基于数据点的数据分析
在进行数据分析时,常常会有基于数据点的分析需求。
比如,当做好一个客户画像应用的时候,我们可以得到某个客户的所有标签。如何验证这些标签的准确性呢?一个常用的方法是找到这个客户所有的相关数据,然后基于这些数据去验证标签的准确性。这就是基于数据点的分析,这里的数据点是前面提到的“某个”客户。
同样,当开发完指标之后,也可以尝试找出当前指标粒度(比如经销店粒度)下的所有事实及维度数据,从而进行验证。这里的数据点是“某个”经销店。
(下文为了简单,我们将基于数据点的数据分析简称为“点分析”。)
编写SQL实现点分析
想要完成这样的点分析,一般的做法是编写SQL查询相关数据,然后人为分析数据得到结论。
我们来看一下上面客户画像正确性验证的例子。要验证某一客户的画像,其实是要验证画像中的各种标签。一个典型的标签是客户的价值分级标签,从这个标签可以看出该客户是高价值的,还是低价值的。
从这个标签的计算口径中可以了解到,这个标签会统计客户在整个生命周期内的所有消费。这里的消费包括购买及后续的维修服务、保养服务等。
基于前面文章中建立的数据仓库模型,要实现这一分析,我们需要查询当前最新的业务数据,找出相关事实数据。
以“购买”事实为例,可以编写类似以下代码:
1 | select id from ( |
找到所有这些数据之后,需要进一步判断哪些数据是最终产生了有意义的订单的。这一步通常没有看起来那么简单,因为我们可能需要面对的是查询出来的数百个字段,需要从中找出关键的字段,并弄清楚其业务意义。
指标的计算口径在此时只能作为参考,因为这里的标签验证一定程度上就是为了确认计算口径的正确性。
最准确的答案应当来自当时直接接待该客户的业务人员,但想要联系当时的业务人员来确认也并非易事,通常要耗费较多的沟通时间。
总之,如何确认这些数据需要花费大量的时间查看及对比各个维度的数据。
提高点分析的效率
分析上述基于SQL的点分析过程,除了不可避免的需要人为去查看对比数据进行分析,还有一些可以从技术上提供方法进行优化的。比如:
- 简化
SQL编写的复杂度 - 提高
SQL查询性能 - 提供工具让分析师更容易的查看数据
下面主要从上述三点来进行分析。
简化SQL编写复杂度
比如上述查询最新订单的查询语句,需要分析人员正确理解如何提取最新数据。这里面涉及了一个不容易让人理解的开窗操作,并使得SQL更复杂了。
一个直接的解决方案是,对每张表的数据都建立一个最新数据的视图,查询最新数据的时候就无需关心这样的开窗操作。
对于订单,我们可以创建如下视图:
1 | create view order_latest_v as |
这样一来,查询某一客户的订单的SQL就变成:
1 | select * from order_latest_v where customer_id = '{QUERY_CUSTOMER_ID}' |
这一查询就比之前的查询简单很多了。对于数据分析师而言,他们就可以更高效的完成这类分析工作。
提高SQL查询性能
上述SQL在实际运行过程中可能会比较慢,主要是开窗和排序操作可能带来较多的数据shuffle(为了完成排序,各个子任务执行器需要相互传递数据)。
在我们的测试环境(1TB内存,100核)中,使用Hive对于一个大约1亿数据量200个字段的事实表进行查询,其响应时间超过了5分钟。对于数据分析师而言,这样的性能无疑将大大降低数据分析的效率。
所以很有必要从技术上提供一种高效的主要以业务键(通常是ID)作为查询条件的查询。
有以下技术方案可以提升这样的查询性能:
- 对最新数据的视图进行物化,这样一来,耗时开窗和排序操作就可以预先计算好,而不是在查询时临时计算。这是一种典型的用空间换时间的做法。
- 采用更高效的技术方案。比如
Presto或Trino,由于特定的计算优化,它们对基于ID类的查询响应更快。还比如ClickHouse,由于查询时大量使用向量计算,在这一场景下,其性能比Hive或Spark高很多。
在实际情况下,我们常常可以综合考虑这些技术来设计技术方案。
提供特定分析工具
即便有了上述两点优化,基于SQL的点分析易用性还是不够好,因为分析师总是需要手动编写SQL来实现其查询。
仔细考察此类分析过程,可以发现以下模式:
- 主要基于业务键(如客户ID)进行数据查询
- 希望方便的查看更多列的数据
- 希望方便的找到关联的其他表的数据
- 希望能只查看最新数据
- 希望能看到数据变更
能不能基于这些模式来设计一个数据分析工具呢?
这个分析工具最好基于当前流行的web技术实现,以便用户直接打开浏览器即可使用。最好有一些便捷易用的功能可以支持上述分析过程,不用手动输入SQL进行查询,只需点击按钮或输入少许信息即可。
数据浏览器
事实上,前面提到的提高点分析效率的另外两点方法也可以受益于一个专用的Web分析工具。
主要的益处在于,有了分析工具,对于数据分析师而言,就无需关心底层实现机制了。用于获取最新数据的视图或物化视图,以及这些数据的存储位置,对于数据分析师而言都是透明的,他们只需要关注在数据分析这件事情本身上面。从这里的分析可以发现,整个点分析过程将能得到巨大的效率提升,从而更快产生价值。
如何设计实现这样一个数据工具呢?
