最近在研究生成对抗网络,也对内对外做过一些分享。这里把分享过的内容整理一下,如有不对的地方,欢迎留言指出。也欢迎大家留言交流。这里是关于生成对抗网络的第二部分。第一部分在这里
上一篇中介绍了GAN的历史及发展,详细研究了GAN的模型和思想,还用tensorflow做了一个简单的实现。这一部分我们将看看GAN模型在近两年取得的进步以及未来可能的发展方向。同时,我们还会在上一次实现过的GAN例子上面,做一些增强,让GAN可以根据我们的需要来生成图像。
LP GAN与DC GAN
自GAN提出以来,对于它的研究就从未中断过,有另外两篇比较有代表性的论文,这两篇论文里面描述的模型基于GAN的基础模型而来,但是都做了很大的改进。这两篇论文提出的模型就是LP GAN和DC GAN,接下来我们一起来看看它们都有那些改进。
什么是LP GAN
LP GAN的全称是 Laplacian Pyramid of Adversarial Networks 也就是拉普拉斯金字塔对抗网络。它发布于2015年6月,是以 facebook 的AI研究团队为主发布的。论文里面描述了一种递进的结构,看起来很像是金字塔,所以名字里面就有金字塔。使用这个模型, 我们可以用于生成高清晰度的图像。
LP GAN训练过程
下面的图像描述了 LP GAN 在训练过程中的结构图。
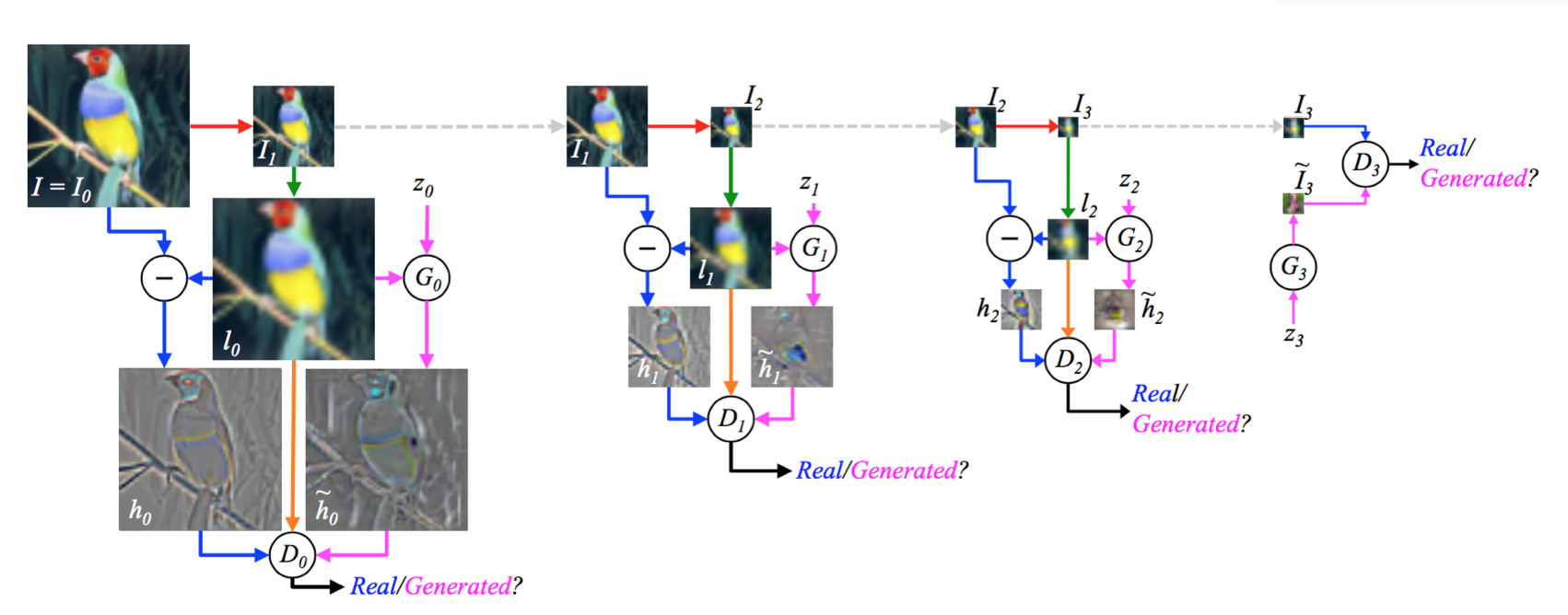
我们可以看到这个模型采用了三个类似的结构,并且他们首尾相连。最后再连接到一个基础GAN结构上。在训练过程中的数据流向采用箭头标示出来。
先观察左边的第一个结构,我们可以看到他的工作方式如下:
- 原图I0,经过一个降采样,将长和宽都缩小到原来的1/2,得到I1
- I1经过一个上采样恢复到原来的长和宽得到l0
- 将I0和l0做矩阵差之后得到h0
- h0和l0一起输入D0判别器,判别器此时应当输出为1,表示是真实的图像
- 同时,将l0和噪声向量z0一起输入生成器G0,得到h~0
- h~0和l0一起输入D0判别器,判别器此时应当输出为0,表示是生成的图像
上面的工作方式再循环两次,最后得到的I3和噪声z3一起作为最后一个结构的输入进行训练。
需要注意的是,这个模型中的每一层金字塔都是单独训练的。只是最后生成图像的时候,会联合一起工作。
