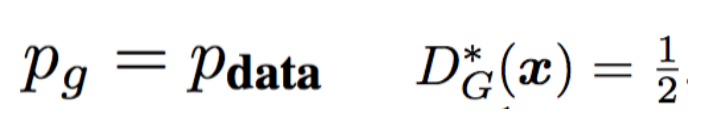
可以看到,模型会在p(g)与p(data)相等的时候收敛,这个时候D(G(x))的值为1/2。这意味着生成器生成的数据和我们训练的数据在分布上是一致的,同时,判别器已经无法判别到底是生成的数据还是真实数据了。
算法
论文里面给出的训练算法如下:

可以看到我们需要先训练判别器,训练的batch次数为k,k是模型的超参数,我们可以根据模型的训练效果进行调整。训练判别器时,我们需要同时有真实数据m和噪声向量z,然后根据损失函数公式求偏导来更新模型参数。需要注意的是,这里是使用梯度上升来更新模型参数的。因为我们的目标是要让这个函数取值趋近于更大。但是在具体实现过程中,更方便的方式是再应用一个递减的函数变换,让它变成真正的损失函数。
在对判别器训练k步之后,我们再开始训练生成器,训练生成器的时候,这里我们的目标是让损失函数趋近于更小,所以使用梯度下降。
这里还需要注意的是,在训练判别器的时候,我们会只更新判别器的权重,而不更新生成器的权重。在训练生成器的时候则相反,只更新生成器的参数。
loss函数的实现
loss函数该怎么实现呢?我们事实上可以利用更通用的损失函数来实现,因为这里是二分类,所以我们可以使用sigmoid_cross_entrophy来实现。具体实现如下:

我们还是按照两部分来构造损失函数。第一部分是真实数据的判别结果,它的label应该为1。第二部分是生成数据的判别结果,它的label应该为0。
相应的生成器的损失函数可以实现如下:

需要注意的是,由于生成器的目标是让判别器的结果为1,所以这里我们的label就为1。这是和判别器的损失函数的不同之处。
GAN生成的图像
GAN生成的图像效果如下:

其中用黄色框框起来的是真实数据,也就是 Ground Truth 。可以看到GAN在面对简单的mnist手写数字和TFD人脸图像生成的时候,表现比较好,但是在复杂的图像上面生成的图像则比较模糊。
到这里我们的模型介绍就结束了。后面将会开始演示如何实现一个简单的GAN来生成手写数字。
TensorFlow的API介绍
TensorFlow API浏览
打开tensorflow的官方网站可以看到,tensorflow的模块很多,关于图像处理的,关于算法的,关于视频处理的,关于统计学的等等。这里提几点我观察到的tensorflow的API变化情况:
- 高级API在逐步的稳定:在tf.train包里面逐渐多了 Supervisor SessionRunHook 等这样的高级训练过程管理的类