交互设计
从数据分析师的用户旅程和使用场景进行分析,我们可以据此设计出点分析工具的交互流程。
对于最简单的数据搜索场景,可以分为以下几个步骤完成,即:
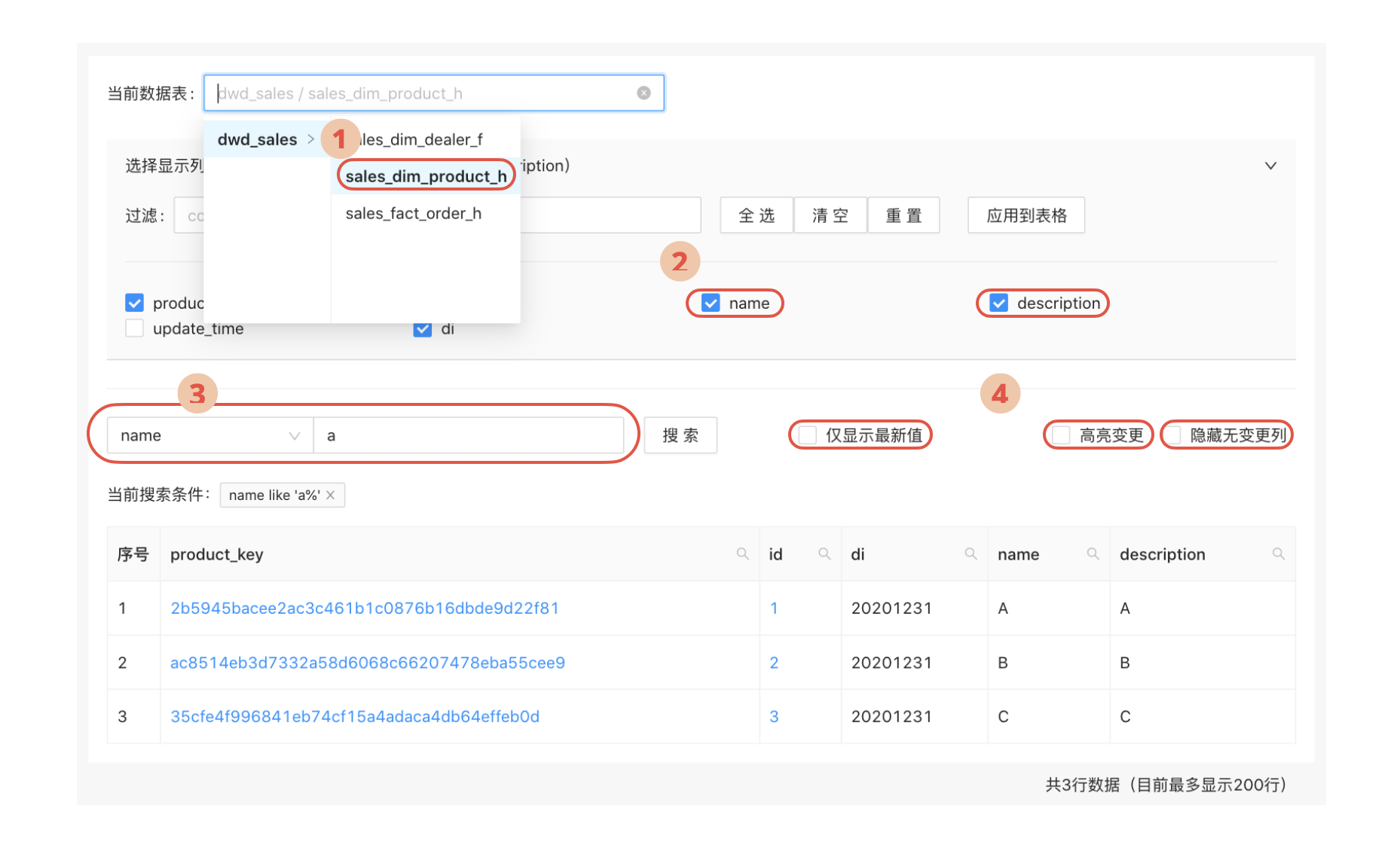
- 选择需要分析的数据表
- 选择当前分析所关注的字段(有一些数据表的字段非常多)
- 输入字段筛选条件
- 点击查询,即可在表格中显示数据
对于查询最新数据的场景,可以在搜索框附近设置搜索属性,这可以通过一个名为“仅显示最新值”复选框来实现。选中此复选框之后,获取的数据将不包括历史数据。
点分析还会关注某一条数据的变更情况。比如,分析订单状态的变更,可以知道该订单的实际业务流转情况。
这也可以通过设置搜索属性来实现。同样,可以设计一个名为“高亮变更”这样一个复选框,当分析师选中了这一复选框之后,搜索结果将高亮显示每一条数据的变化了的字段。
如果字段过多,可能会出现很多分析师不关心的无变化的数据列,此时如果可以有一个功能隐藏这些列就不错了。这一特性同样可以通过复选框来实现。我们可以设计一个“隐藏无变更列”复选框来实现。
从用户体验的角度来看,还有一些可以纳入分析工具的有用的功能。