G3和D3都很好理解,然而这里的G0学到了什么呢(由于G1和G2是和G0一致的结构,所以学习到的东西也是一致的)?通过我们上面对训练过程的梳理和分析可以知道,事实上,在G0网络足够强大的时候,h~0的分布应该会接近h0的分布,也就是说G0学到的是,如何生成一个矩阵,该矩阵的数据分布和矩阵 I0 - l0 数据分布一致。也就是说我们使用生成的矩阵和l0相加就应该可以得到原图。也进一步说明它和I1的上采样得到的矩阵相加即可得到原图。通过这里的分析,其实生成图像的过程就呼之欲出了。
LP GAN图像生成
下面我们看看LP GAN生成图像的过程。见下图:
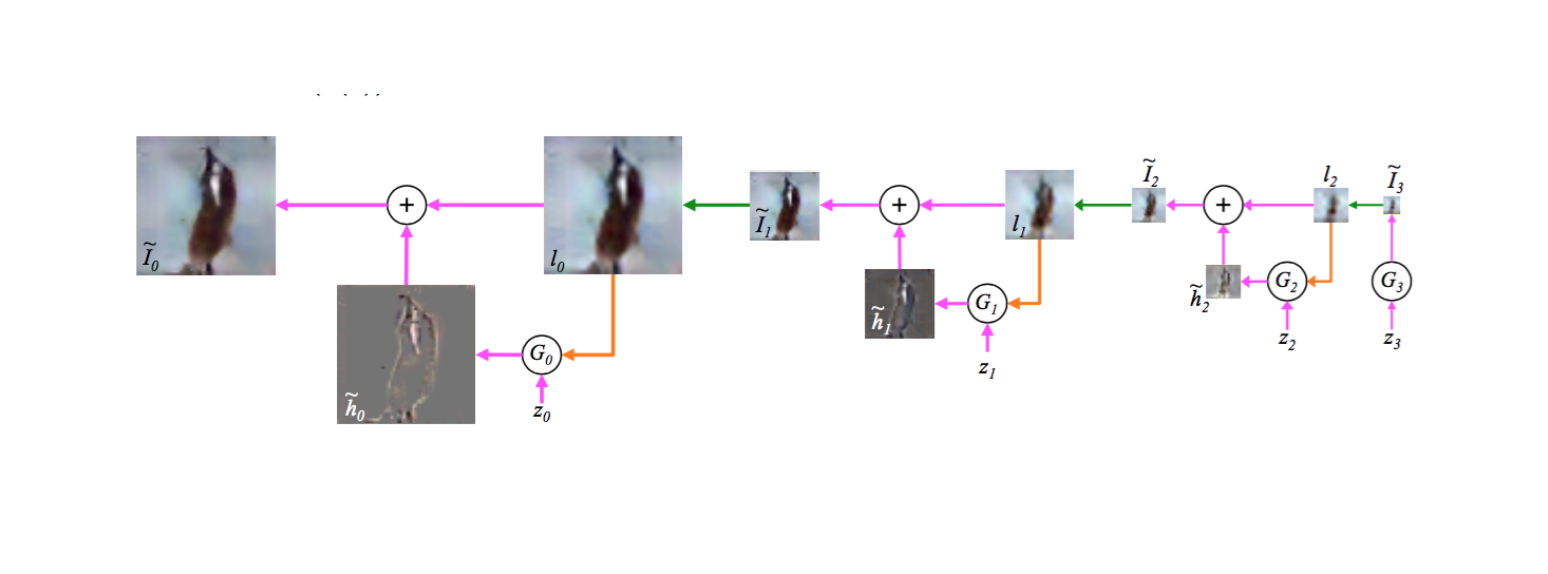
正如我们之前的分析,LP GAN的图像生成过程数据流向是和训练过程相反的。分析上面的图像,可以看到生成图像的过程如下:
- 噪声向量输入到G3生成I~3
- 将I~3上采样得到l2
- 将l2和噪声z2一起输入G2生成h~2
- h2和l2求和得到I2
- 在经过两个循环最终得到I~0,即生成的图像
可以看到,LP GAN利用了多个GAN的结构,不停的优化图像的清晰度,也就是这样,这个模型最后能生成一个比基础GAN质量更高,更清晰的图像。
对比LP GAN和基础GAN生成的图像
以下是LP GAN生成的图像和基础GAN生成的图像的一个对比,可以看到LP GAN有效的降低了生成的图像的噪点,提升了清晰度。

LP GAN的贡献
LP GAN除了能用于生成更清晰的图片之外,他还给了我们如下两个启示:
-
有条件的生成对抗网络:
噪声数据 + 构造的数据 --> 与构造的数据相关的结果
-
将 GAN 的学习过程变成了“序列式”
学习结构 —> 增加清晰度 —> 进一步增加清晰度
什么是DC GAN
接下来我们看看DC GAN。什么是DC GAN呢?DC GAN的全称是"Deep Convolutional Generative Adversarial Networks"。从这个名字可以看出来,这个网络很强调卷积的作用。这篇论文同样是以Facebook AI研究团队为主发布的,发布时间是2016年1月。这篇论文主要的改进是它引入了CNN在图像识别上面的研究成果,让GAN训练更稳定。同时他们还研究了如何可视化生成器和判别器,让我们可以了解到GAN到底学到了什么。同时GAN还研究了如何控制图像生成,就是如何生成想要的图片。
DC GAN的生成器网络结构