- 稳定的API会慢慢从contrib移到tensorflow支持的顶级包下面去:在tf.layers包之前是没有的,现在已经增加起来了,而且阅读里面增加的API可以发现,其实就是之前的tf.contrib.layers包下面的内容
- 在contrib中引入了keras:keras是基本上完全按照面向对象的方式设计的一套深度学习API,API易于理解和使用,人气很高,tensorflow也是希望直接支持keras作为其高级API
- 调试及性能优化的功能逐渐完善:tensorflow引入了Debug支持,JIT和AOT支持等
TensorFlow API设计
观察tensorflow的API可以发现,它的API设计其实是函数式和面向对象相结合的。tensorflow大部分算法相关的API直接设计成函数,而功能相关的API则设计成面向对象的,比如Queue还有SummaryWriter这样的类。
对于TensorFlow的高级API,其实从易用性上来讲,是需要倾向于面向对象的。我们可以发现tensorflow的高级API有下面这些特点:
- 以函数式的方式提供出来,然而因为函数式的方式难以去管理大量的状态,所以我们看到了大量的全局状态,具体表现就是
tf.get_collection接口,这个接口的一个参数是key,也就是说通过很多的key去获取状态。 - 以面向对象实现,但是对外提供函数式的API,如tf.layers里面的API
- 面向对象的API不够完整,比如有Layer的设计,但并没有Layer容器
- 有些API直接就是函数式和面向对象的综合,看起来有些蹩脚,比如Esimator类,它的第一个参数是一个函数
model_fn,让调用者传入一个用于构造模型的函数。
基于此,我个人建议在使用tensorflow的API的时候,可以考虑以下几点:
-
使用TensorFlow的API
- 使用函数式接口
- 优先使用非contrib包的API
- 自己进行面向对象封装
-
使用Keras的API
- 更加纯粹的面向对象API
我们要用到的API
在我们的代码里面我们主要使用到了这几个模块的API
- tf.layers
- tf.contrib.layers
- Training API
- summary API
GAN的实现
这里的代码实现是用TDD的方式实现的。TDD可以帮我们理清需求,提供快速的反馈,帮助我们更有效率的去做正确的事情。TDD的好处多多,这里就不多讲了,有兴趣的可以参阅其他资料。
