今天给大家分享一个tensorflow的机器学习应用实例。我们将能看到如何针对特定的问题设计网络结构、设计损失函数,应用一些技巧来简化和拆分问题。还将演示如何将模型导出并部署到Android上,可以让我们感受到tensorflow强大的跨平台特性。
问题导入
提取门牌号进行地图标注
先让我们来看看我们要解决的问题。这个问题的应用场景来源于地图应用,如果能在地图上标注门牌号信息,这样就可以通过文本搜索找到地图中对应的位置了,事实上google地图就是通过训练这样的机器学习模型来进行地图信息标注的。要解决这个问题,可以读取google街景中的照片数据,然后训练一个机器学习模型来提取门牌号信息。如下图所示,当我们可以识别图片中的门牌号"42"了,我们就可以在地图上面进行标注了。

SVHN地图数据集
对于这一问题,斯坦福大学曾在2011年的时候发表过一篇论文进行研究,而且他们还整理好了一个名为SVHN的数据集,也就是Street View House Numbers街景门牌号的数据集。下图展示了这个数据集中的一些示例图片:

观察这些图片我们可以发现它们有以下这些特征:
- 门牌号由连续的纯数字构成
- 每个数字都有边框标记
- 数字有字体、颜色、大小的区别,甚至还有手写的数字
- 整体图片质量并不高,很多分辨率较低的图片,还有很多图片倾斜排列并有倒影
但是作为人类,基本上我们还是可以很容易的识别图片中的数字的。
有了这个数据集,我们就可以从研究角度出发开始我们的工作,而不必花太多时间在训练数据准备上面了。
目标应用
我们的目标就是训练一个模型来提取门牌号,当我们的模型在svhn数据集上面表现达到较理想的水平之后,我们还会将这个模型导出并部署在Android手机上面以识别来自摄像头的数据。

方案
在了解了问题之后,我们来看看如何解决这个问题。我们将看到卷积神经网络的应用和损失函数的设计技巧。
分为1000000个类进行识别
