DORN模型的重现
DORN模型是在单图像深度估计问题上效果非常好的模型,18年刚发布的时候,就同时在KITTI数据集和ScanNet数据集上面取得了Robust Vision挑战的第一名。

为什么能大幅优于其他模型呢?论文里面讲得比较清楚,主要在于两个方面,一是基础模型能更好的提取特征,二是基于距离递增的序数回归损失函数设计。
基础模型这一块对于我们基本上还是一个黑盒,难以理论证明。现有的优化手段也基本上都是先实验证明有效,再尝试给出一个大致可信的理由。DORN的基础模型比较复杂,但是它真的会比我们常用的resnet或者inception更好吗?很难说。但是损失函数的设计不得不说是一个亮点,下面我们主要针对这一方面进行讨论。
问题理解
单图像深度估计(单目图像深度估计)问题本身其实是一个不适定(ill-posed)问题,就是说最终的预测结果不是唯一的,也不是稳定的,而是依赖于具体的条件。实际上可以有无限种3D环境可以产生同样的2D图像。但是对于给定的同样的摄像头,同样的拍摄焦距,我们大致可以认为这个问题的解是稳定的。单图像深度估计应用场景非常广泛,因为它可以直接实现基于图片的三维重建,成本非常低。
这个问题很早就已经开始有研究了,下面几篇文章从不同角度研究了这个问题:
- Depth Map Prediction from a Single Image using a Multi-Scale Deep Network (2014 NIPS
- Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture (ICCV 2015)
- Deeper Depth Prediction with Fully Convolutional Residual Networks(FCRN)
总体上看,对于这种深度预测问题,当前流行的处理方式都是采用与图像分割类似的模型进行建模,模型输入一张图像,输出跟原图同样大小的一维深度图。模型使用全卷积网络完成端到端的训练,速度快而且效果好。
在设计损失函数的时候,最直接的办法当然是把这个问题当成一个回归问题来处理,直接用平均绝对值损失(Mean ABS Error)或者均方损失(MSE)就可以了。但是这样往往收敛缓慢,而且难以正确捕捉局部相似的特征(对于同一个物体,其像素值对应的深度值一般是非常接近的),最终导致模型效果差。DORN创造性的提出了一种办法,将回归问题转换为分类问题,而且用序数回归的方式捕捉各个分类间的联系,从而既让模型加速了收敛,又提高了精度。具体是如何做的呢?
离散化