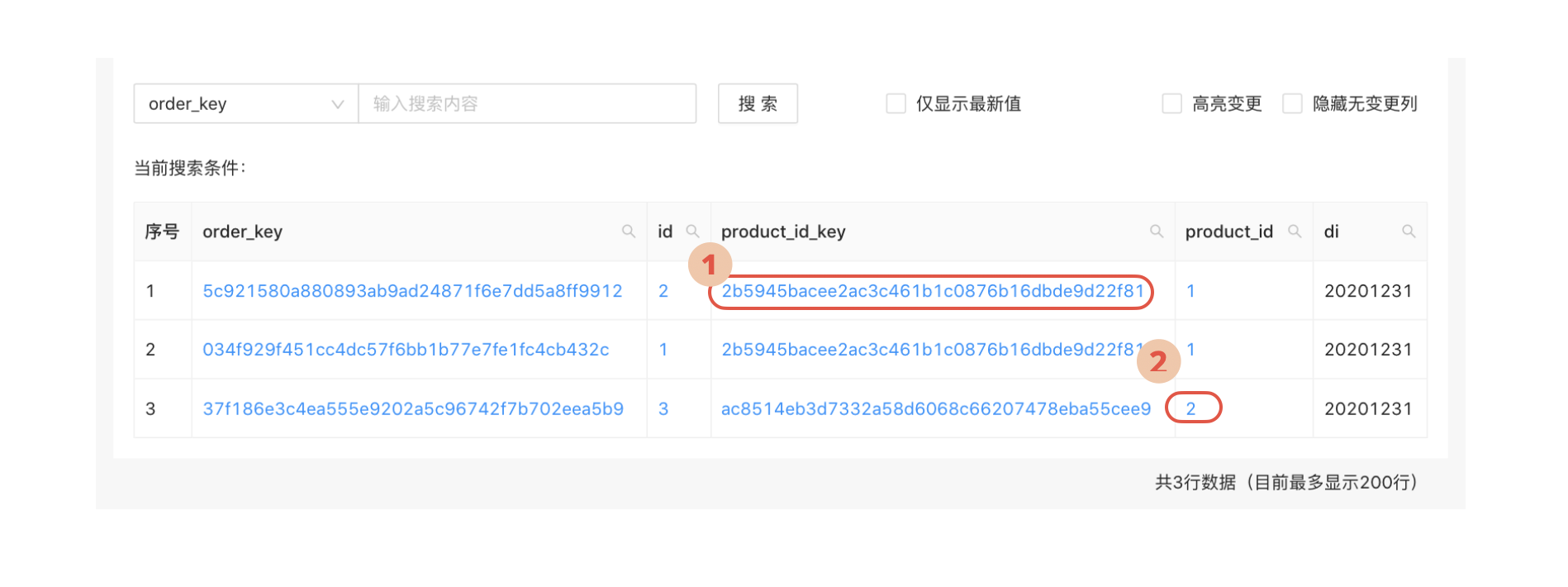
通过外键跳转到相关表的数据。
比如,订单表可以关联到用户表,在浏览订单数据时,自然希望可以跳转到当前订单关联的用户的信息。
这可以通过在数据表格中为对应列的数据加上跳转链接来实现。
同时,由于我们同时具备代理键和业务键的关联关系,最好可以在这两个字段中都支持链接跳转。
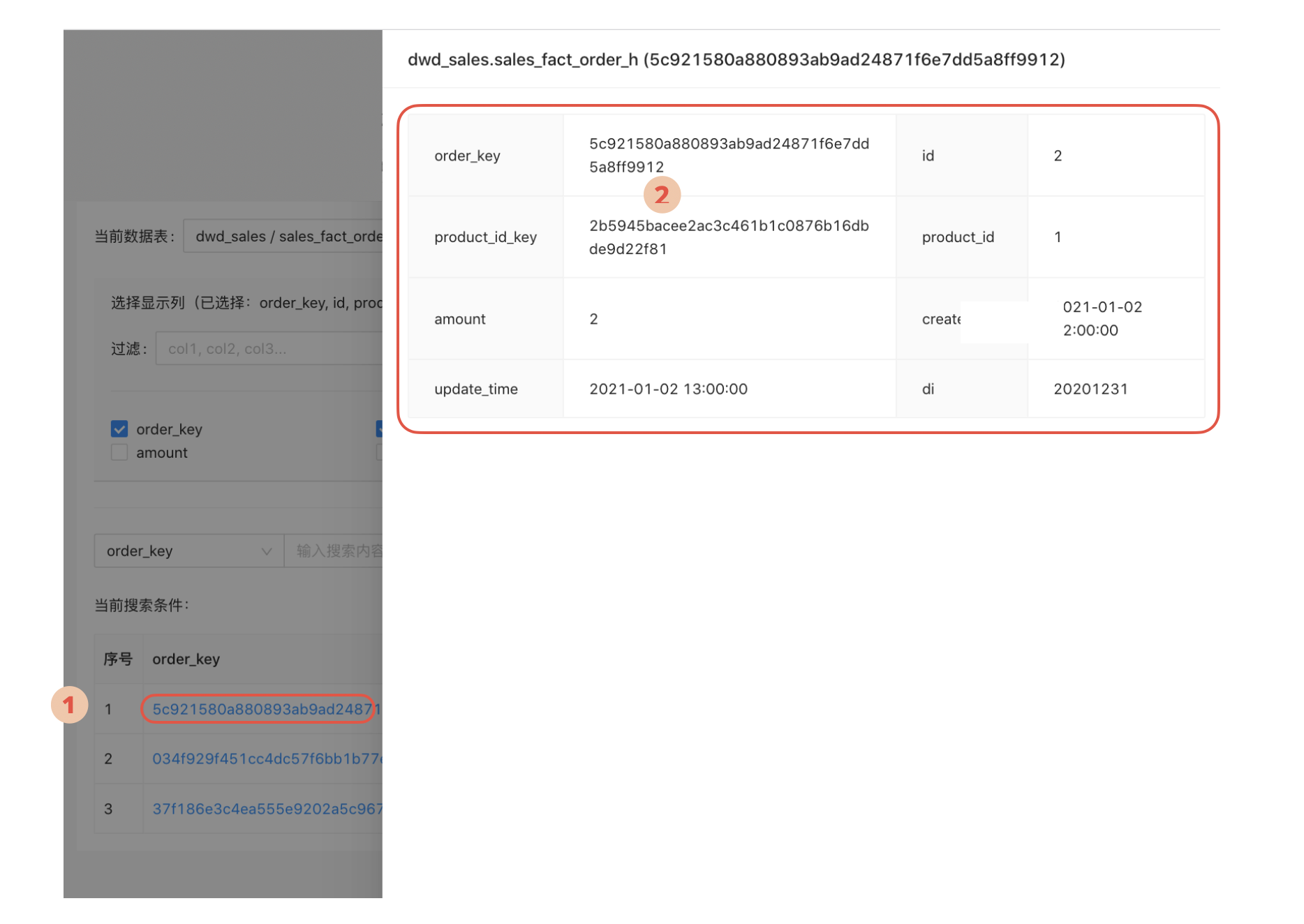
查看所有字段数据
在一个数据表格中展示所有列的数据将带来性能问题,并且显示和浏览都不太方便。
一个简单的想法是,可以在代理键数据列中支持链接,分析师点击此链接时,可以在页面旁边打开一个界面展示这条数据对应的所有字段值。
初始显示的字段
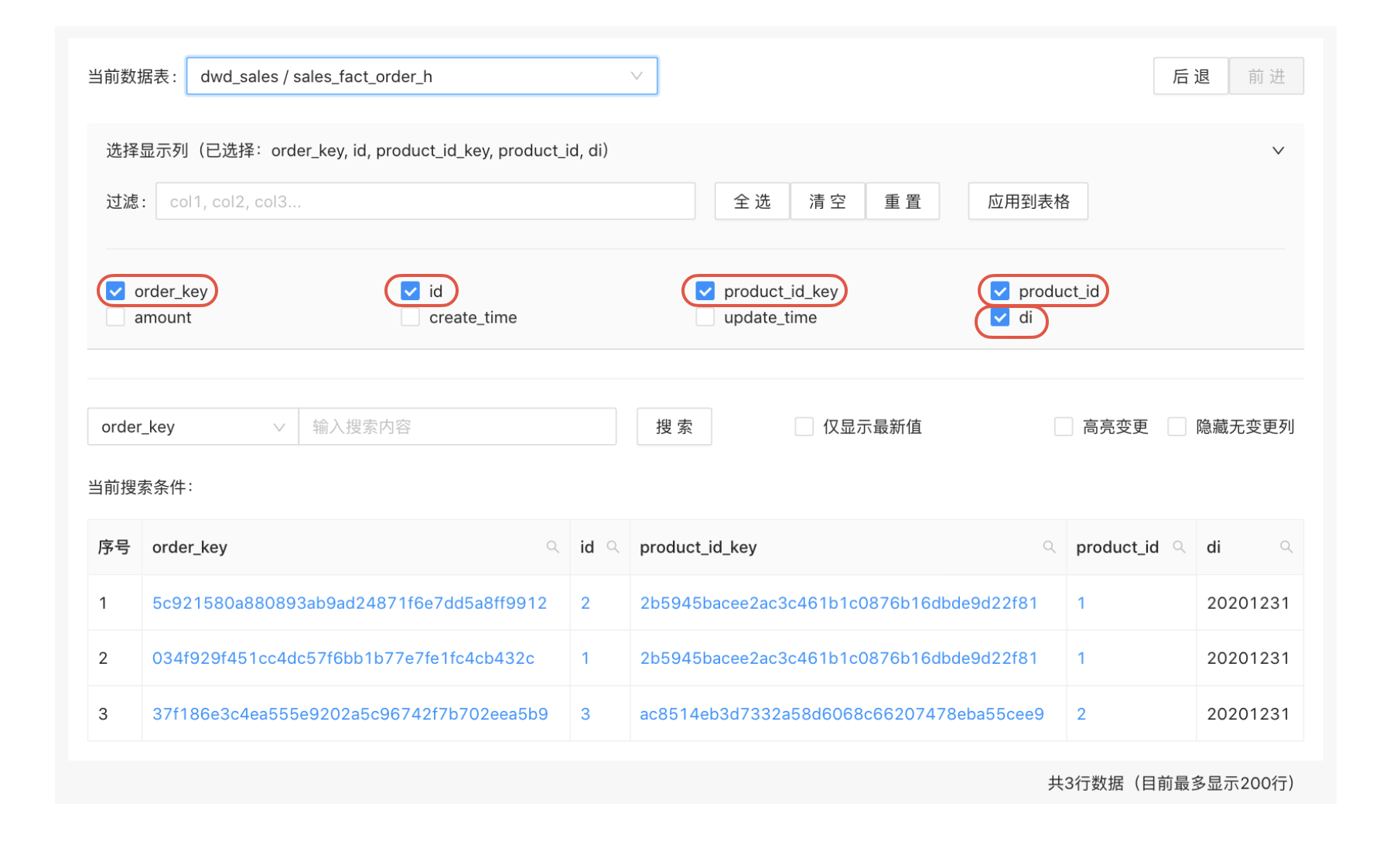
当一张表有数百个字段时,给出一个默认的字段选择将是一个很不错的功能。这些默认选中的字段应当是最常用的一些分析字段。
我们可以统计分析师的使用情况,将最常用的字段提取出来作为这里的默认字段选择。一个简单的统计是从ETL中分析使用到的字段,然后排序取TopN。
高效的选择字段
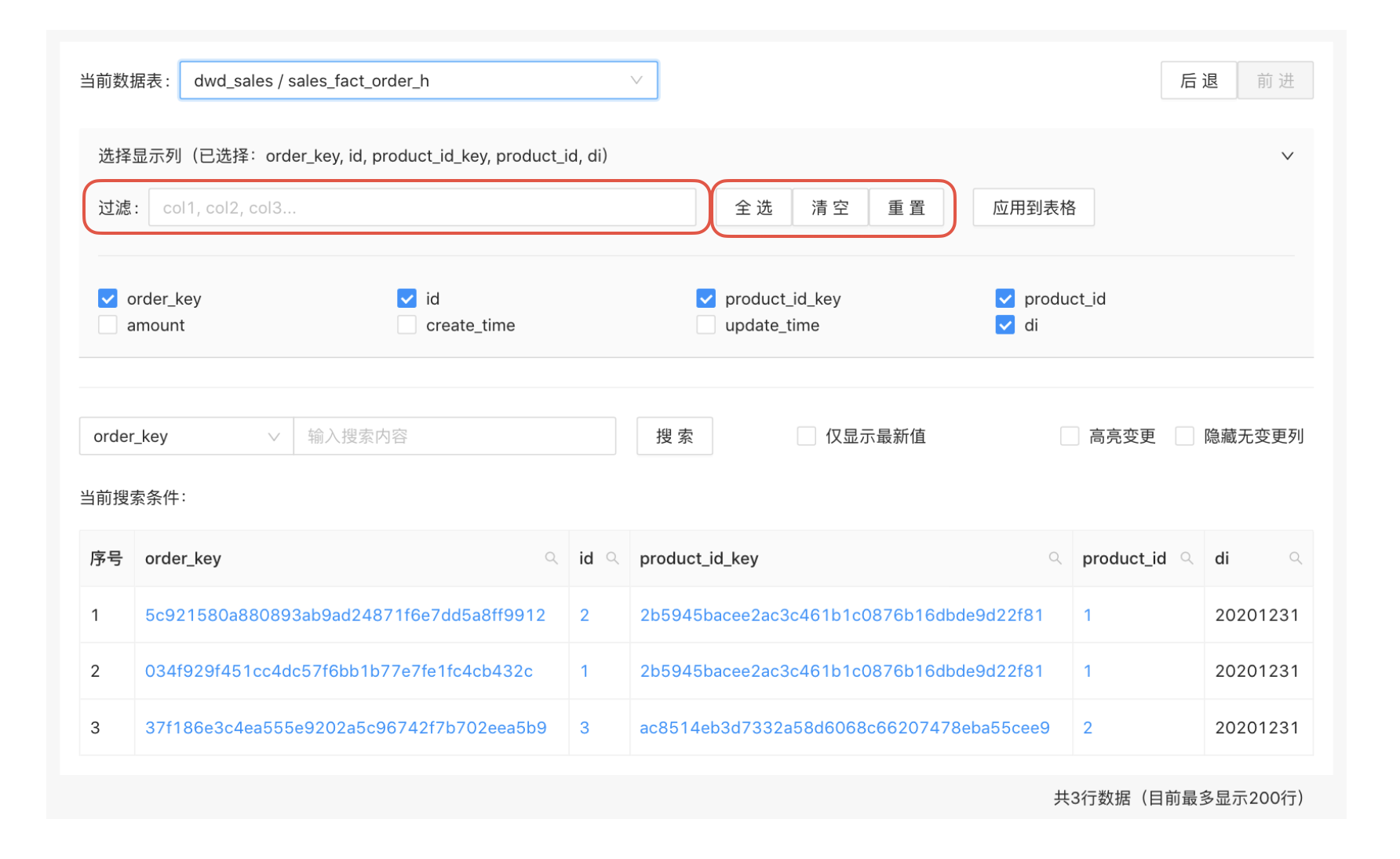
