Previous posts about Easy SQL
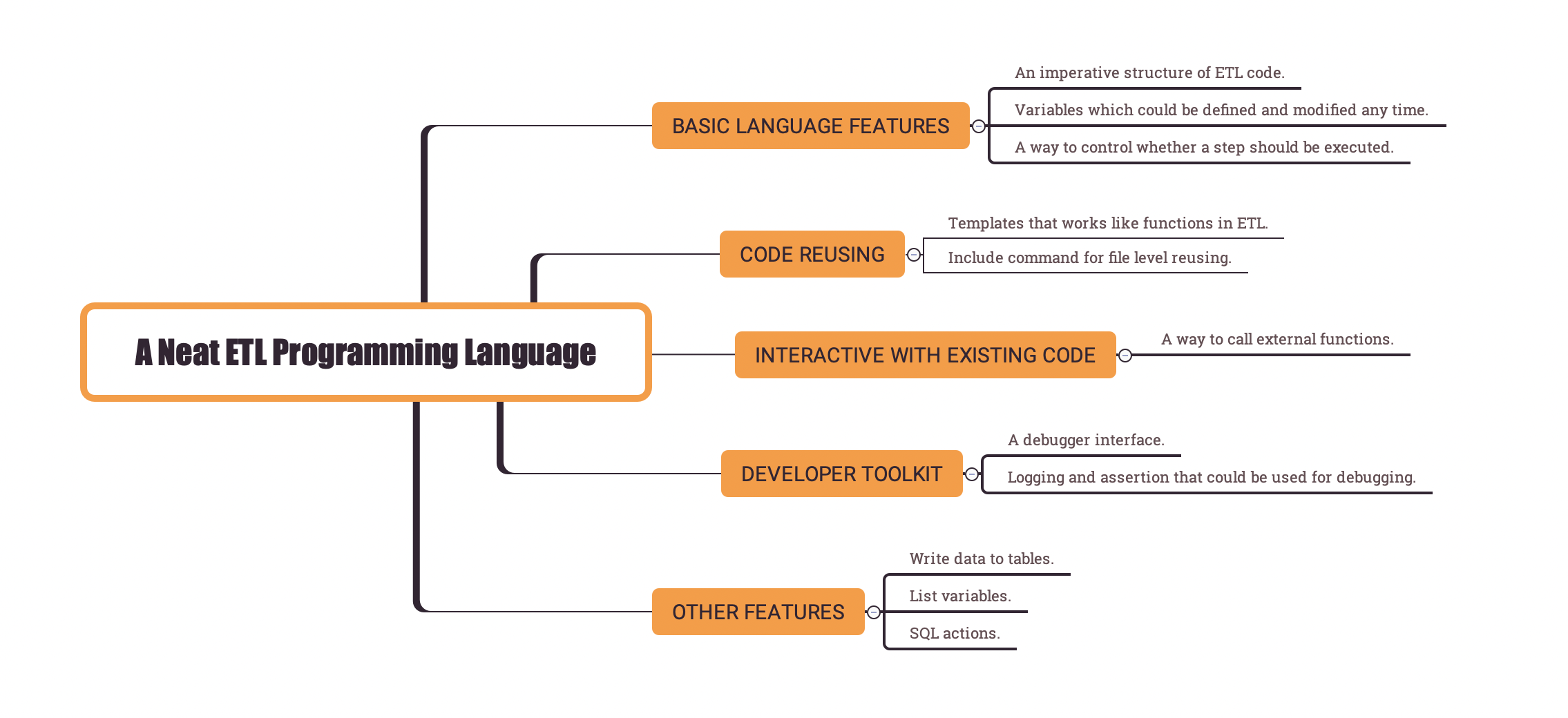
- A new ETL language – Easy SQL
- A guide to write elegant ETL
- Neat syntax design of an ETL language (part 1)
- Neat syntax design of an ETL language (part 2)
It’s always been a pain point to do ETL testing. But it more and more becomes a must after data being so widely used these days.
An ETL with more than 100 lines of code is common. The filter conditions, data transformation rules, join conditions and other logic there could be very complicated.