要将回归转化为分类,其实很简单,我们只需要对连续的深度值做一个离散化处理就行了。比如KITTI的数据集中包含了0-80米的深度值,我们可以将这些深度值分别映射到8个类里面,0-10米算分类1,10-20米算分类2,依次类推。离散化之后,每一个像素值的标签就变成了一个分类标签,我们就可以将问题转化为分类问题了。这种简单的离散化方法,我们可以称其为平均离散。平均离散对于我们这个问题是否有效呢?细想一下就会觉得这种方法不适合我们深度估计的场景。参考上图,两辆汽车,都离摄像头比较近,它们之间也比较近,它们占据了大量的图像像素,这时我们可以容易的估计出两个物体有多远。同样是两辆车,保持差不多的距离,但是都离摄像头比较远,由于远的物体占据的图像像素数量少,我们难以估计两个物体的相差多远。从这里我们可以得出结论,离摄像头较近的像素,由于从图像中得到的信息更多,估计结果应该更准确,而离摄像头较远的像素,估计结果会比较不准确。也就是说事实上我们可以允许较远的物体更多的分到同一个类,而较近的物体应该尽量用不同的类去近似。如果使用平均离散的方式,其实是忽略了这样的事实,因为它只关注到了深度的绝对差值,而忽略了深度值本身大小带来的影响。更好的离散化方式是怎么样的呢?DORN模型提出了一种按距离增加的离散化方式:
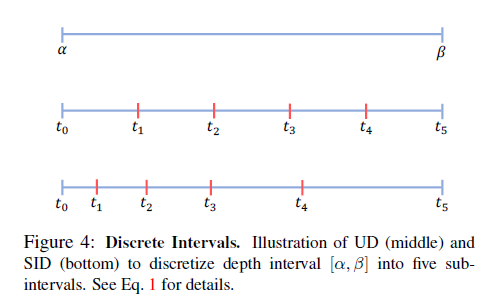
对应的离散点计算公式是: t[i] = e^(log(a) + (log(b/a)*i/k)) 我们可以称这种离散化方式为指数离散。采用指数离散,更符合图像实际情况,可以让模型更容易的收敛。
现在我们得到每个像素的分类了,是不是我们可以直接用Softmax交叉熵损失来作为损失函数了呢?当然是可以的,但是如果直接用这种方式,效果可能是不够好的,因为对于Softmax分类问题,我们实际上是将每个分类当做完全独立的分类去处理的,任意两个分类间都没有关系。我们的问题却不是这样的,我们的问题中,邻接的两个分类是明显的递增关系。用Softmax建模时忽略了这种重要的关系。如何在损失函数中反映出不同类间的这种递增关系呢?那就是序数回归损失了。
序数回归
什么是序数回归?参考wiki,我们可以了解到,这种回归方式是用于预测一个序数变量,比如对于商家的1-5星评分就是这样的一个序数变量。序数回归具体如何做呢?下面这个与Softmax的比较可以说明这个问题。
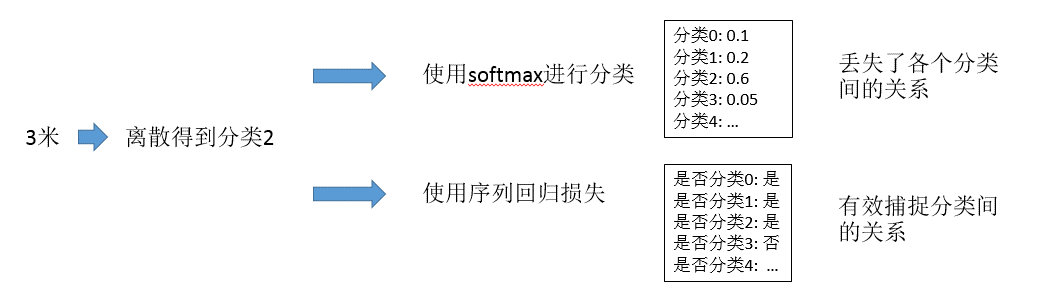
也就是对于每一个类,我们用一组相互间有关系的数去表示。分类1用[1 0 0 0 0],分类2用[1 1 0 0 0],这样就建立起分类间的关系了。
有了上面的基础知识,我们就可以用下面的公式来计算序数损失了。
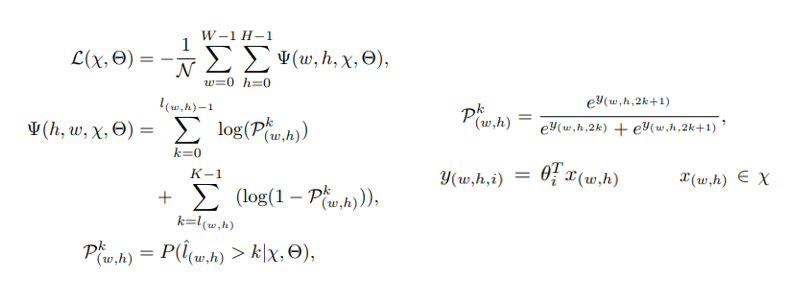
如果大家熟悉Softmax的计算公式,那么对于这个公式应该很容易理解,几乎就是它的一个变形。这里就不赘述了,想了解细节,大家可以参阅原论文。
弄清楚了DORN的主要改进方法,我们就可以着手在我们的模型上面去实现了。我们先构造一个UNET模型,将UNET的输出的channel数量设置为2K(K为我们预先设定的分类数量),然后将这2K个数按照上述公式进行计算就得出损失了。损失函数实现代码如下:
1 | class Discretizer: |
需要注意以上的实现充分的利用了tensorflow提供的API,以便我们可以有高效内存占用,并可以高效的在GPU上进行并行计算。主要用到的几个不常用的API是tf.searchsorted, tf.broadcast_to, tf.get_shape, tf.get_shape。
改进效果
我们的改进效果如何呢?
DORN论文中的结果:

我们的结果:
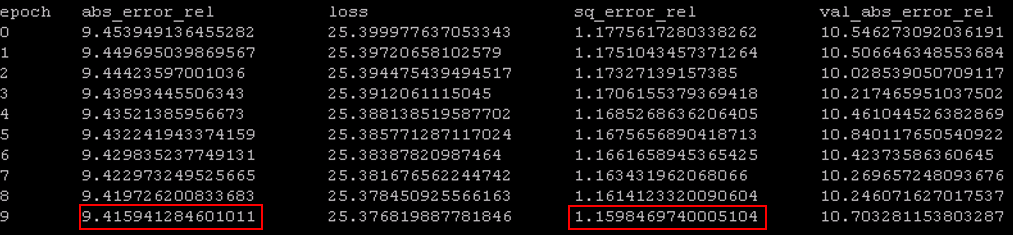
从结果来看,abs_error比论文低0.6个百分点,sql_error却比论文高1.1个百分点,证明了我们理解的正确性。同时我们的实验中基础网络使用resnet50,如果用resnet101, resnet152理论上会更好,而且网络看起来还能继续优化,只是时间关系和资源关系我们没有继续训练。另一个是计算效率的提升,在同样的机器上面运行模型,预测时间我们只需要6秒,而DORN需要20秒以上。我们的优化基本上达到了产品可用的程度。