为应对表字段太多的问题,最好还可以优化字段选择体验,使得分析师可以高效的选择需要查看的字段。
这可以通过以下几个功能点来实现:
- 在选择字段的区域提供一个搜索框,分析师可以输入字段名来进行字段搜索
- 字段搜索可以支持多个字段的搜索,不同字段以逗号分隔
- 如果有搜索条件,字段列表将只显示搜索到的字段
- 提供“全选”和“清空”复选框,以便分析师可以全选或清空筛选出来的字段
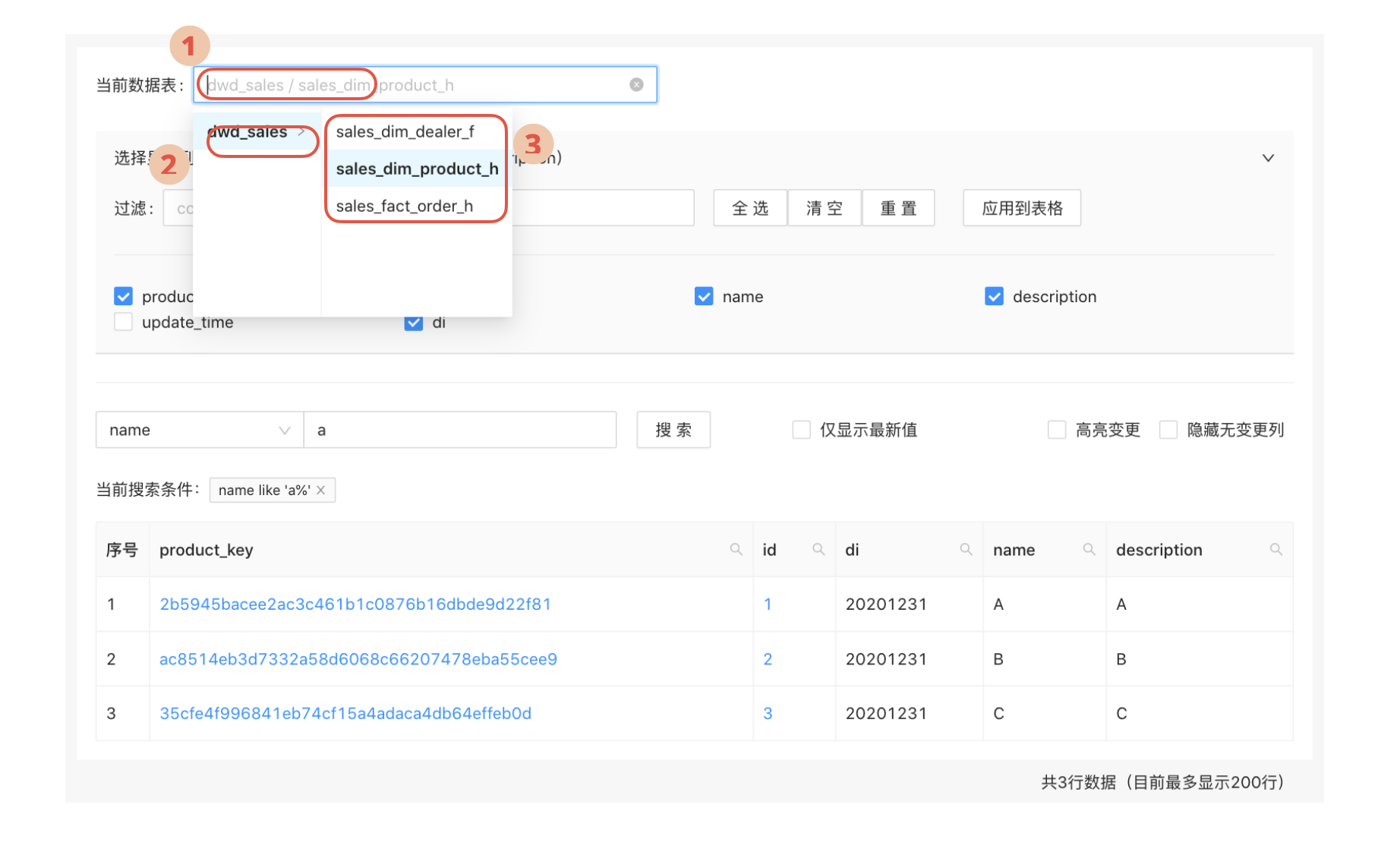
快速选择数据表
当数据表的数量很大的时候,想找到对应的表并切换过去是不容易的。
一个好的解决办法就是提供模糊搜索。可以在分析师输入一部分字符的时候就自动触发搜索,快速的过滤出包含这些字符的数据表。这可以提高分析师查找数据表的效率。
另一个可以增加的功能是,将数据表按照对应的业务系统进行分组。由于组的种类相对表的数量更为有限,这就可以辅助分析师找到想要的数据表。
我们还可以将数据表按照字母表进行排序,这也可以帮助设计师尽快找出想要的数据表。
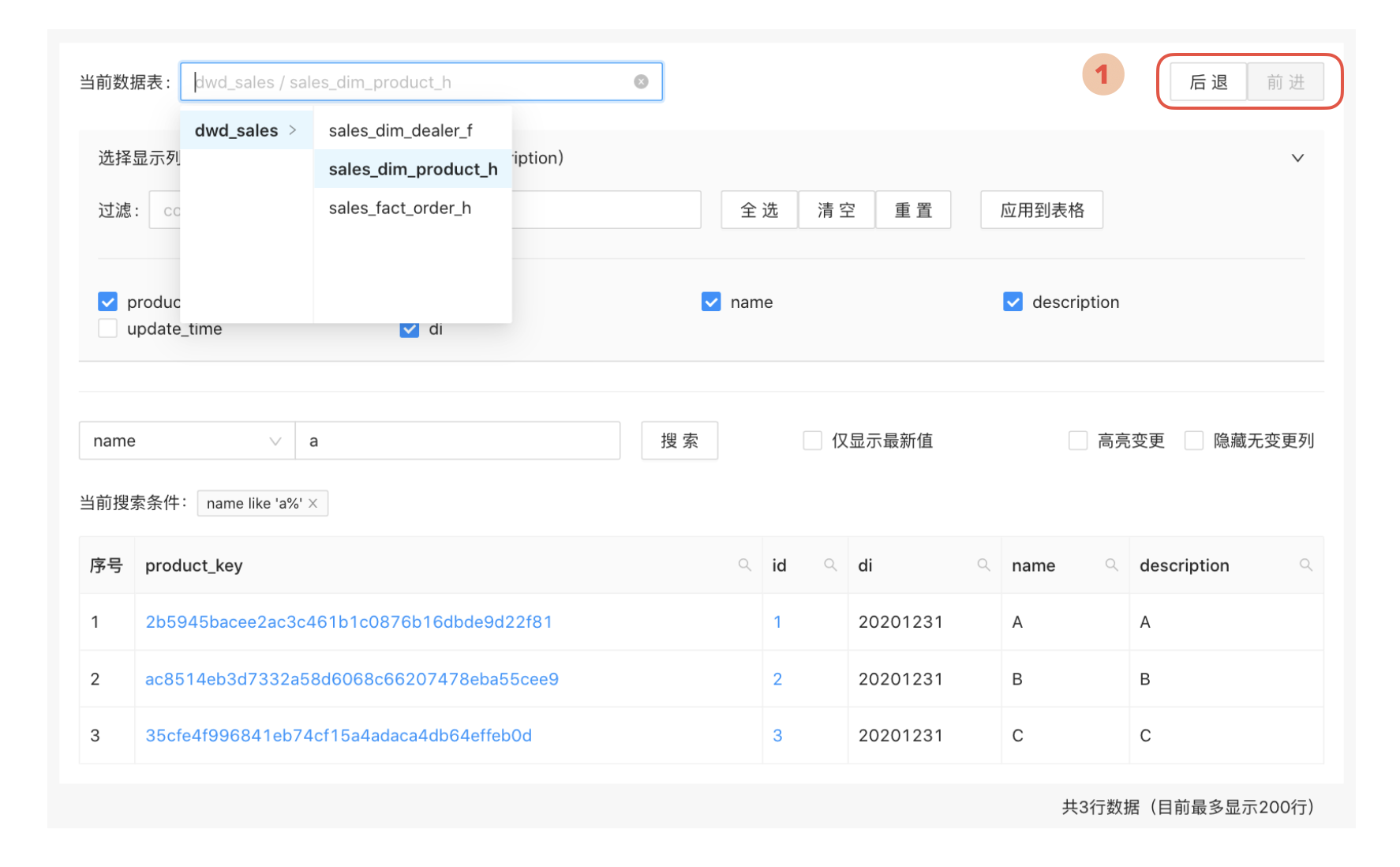
提供前进后退的导航