下图展示了DC GAN在LSUN卧室图片数据集上面进行训练用到的生成器的网络结构图:
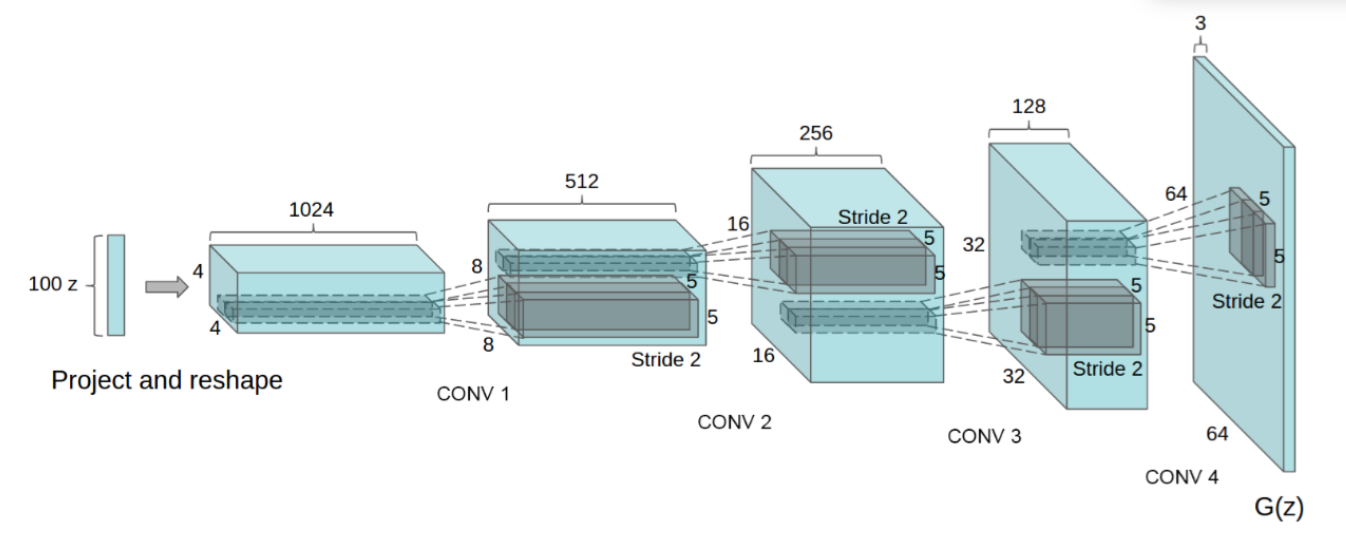
可以发现这个结构基本上就是一个设计良好的卷积神经网络分类器倒过来的结构。
除了这个图能反映出的部分优化之外,事实上这个网络结构所做出的改进如下:
- 没有全连接层
- 使用带步长的卷积层代替池化层
- 使用batchnorm进行规范化
- 在生成器中除输出层使用tanh外使均用ReLU激活函数
- 在判别器中使用LeakyReLU
这些优化方式都是在卷积神经网络取得的最新研究成果,都是被实践证明的非常有效的优化方式,按照这样设计的结构大大提升了GAN网络的稳定性。对比我们之前的代码里面设计的网络来看,事实上我们已经采用了大部分这里提到的优化措施。
可视化判别器学到的特征
那么关于GAN的可视化又是如何进行的呢?
我们先来看判别器的可视化。大家应该还记得之前讲过的 Neural Transfer 的内容吧?由于判别器也是一个典型的卷积神经网络,所以我们可以采用同样的方法来进行可视化,就是 guided back propagation:即选择某一些特定的层或者神经元来生成原图。然后观察原图,从侧面来看选定的那一层或者那一个神经元所学到的东西。
在经过研究之后,可以发现,判别器学到了和分类器中的卷积神经网络类似的层级的结构。如图:

可视化生成器学到的特征
同时作者的研究团队还做过试验来研究生成器学到的东西。事实上我们可以训练得到一些有趣的过滤器。比如我们可以训练一个过滤器,这个过滤器可以用来去掉生成的卧室图像里面的窗户。训练完成之后,在z向量上加一个全连接层,然后输入特定标注的数据,让生成的图像趋向于无窗户,这样就可以得到一个过滤器了。

如上图所示,第一排的图像是带窗户的,当应用训练好的去掉窗户的过滤器之后,得到的图像就如第二排所示了。可以看到,原本是窗户的地方,生成器采用其他的元素去替代了,比如门。
研究团队们还进一步研究了z向量的特点,发现z向量其实是可以进行类似词向量一样的向量运算。比如下图中,找到一个能生成“戴眼镜的男士”图像的z向量z1,再寻找一个“无眼镜的男士”的z向量z2和一个“无眼镜的女士”的z向量z3,当进行z1-z2+z3运算之后得到的z向量可以生成“带眼镜的女士”的图像。
DC GAN的贡献
总结起来DC GAN主要的贡献如下:
- 优化网络超参数
