前几天,我在跟一位做进口贸易的朋友聊天,发现一个很有意思的事情。
他们做的是国内的高端仪器进口的进口贸易业务。主要帮助销售国外产品的公司完成竞标、合同签订、物流、海关、进口贸易政策符合、维保等等事务。
我很疑惑,为什么会有这样的业务形态存在?为什么这些产品销售公司不自己处理这些事务,反而代理出去让其他公司赚钱呢?
我带着这个疑问,向他请教,获得了很多启发。
众所周知,国内的工业起步较晚,虽然这些年突飞猛进成为了世界工厂,但是核心的生产设备很多还是依赖进口。比如在生产芯片时少不了光刻机,在环境、食品、农业等实验室进行的样本成分分析也少不了可以分析各元素浓度的原子光谱仪。这个市场是一个万亿级的大市场。
这个业务有什么特点呢?
一是产品销售数量少。高端仪器一般售价都比较高,普遍在几十万到数百万。所以,一个年营业额在十亿的仪器产品公司其实也只是销售了数百台仪器而已。
二是销售流程特别复杂。由于是物理设备进口,将涉及很多现实的问题,除了产品推广和销售,还有一系列的事务,比如竞标、合同签订、物流、海关、进口贸易政策符合、维保等等,非常复杂。
作为一个在国内销售进口设备的企业,要如何组织其业务呢?
推广和销售是自不必说,否则市场根本不了解产品,就更别谈卖出去了。
但是,销售之外的其他事务要不要自己来做?这个就值得思考了。因为产品销售数量不会太大,但是销售之外的事务却特别复杂而繁多。如果培养一个专业的团队做这件事,由于产品销量不大,团队工作势必不会饱和。如果减少团队人员数量,这些事务又难以做得专业,容易出纰漏。
在经过大量的市场尝试和调整之后,专门做对进口贸易易的企业就诞生了。他们负责产品销售之外的大部分事务,涉及竞标、合同签订、物流、海关、进口贸易政策符合、税收、维保方式设计等。他们常常是一个非常专业的团队,可负责各个领域不同产品的进口贸易业务。在某些品类销售淡季时,其他品类可能又到销售旺季了。所以,他们的业务通常也能保持稳定和饱和。
于是,海外产品研发公司+国内产品销售公司+国内进口贸易公司的模式就在市场上慢慢形成并稳定下来了。总结起来,可以用下图简单地描述这三个企业如何愉快地合作完成整个产品进口销售的过程。
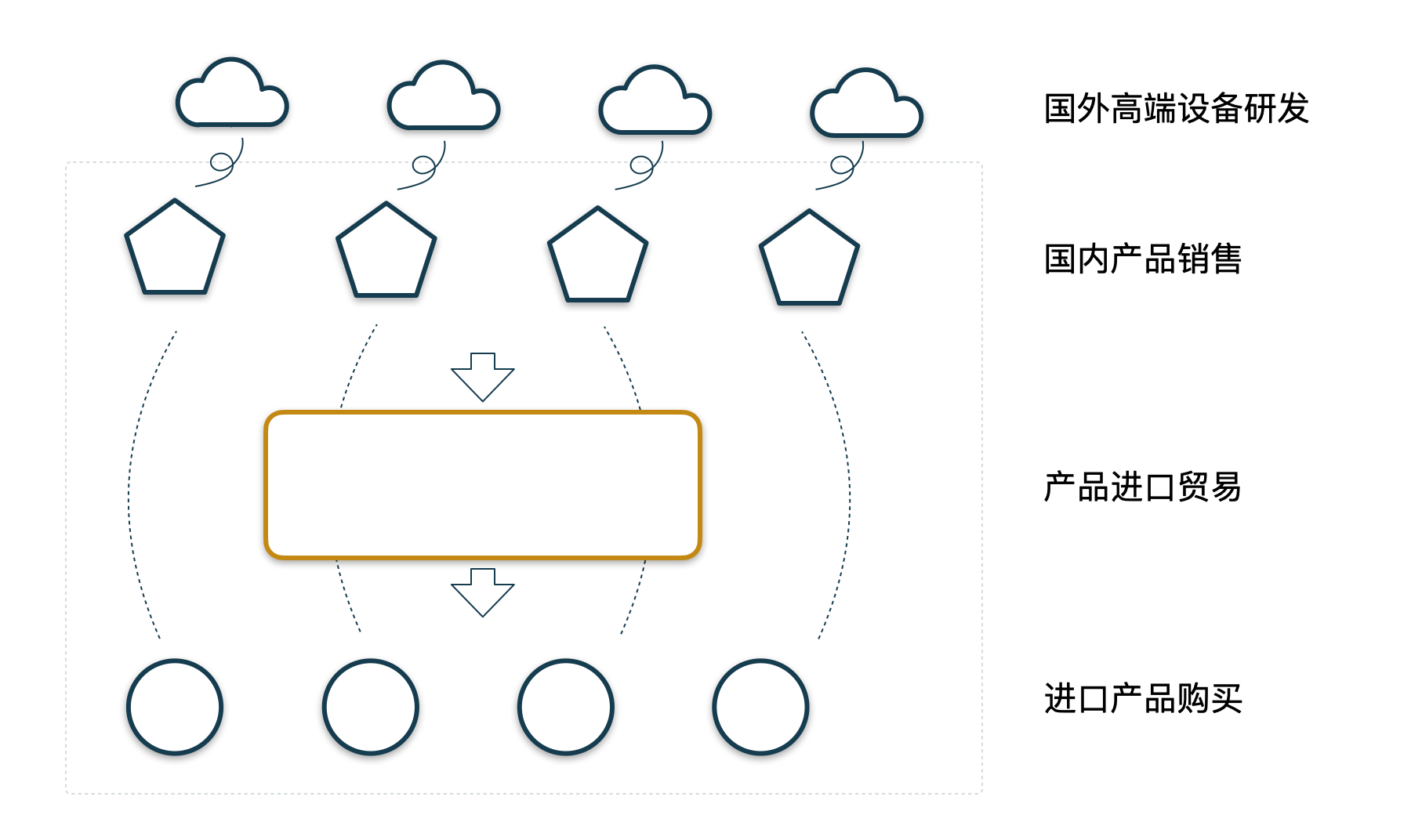
进口贸易企业业务的兴起对整个行业效率和质量的提升都起到了正面的效果,这也是进口贸易企业得以存在的理由。
和这位朋友的交流完之后,我发现进口贸易企业业务的形成给了我不少启发。
从进口贸易企业的兴起中可以看到业务的重构和演变,即,通过合理的抽取和拆分提升了整体的效率。
以ETL为单位的持续集成
我联想到了近几天一直在思考的数据应用开发中的持续集成流水线设计。