前面的功能点有很多是关于跳转的,如果分析师不小心点错了,跳转到了不想浏览的数据,如何恢复到之前的查询结果呢?
在系统功能设计上可以提供一个前后导航的功能。当分析师点击后退时,界面的搜索及选择条件均切换到之前一次刷新数据的设置。如果分析师没有在此时进行查询条件修改,那么还可以通过点击“前进”按钮恢复到刚刚保存的搜索选项。
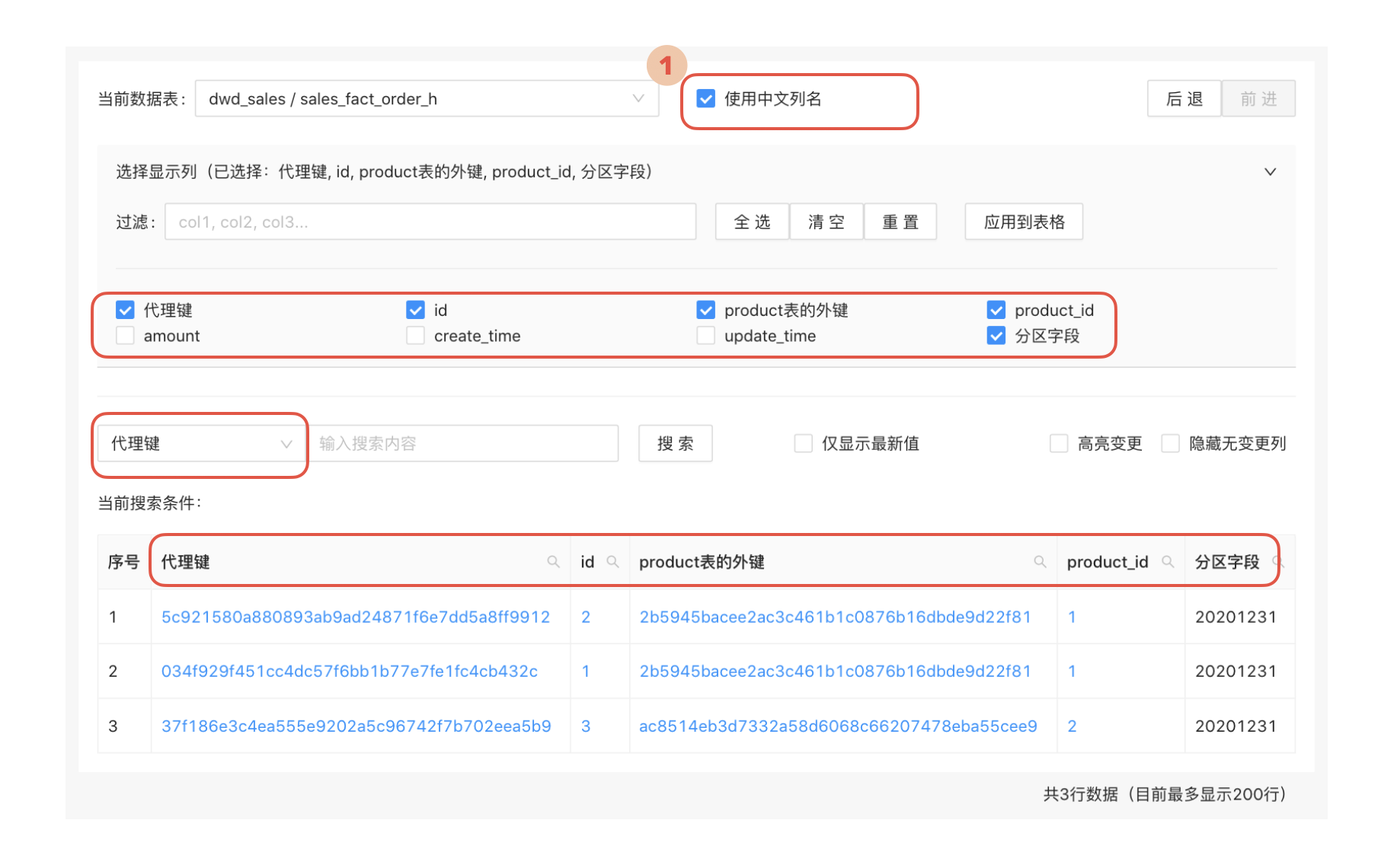
对字段的中文展示
对于数据分析师而言,虽然司空见惯在进行查询时使用英文的字段名,但是如果可以用中文的字段名作为辅助,将是一件喜闻乐见的事。
在设计系统功能时,可以提供一个切换语言的复选框,比如可以称为“显示中文”。当分析师勾选此复选框时,各处的字段名将以中文显示。
有了上面这些功能,相信这类点分析做起来就会效率很高了。由于此分析工具主要是完成数据浏览式的数据分析,我们可以将这个工具称作“数据浏览器”。要想“数据浏览器”好用,一个关键的技术要求是基于单表的查询要快速完成,一般而言,用户可接受的查询时间是秒级。如何从技术上进行支撑呢?下面来分析一下一些关键的技术设计。
技术设计
元数据的获取