我们假定门牌号数字位数不超过5位,使得我们的问题得到一定程度的简化,实际上门牌号是很少超过5位数的。之前我们有一起解决过notMNIST的问题,训练了一个深度学习模型来识别印刷图片中的字母。它和这个问题有一定的相似性。从那个模型出发推广,一个简单而自然的想法是,我们能不能直接将不同的门牌号数字看做不同的类呢?如下图所示:
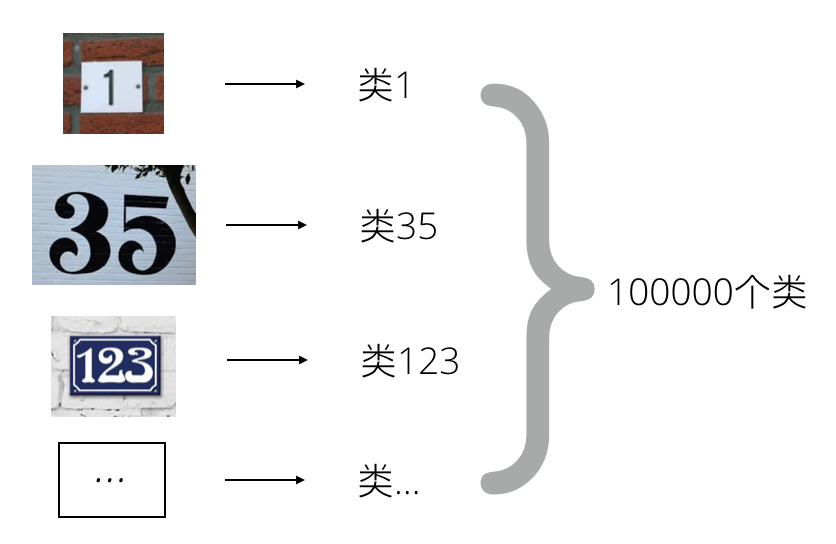
这样,如果包含数据0,我们将有100000个类。当门牌号的位数不超过2位时,这样的想法是可行的,因为我们将只需要100个类,在计算上不会成为问题。但是如果我们的门牌号长度限制设置为5位时,这样的想法就不可行了,因为类实在太多了,相应的训练数据和训练时长都会大大的延长。试想,就算对每一个类只有100条训练数据,总的需要的训练数据也将达到一千万。而且这样的模型在扩展上也是个大问题,每增加一个数位,都将导致数据和计算规模扩大10倍。
5个模型分别识别每一个位置上面的数据
既然类太多不可行,我们能不能考虑训练多个模型呢,如果我们有5个模型分别识别每一个位置上面的数据,然后再整合起来不就可以识别门牌号了么?如下图:
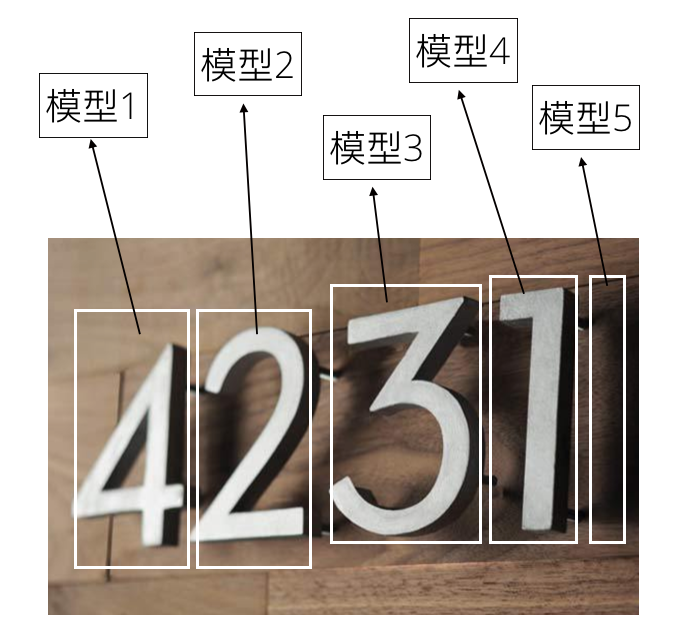
这是一个好想法,分为5个模型进行分别识别有效的解决了扩展性的问题,而且对于每个模型,问题也简化为了对单个数字进行识别,这就跟mnist问题一样。但是这样的方案还不是完美的,它的缺点在于5个模型之间可以看到存在很多冗余,其实模型之间只是数字的位置不同而已,数字都是从0到9这10个数。这还导致了模型数量比较多,运算慢,导出的模型比较大。
将5个模型合并为一个模型
如何解决上面模型的冗余问题呢?我们知道模型之间只是数字的位置不同而已,数字的特征是完全一样的,那么我们的解决方案就是在模型之间共享基础特征数据。具体来说就是共享由卷积神经网络所提取的特征。
这样的话,5个模型将可以合并为一个统一的模型,如下图:
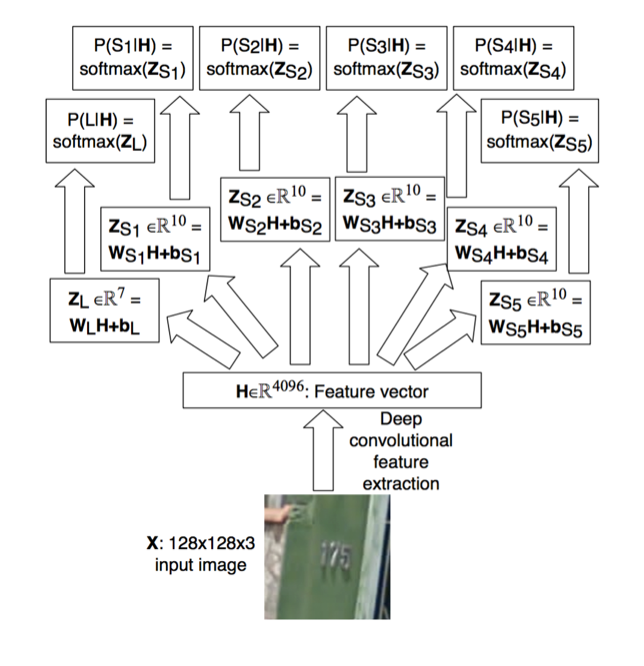