- 对网络学习到的特征进行研究和可视化
- Generator网络进行再训练,可以在生成的图像里面去掉某些物体
- Z向量的进一步研究,发现可以进行类似对词向量的做过的向量加减:
vector('King') - vector('Man') + vector('Woman') = vector('Queen')
根据文本生成图像
下面我们来看另一个有意思的问题,这个问题同样具有很强的实用价值。那就是根据文本生成图像。当然要实现一个一般的图像生成任务还是相当有挑战性的。这里的图像仍局限于训练数据的图像类型,比如某种花或者某种鸟。对于更一般的像是ImageNet的数据集,生成的图像质量还是会比较差的。
文本生成图像模型
在去年6月份的时候,以密歇根大学为主的一个研究团队研究了这个主题,他们发表的论文题目为"Generative Adversarial Text to Image Synthesis",即使用生成对抗网络来进行文本到图像的合成。

从上图中可以看到我们可以从左边的文本描述来生成右边的关于鸟的图像。生成的图像和文本描述里面的鸟的胸,冠还有羽翼颜色等都能较好的匹配起来。
我们直接来看一下他们用到的模型吧。
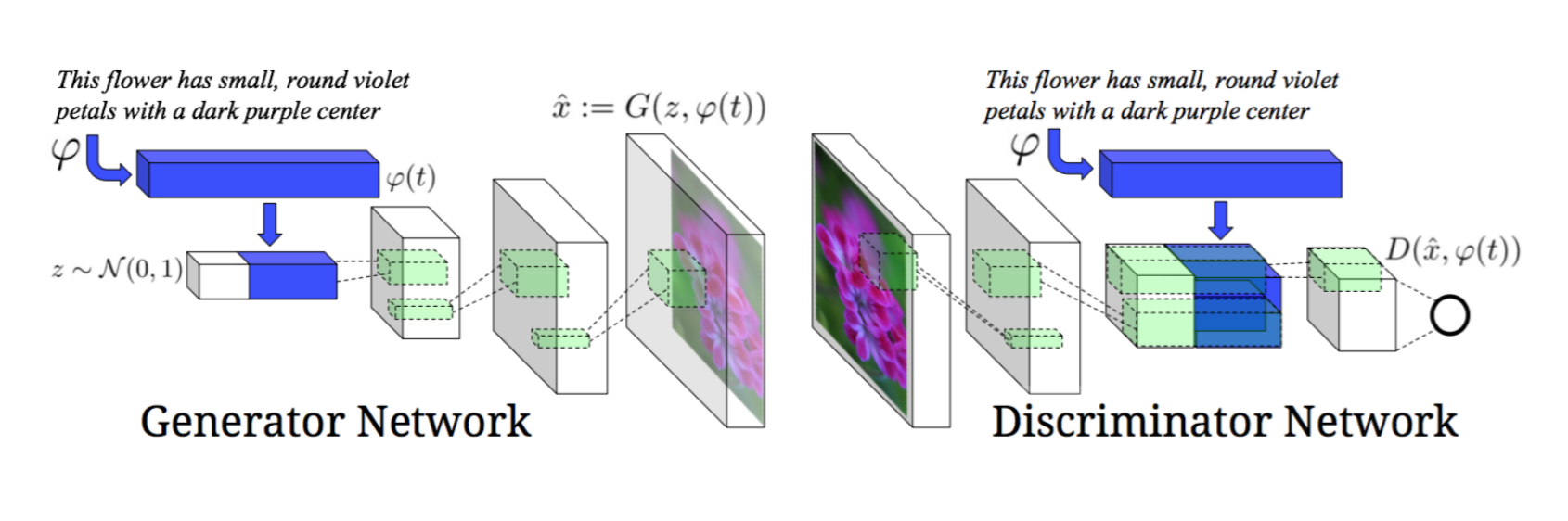
可以看到这个模型充分利用了有条件的GAN图像生成技术。事先将文本转换为一个向量,然后将该向量和噪声向量z一起输入生成器进行图像生成,同时在判别器的输出层的前一层,加入文本向量,之后经过最后一层输出结果。通过这样的方式,我们就可以生成与文本描述的相一致的图像了。
句子向量模型
上面的模型中提到了文本向量,那么这个向量是如何计算出来的呢?事实上我们同样可以采用神经网络进行训练得到一个文本向量模型,让这个模型能根据文本来生成文本向量。这个模型该怎么来实现呢?这里提供一种名为"Skip-Thought Vectors"的模型。采用这个模型需要对两个模型进行分别训练。事实上论文里面还提到一种端到端的模型,但是那个模型训练时间会更长。在这里我们暂时不提那个模型,有兴趣的同学们可以自行参考论文。
Skip-Thought Vectors 模型的结构如下:
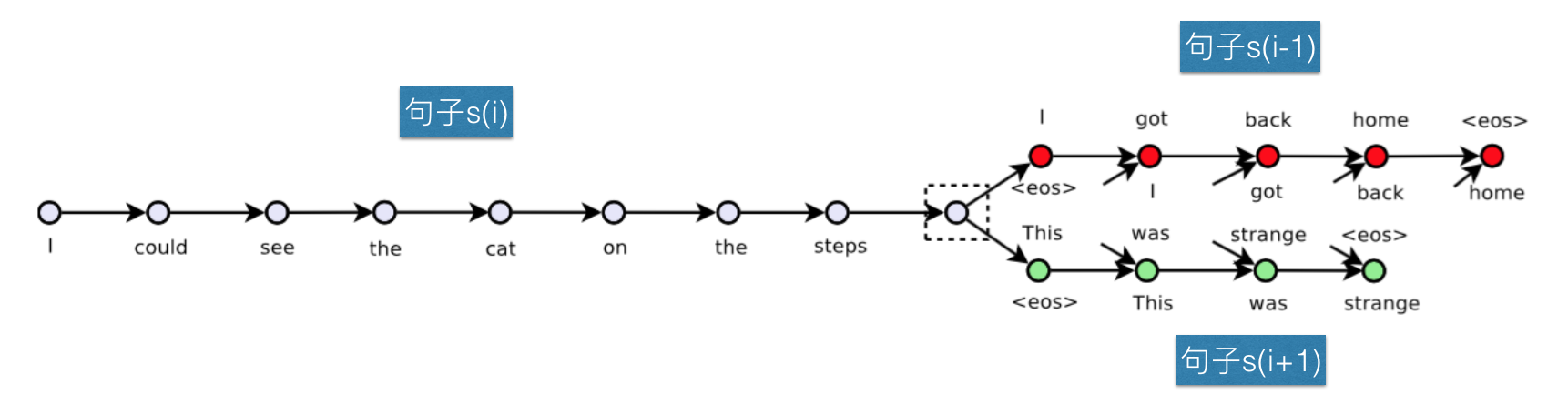