在开始之前,我们假设我们有一个model.py这样的模块用来存放我们的模型代码。对于这个模块,我们的测试模块就是model_test.py。从测试入手来分析,我们应该需要一个GANModel模型类来辅助我们构建好我们的GAN模型。从前面的分析来看,GANModel需要有一个generated_image这样的输出,表示生成器模型的输出。到此,我们就可以建立我们的第一个测试来验证我们的模型可以将生成器模型给构建出来。
我们可以编写代码如下:
1 | class GANModelTest(tf.test.TestCase): |
此时代码肯定是没法运行的,因为我们还没有GANModel这个类呢,我们在model.py模块里面建立这个类,并尝试使用转置卷积设计一个模型,实现代码如下:
1 | def _build_generator(input_data, name='generator'): |
到此,我们可以运行一下我们的测试看看,是否实现了这个功能。在经历一番调试之后,大家应该都可以顺利让测试通过,因为现在的逻辑都还比较简单。
第二步就是实现我们的判别器,判别器分为两个部分,真实数据为输入和生成的数据为输入。先来看真实数据作为输入的情况。编写测试代码如下:
1 | def test_discriminate_real(self): |
在设计好我们的判别器模型之后,我们可以得到程序代码如下:
1 | def _build_discriminator(input_data, reuse_variables=False, name='discriminator'): |
现在我们要支持对生成的数据进行判别了。测试代码如下:
1 | def test_discriminate_fake(self): |
复用我们之前_build_discriminator函数,我们需要在GANModel的构造器中添加代码。这里需要注意的是,由于这里的模型需要复用之前为判别器创建的变量,所以我们传入一个reuse_variables为True,如下:
1 | class GANModel(object): |
这个时候上面的测试应该也可以通过了。
下面一个功能就是训练过程了。GANModel需要有一个函数来支持训练,我们将其命名为fit。为了灵活性,我们可以在外层来管理session,那么这个函数的输入参数需要有一个session。还有就是训练数据,我们可以想到的训练数据应该由这几个部分构成:
images:mnist图像数据batch_size: 批训练的数据量大小noise: 噪声数据,噪声数据作为输入传入这个函数让fit函数没有副作用
这几个参数其实是紧密耦合的,似乎隐藏着一个概念,这里的概念其实就是我们的数据集。我们可以抽象一个数据集的类GANDataset出来。
由于我们训练过程通常还需要对同一个数据集训练多次,也就是epoch,于是我们还需要一个epoch的参数,当然其实也可以考虑将这个参数的管理封装到GANDataset类中。同时,我们还有一个超参数k_steps。思考到这里,我们就可以得到fit函数的签名了。
1 | def fit(self, session, dataset, epochs, k_steps): |
对fit函数建立测试如下:
1 | def test_fit(self): |
由于这里fit函数没有输出,它的作用在与改变权重,对模型进行优化,所以,我们这里没有验证的代码。这里其实仅仅是验证了这个函数可以正常执行,不会抛出异常。虽然这里的测试是比较弱,但是依然可以给我们信心和指导,让我们写出正确的代码。
fit函数的代码如下:
1 | def fit(self, session, dataset, epochs, k_steps): |
在编写fit函数的时候,我们假想了一个dataset对象的存在,并且按照我们的需要设计了这个对象的方法。这虽然不是TDD,然而这里的思想也是源自于TDD,即从使用的角度去设计你的API。
写完这里的代码,GANDataset类的模型就自然而然出来了:
1 | class GANDataset(object): |
根据这里的定义,我们对GANDataset类建立测试如下:
1 | class GANDatasetTest(tf.test.TestCase): |
GANDataset类的实现代码在这里。
这个时候,我们回到fit函数,事实上我们还没有实现我们的优化器呢。但是我们的优化器已经设计好了,名为d_optimizer和g_optimizer。在构造器里面添加代码如下:
1 | class GANModel(object): |
loss函数实际上是不好验证其是否正确的,但是我们之前已经分析过loss函数该如何实现,这里的实现完全是我们分析之后得到的结果。虽然这里的测试不尽完美,但是我们已经有了一个基本的验证了。
到这里我们关于fit的测试应该就可以通过了。
到这里,我们要进行的下一步,测试就难以去支持我们的工作了。因为下一步是要调试我们的模型,看看它能不能按照我们预期的进行收敛。为了看到运行时我们的模型的情况,我们需要tf.summary模块的支持。我们将添加一些重要的指标,以便我们可以在 Tensor Board 上面可视化的进行实验。