“数据浏览器”的实现需要完善的元数据支持。回顾文章《数据仓库建模自动化》中的内容,如果我们采用了基于Excel电子表格来实现自动化的建模,那么电子表格里面就包含了数据浏览器所需的所有元数据了。这些元数据包括数据表的名称,字段的名称、描述,哪些字段是主键(包括业务键和代理键),哪些字段是外键等。
在实现时,可以直接读取建模电子表格的内容,然后提取所有相关元数据,再在浏览器端加载这些元数据进行网页渲染即可。
基于ClickHouse的方案
前面在讨论“提高SQL查询性能”时提到,为了支持高效的单表查询,技术上可以考虑采用基于Presto Trino 或ClickHouse的方案。
在我们的实践中,选择了ClickHouse的方案。它的主要优势是提供了基于Http的查询接口,这样一来,在实现时可以直接访问ClickHouse的查询接口,无需进行任何的服务器端开发工作。此时,SQL的构造直接在客户端中完成,甚至还可以提供一个展示SQL和拷贝SQL的功能,以便分析师可以保留这个查询在其他地方使用。
安全性
有人可能会担心安全性问题,毕竟SQL是从客户端发起的,这是不是给了恶意用户更多的攻击系统的可能?这个问题其实并没有想象的那么严重。我们可以类比BI工具或一些支持SQL的分析工具,它们的实现原理和安全性其实是一致的。