这个模型很简单,它的原理就是,使用rnn将句子映射为一个向量,然后尝试使用这个向量来预测与该句子想邻的句子。比如,我们有句子序列s(i-1) s(i)和s(i+1),将s(i)经过rnn之后编码为一个向量,使用这个向量来分别生成句子s(i-1)和s(i+1)。在训练足够之后,我们就可以根据一个句子的文本得到句子向量了。
分析过这个模型之后,大家是不是觉得似曾相识?我想应该有人已经猜到了,这个模型不就是跟我们之前讲过的Skip-Gram词向量模型一样的思路吗?是的,答案就是这样。可以看到,使用类比的方法,我们可以创造新的模型用于解决新的问题。
算法和数据
文本转图像模型还有一个值得一提的是它采用的训练算法和数据,训练算法如下:

注意到算法的第四步,在这里编码了一个不匹配的文本向量,这个向量将同时作为训练数据输入判别器进行训练,如第八步所示。同时需要注意在第10步时,将错误的文本向量得到的loss和生成的图片得到的loss求平均再与正确图片的loss相加得到最后的loss。
与普通的GAN不同的是,这里其实使用了三种数据:
- 真句子向量+真图 —> 真
- 假句子向量+真图 —> 假
- 真句子向量+假图 —> 假
其中第二类数据是我们自己构造的。构造这些数据将有效的增加我们的训练数据集。作者将这里的优化方式叫做"Matching-aware",即感知匹配的GAN模型,并将这个模型称为"GAN-CLS"。这种数据处理技巧,大家可以注意一下,如果以后遇到类似的问题,我们也可以尝试。
除了感知匹配的优化方式之外,作者还提到一种插值的数据优化方式。其想法是,由于句子向量也是可以进行向量运算的,那么我们可以通过句子向量来合成训练数据里面没有的句子向量,然后使用这些合成的向量进行训练。使用这种方式同样能增加我们的训练数据。使用插值方式时,我们要优化的目标是:
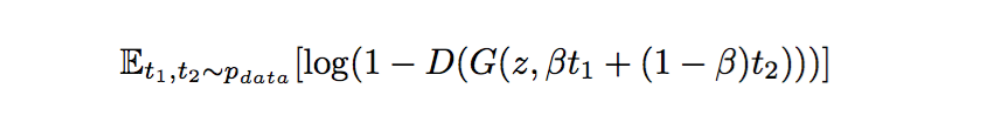
当我们构造好这些插值数据之后,判别器能否正常工作呢?事实上,判别器具有判别图像和文本是否匹配的能力,所以整个模型是可以按照预期的效果进行训练的。
代码分析和Coding
下面我们来分析一下文本转图像模型的代码,并尝试在我们之前的代码里面加入代码,使得生成器可以有条件生成的生成我们想要的数据,我们还将加入感知匹配的优化方式。
文本转图像模型的代码分析