在应用软件开发中,我们常常仅设计一条持续集成流水线,在流水线中运行所有的测试,接着将所有代码打包成一个大的产品包,然后部署到测试或产品环境中。
在数据应用中,是不是也需要这样做呢?这样做的好处是可以将产品环境的制品与代码仓库中的版本对应。其劣势其实也很多,比如,修改一个局部的代码,就不得不运行所有的测试,然后运行流水线中所有耗时的步骤,可能还需要进入手工测试的环节,最后才能发布到线上。效率非常低下。
这一问题在数据应用中更是被放大了。因为数据应用通常涉及数百个指标计算ETL,这些ETL的自动化测试只能用缓慢的集成测试来覆盖,这就导致流水线中的测试步骤耗时很长。在我们的项目中,常常需要跑半小时到一小时才能跑完。
这就如同做进口高端仪器销售的公司,如果自己来做进口贸易相关业务,不仅耗时特别长,而且出纰漏的可能性大(业务质量低)。
有没有更好的做法?既然只修改了某一个ETL,为什么不能就只部署和测试这个ETL?联想到前面进口贸易业务的抽取和拆分,是不是可以对流水线进行抽取和拆分呢?即,做以ETL为单位的持续集成流水线。
在数据应用开发场景中,这也是具备可行性的。原因在于,相比应用软件代码中的一个一个类或代码文件,ETL间几乎没有依赖。不同的ETL代码通常有不同的入口,存在于一个独立的文件。可以认为一个ETL就是一个独立的数据应用。
事实上,如果以ETL为单位进行持续集成和部署,还不用担心自己的部署会影响到其他的线上指标计算ETL,这也在一定程度上增强了安全性。
看起来,在数据应用开发领域,以ETL为单位的持续集是顺理成章的事。
对比一下微服务实践,还可以发现,这一实践与微服务中推荐的为每一个服务搭建一条持续集成流水线的实践几乎是等同的。
如何实现
如何实现以ETL为单位的持续集成呢?
如果基于Jenkins,可以在流水线上面加一个参数,如“ETL文件路径”,在运行流水线时,可以指定这个参数,让流水线仅针对指定的ETL运行测试与部署。
如果觉得在Jenkins上面实施以ETL为单位的持续集成较为麻烦,也可以团队自主开发一个专用的数据持续集成流水线。如果仅实现基本的功能,其实也并不复杂。
需要注意的是,一旦以ETL为单位进行持续集成了,就需要有一种方式记录每一个ETL对应的代码仓库里面的版本号,方便版本追溯。实现方式有多种,比如,可以在部署ETL的时候,在生产环境写入一个该ETL对应的版本文件。
总结
如果采用应用软件持续流水线的大包发布方式构建数据应用的持续集成流水线,将降低部署频率,且容易引起安全问题。借鉴进口贸易业务的抽取和拆分模式,在数据应用开发中,将持续集成流水线拆分为以ETL为单位的流水线可以有效解决上述问题。