在客户端实现时,可以考虑提供一个输入框给分析师输入数据库连接信息及用户名密码,而不是直接由系统预置这样的信息。这样一来,数据安全控制就交给数据库来实现了。ClickHouse提供了较为完善的账号及权限控制机制,此时的安全性完全交给了ClickHouse来实现。
弊端
当前ClickHouse的方案也有弊端,一是需要额外多一个数据同步的过程,将数据从大数据平台同步到ClickHouse中,这带来了额外的维护负担和数据存储。另一个问题是,数据安全的控制也需要进行额外的配置。
对于数据安全,在实践中,一个值得考虑的做法是,将Ranger中的安全规则进行解析,然后将其迁移到ClickHouse中。比如,我们可以根据Ranger中的配置生成ClickHouse中的视图,然后只给分析师授予视图的访问权限,而不是物理表的访问权限。
这样做可以很好的应对安全规则少、粒度相对粗的场景(即用户共享同样的少数几套安全规则,或者基于少数的组进行授权)。但如果希望每个用户都支持一套独立的安全规则配置,则在实现时可能需要创建很多的视图,在管理上会带来一些不便。不过,由于安全规则配置和管理本身是一件比较麻烦的事情,相信大多数公司都不会将粒度做得太细,所以,这套方案应该可以解决大部分场景下的问题。