这里我们来看一下一个GitHub上面的开源项目,这个项目实现了Text to Image模型,我们来分析一下该项目里面的源代码。代码地址在这里。该代码使用tensorflow实现,使用flowers数据集和mscoco数据集进行训练。在训练开始之前,需要使用一个脚本来生成文本向量,这个脚本将调用已经训练好的Skip-Thought Vectors 模型来将文本转换为文本向量。
我们主要关注一下模型相关代码。打开model.py,并定位到build_model函数。这里的代码还是比较清晰易读的,我们可以看到:
- 分别定义了用于存储真实图片和错误图片以及真实的文本三个占位tensor。这里的模型实现的是
GAN-CLS模型,所以定义了错误图片,这里的错误图片和真实文本之间将形成一个数据组输入到判别器进行训练。 - 定义了一个噪声占位向量z,并使用z和生成器一起生成图像
- 将三类(真实、错误、生成)数据输入到判别器,得到相应的logits输出
- 定义对应的生成器和判别器的loss函数
- 将定义的tensor保存到相关字典里面然后返回
我们再看一下生成器网络和判别器网络,定位到函数generator,可以看到:
- 文本向量经过一层全连接层之后和噪声向量组合
- 组合之后经过一个全连接层转换为转置卷积需要的维度,再转换为一个4维数据
- 经过4层转置卷积
- 用tanh作为激活函数输出
定位到函数discriminator,可以看到:
- 图像数据经过四个卷积层
- 文本向量经过一个全连接层,再进行维度变换,变换为和卷积层输出一样的维度,再和卷积层输出叠加
- 再经过一个卷积层和一个全连接层
- 用sigmoid作为激活函数输出
再打开train.py,我们观察训练过程,训练时,分别对判别器和生成器构造了优化器,分别优化不同的变量,这个过程与我们之前实现的GAN是一致的。迭代训练的过程也与我们之前实现的基本一致。
有兴趣的同学可以仔细研究一下这个实现,试试运行或者进行调优。相信对动手能力会有较大的提升。
条件GAN实现
下面我们来看如何在我们的模型里面增加功能,使生成器能有条件地进行数据生成。并且我们想要使用感知匹配的优化方式。完成这个功能之后,我们将能指定GAN生成什么数字。
打开我们之前实现的代码文件main_test.py,我们还是先从测试的角度来分析问题。首先我们要解决的问题是引入条件输入,修改测试test_generate为如下:
1 | def test_generate(self): |