在模型的构造器里面添加代码如下:
1 | class GANModel(object): |
我们还需要在训练的过程中,在训练完一定的步数之后,记录这些汇总信息。我们的fit函数已经够复杂了,为了完成这样的需求,我们可以考虑使用定期回调的机制。我们定义一个Callback类如下:
1 | class Callback(object): |
接着可以实现我们的SummaryCallback和LogCallback如下:
1 |
|
接着在fit函数中添加相应的驱动代码就可以驱动我们的回调函数代码运行了。然后我们读取mnist数据集,建立一个main函数就可以完成我们的代码了。
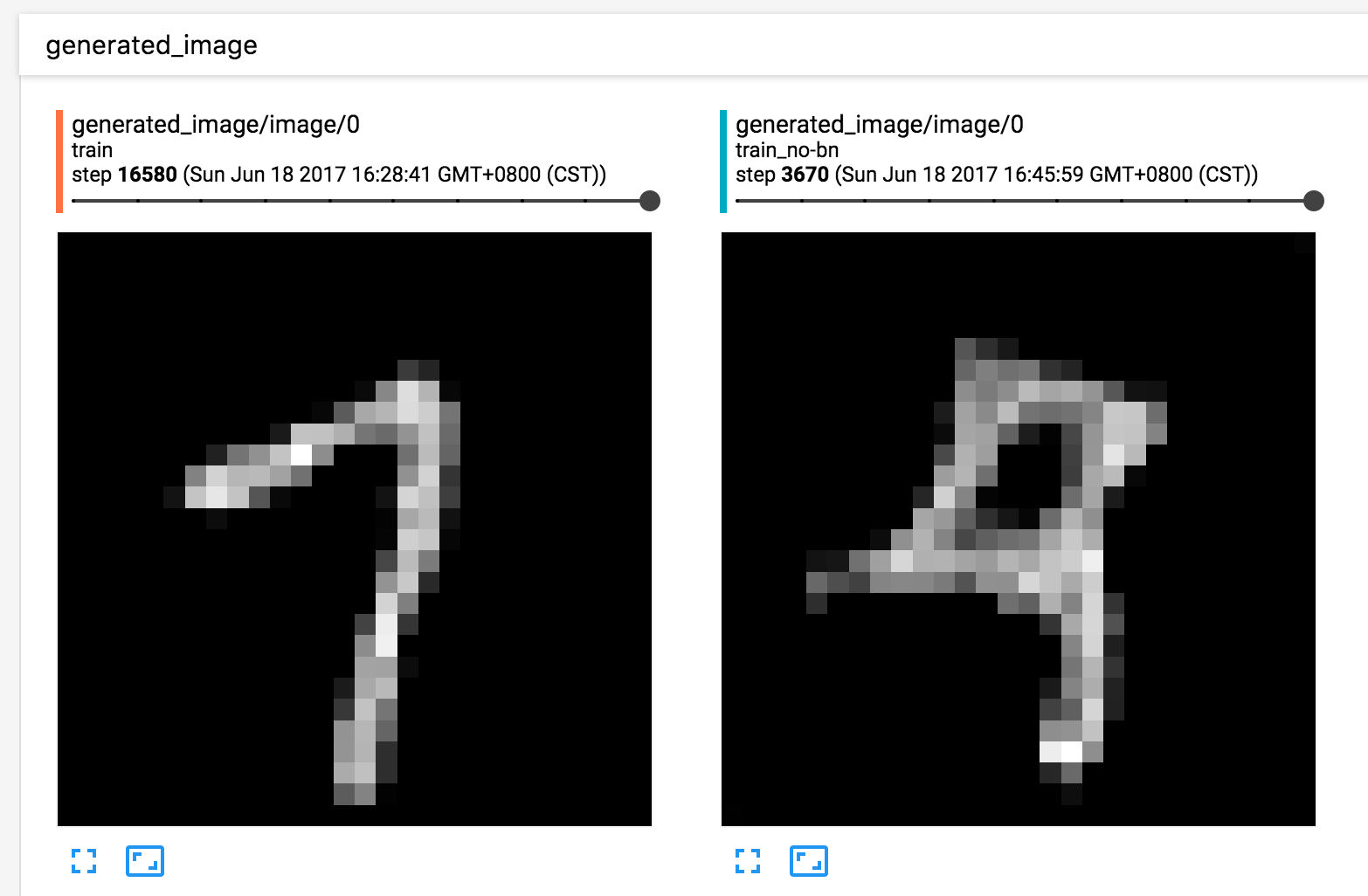
在最后完整的代码里面还包含了batch_normalization,即批规范化,的使用。这是为了让模型能更快和更容易的收敛。
完整的实现代码请参考这里。当然这里并不是一份非常完美的代码,我们可以进行进一步的重构,让其更易读,由于我们有测试代码帮我们保驾护航,我们将能更放心的进行重构,把代码重构到一个更完美的状态。这也是TDD带给我们的好处之一,代码写好了,测试也有了,重构更好做了,最终就有艺术品诞生了。
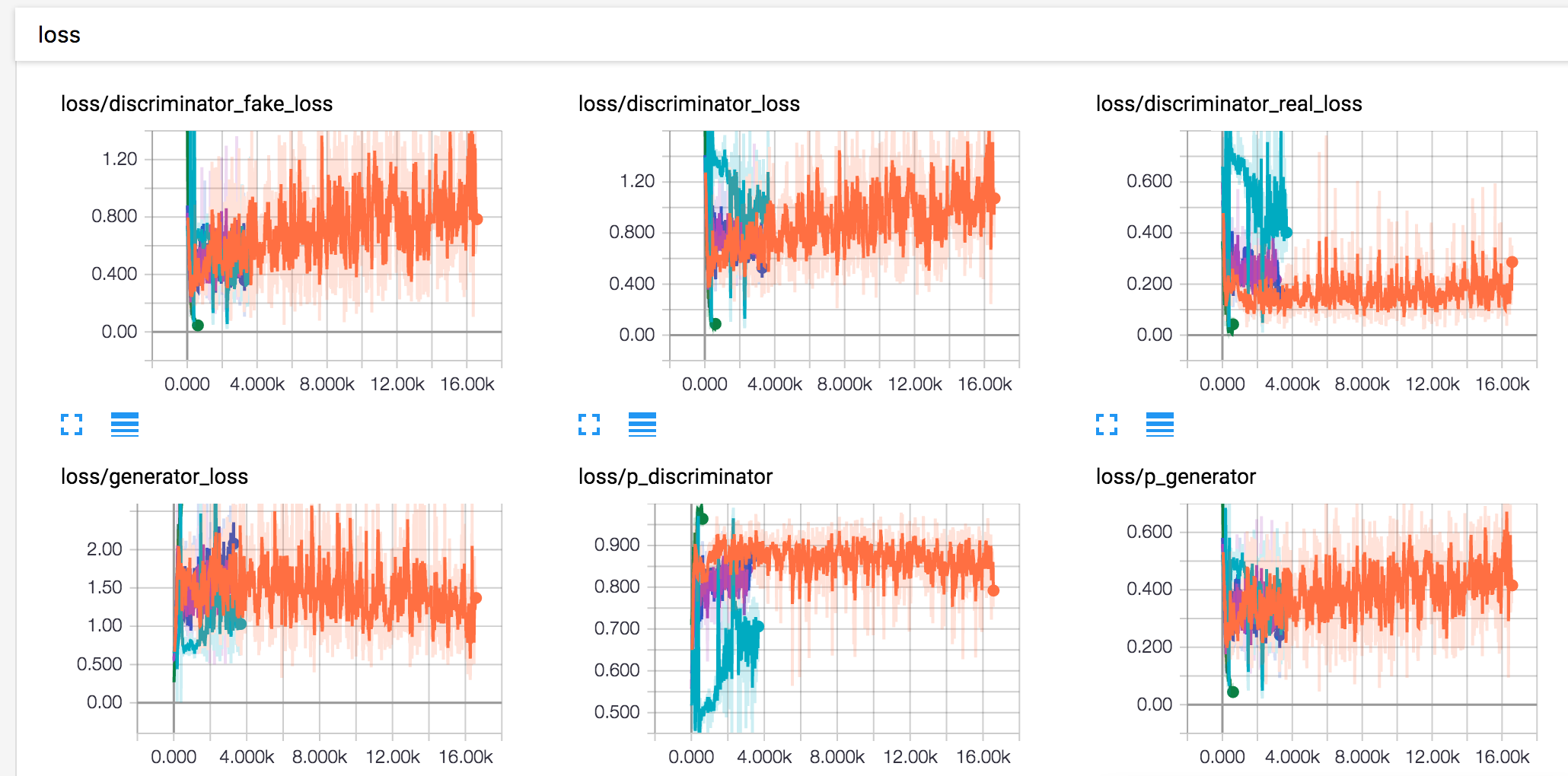
我们可以得到如下的实验结果:
GAN总结
观察上面的loss变化图,我们可以发现,这里的loss变化跟我们之前的模型不一样。就像论文里面的证明一样,这里的loss将会趋近于某一个值,而非0,discriminator_real_loss和discriminator_fake_loss将趋近于相等,同时p_fake和p_real应该要趋近于0.5。
这也从侧面反应了GAN模型的问题。关于GAN模型的不足,我们可以总结如下:
- 复杂图像上表现不好:在MNIST、TFD人脸数据库上面表现不错,但是在更一般的CIFAR数据集上面生成的图像较模糊
- 难以平衡:判别器和生成器同时优化,判别器需要提前多走一步,但是又不能太多
- 训练不够稳定:有时候永远不会学到东西
事实上,我们的模型能很快的收敛,这是因为我们使用了卷积神经网络里面的很多研究成果,比如批规范化的应用,比如池化层的去除等。GAN模型刚提出的时候,其训练是相对比较难的。
到这里,我们的第一部分就结束了,大家有任何问题,欢迎留言讨论!