到这里,这个“数据浏览器”工具就跃然纸上了,经过上面的分析,我们应该可以较容易的实现这样一个数据分析工具。
总结
最后,总结一下全文。本文基于数据验证的场景提出了基于数据点的数据分析方法,接下来分析了如何实现这样的分析过程,以及如何从技术上支持这样的分析过程。接着,从设计专用的数据分析工具的思路出发,我们设计了一个基于Web的“数据浏览器”工具,它提供了丰富的功能,可以很好的支持“点分析”,可以很大程度上提高“点分析”的效率。最后,我们分析了如何从技术上进行“数据浏览器”的实现,对几个关键的问题进行了阐述。
事实上,还有很多其他的分析场景是可以从“点分析”中受益的,比如刚开始进行探索式数据分析时,“点分析”是一个很好的深入了解某一个业务场景的方法。经过技术分析可以发现,这一数据工具的实现也并不是难事。“数据浏览器”可以认为以较低的成本实现较大的价值的一个不错的案例。
在数据平台构建的过程中,我们常常需要根据实际需要来开发一些数据工具,以便提高效率。但这些数据工具的开发不能直接产生价值,所以,从精益的角度来看,应当评估其实现难度,不应一次性投入太大。这其中的平衡是不容易把握的,本位旨在以“数据浏览器”的案例与诸君共勉。