事实上我们只修改了两行代码,一行是生成condition数据,另一行是将生成的数据喂入模型,期望能根据这些数据生成图像。这里我们生成的数据为0-9的整数,表示数据标签,由于噪声向量长度为1,我们这里就只生成一个数据。
在实现代码中,我们需要修改的代码如下:
1 | ... |
首先加入right_condition_input的实例变量声明并将其初始化为一个占位向量,然后将其传入函数_build_generator。在_build_generator函数中,我们需要先将条件向量进行正规化,然后在其上构造一个全连接层,全连接层的输出单元我们定义为200,这个值可以根据需要进行调整,这里我们设置为200,即噪声向量的两倍,需要注意的是这里的值不能太小,否则将没法有效的影响到生成的图像,也就是难以生成条件所限制的图像。之后再将变换之后的条件向量和噪声向量进行组合输入到下一个全连接层。
到这里我们的第一个测试应该可以通过了。
我们要实现的第二个功能是判别器网络。由于我们要实现匹配感知,所以这里涉及到真实的条件和错误的条件,我们先为真实的条件建立测试如下:
1 | def test_discriminate_real_with_right_condition(self): |
为了更好的表示其意义,我们期望模型输出重命名为discriminated_real_right_logits。为了让测试能通过,需要修改的代码如下:
1 |
|
与之前分析过的文本转图像模型一样,我们将条件输入进行变换之后,和倒数第二个卷积层的结果进行叠加。这里需要注意分析一下维度,以便能正确的进行叠加。修改完这里的代码之后,我们可以运行测试看看我们的代码是否能工作。
下一步是要增加错误条件的判别器代码:
增加测试如下:
1 | def test_discriminate_real_with_wrong_condition(self): |
这里的测试代码和前一个测试用例基本一致,只是我们为模型设计了两个新的实例变量,分别用来存储错误条件输入和相应的logits输出。
这里的实现就比较容易了,直接调用之前实现的_build_discriminator来生成判别器就可以了。代码如下:
1 | class GANModel(object): |
采用同样的做法,我们可以为生成的图片建立判别器输出。这里略过代码部分。
在模型定义好之后,我们就来看如何训练,我们可以同样采用先修改测试代码的方法来完成我们的功能。这里就简要分析一下我们需要修改的功能。
GANDataset类需要修改接口next_batch以便能同时输出真实的image,真实的条件标签和错误的条件标签- 将条件标签数据输入到网络进行训练
- 修改loss函数让它可以计算错误标签的loss
- 修改我们需要在tensorboard里面显示的数据(比较重要的是p_real,p_fake,p_wrong,即各种数据集计算得到的概率,可以有效帮助我们调试模型)
- 增加summary,来根据条件生成图像。
在完成代码之后,训练到第3000个step的时候,我们就将能从tensorboard上面看到根据输入条件生成的图片了。但是在5000 step之后,生成的图像会逐渐趋于一致,这表明模型已经有一定的过拟合出现了。大家可以自己动手去继续优化这个模型,加入其他的措施来防止过拟合。
完整的代码请参考这里。完整的代码中还包含了模型的存储和恢复功能,以及一个小的脚本用于读取模型生成图像。
GAN的最新研究及未来
在上面的分享中,我们研究了GAN的历史和发展,以及几个重要的GAN模型,也深入到代码实现去体验了这个模型的效果。那么近期GAN又有什么新发展呢?我们近期还发现了如下这些论文逐渐发布出来:
- Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning
- Learning Features by Watching Objects Move
- Adversarial-NMT
- Supervision via Competition: Robot Adversaries for Learning Tasks
第一篇和第二篇论文是关于视频预测的,视频预测也同样是一种生成模型,他们采用了另外的思路去看待如何生成图像。第三篇是微软和中科院一起发布的论文,将对抗的思想引入到了神经翻译模型中去。第四篇论文是google这个月刚发布的,将对抗引入到机械手的抓取学习中去。
从这些激动人心的进步中我们可以看到对抗模型的潜力很大,将来究竟会发展成什么样,我们拭目以待。
总结
总结起来我们分享了下面这些主题:
- 什么是生成对抗网络(GAN)
- GAN的提出和详解
- TensorFlow API与源代码分析
- GAN的实现 (Live coding)
- LP GAN与DC GAN
- 根据文本生成图像
- 文本到图像的模型代码分析
- GAN的最新研究及未来