在这个合并后的模型中,我们首先使用卷积神经网络进行基础特征提取,然后将卷积神经网络的输出作为输入连接到各个模型的输出层。特别的,在这个图中,我们还增加了一个数字长度模型的输出,事实上不用这个输出也是可以的,我们只需要一个特殊的类表示当前位置没有数字就可以了。也就是每一个位置上的数字不再是0-9这10个类,而是0-10这11个类,其中当类为10时表示当前位置没有数字。也就是说门牌号23的标签将编码为[2,3,10,10,10]。
然而问题到这里还没有结束,我们还需要合适的损失函数才能完成我们的模型,有了损失函数我们就可以进行迭代训练了。这里的损失函数是什么呢,其实也很简单,我们只需要将总的损失定义为各个模型的损失之和就可以了:
总损失 = 长度损失 + 数字1损失 + 数字2损失 + 数字3损失 + 数字4损失 + 数字5损失
这样定义的损失,当我们在迭代训练时,模型就会尝试将总损失最小化,也即是将每一个模型的损失最小化,模型的正确率就会不断提高。这里每一个模型的损失我们可以直接使用前面用过的交叉熵损失函数来实现。
代码演示
在有了基本的方案之后,下一步就是实现这个方案了。我们将演示部分核心的代码,完整的代码将在最后提供一个链接,供大家线下进一步进行学习和研究。以下代码基于tensorflow的slim库来实现,slim封装了tensorflow的基础API而对外提供了一套更易用的API。使用slim,我们的模型定义及训练代码将会变得更干净整洁和易于理解。
卷积层,全连接层
以下是卷积层的代码:
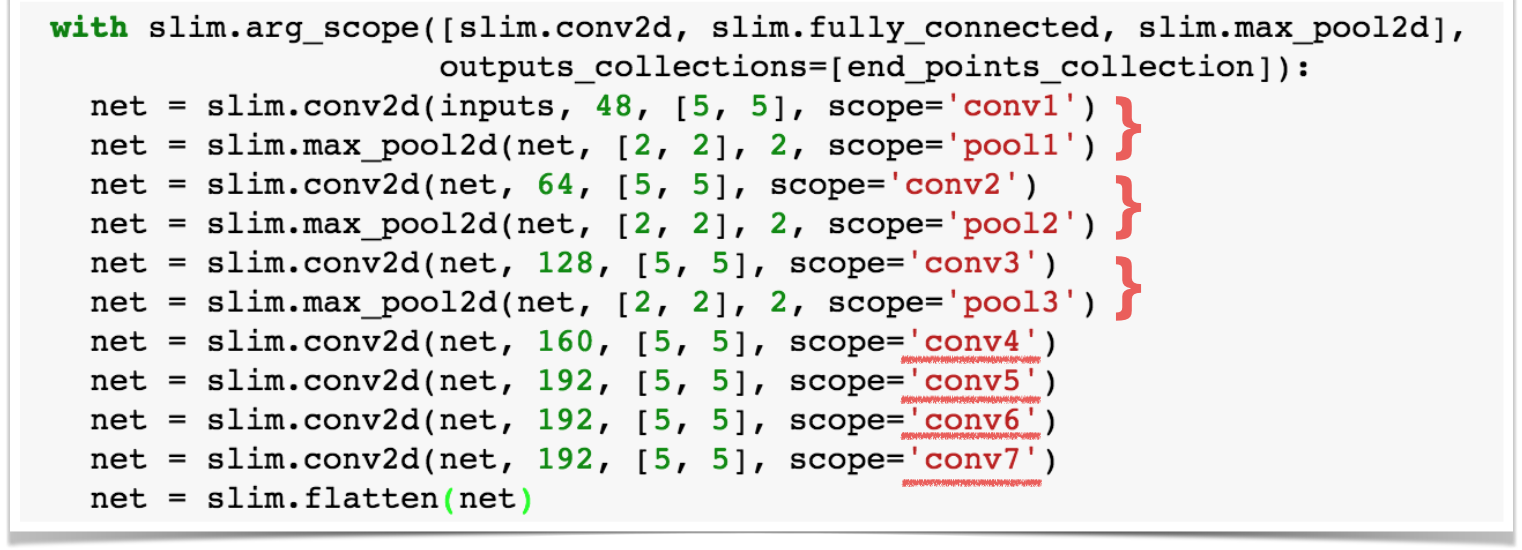
可以看到我们共定义了7个卷积层,在前3个卷积层之后,我们还分别定义了3个池化层。卷积层以5x5的区域作为过滤器进行卷积计算,最终的输出会将输入的3个通道转化为192个通道作为输出。
以下是全连接层的代码:

全连接层通过一个接口暴露出来,使用时,只需要传入不同的输出类的数目就好了。
网络定义,损失函数定义
以下是网络定义代码:
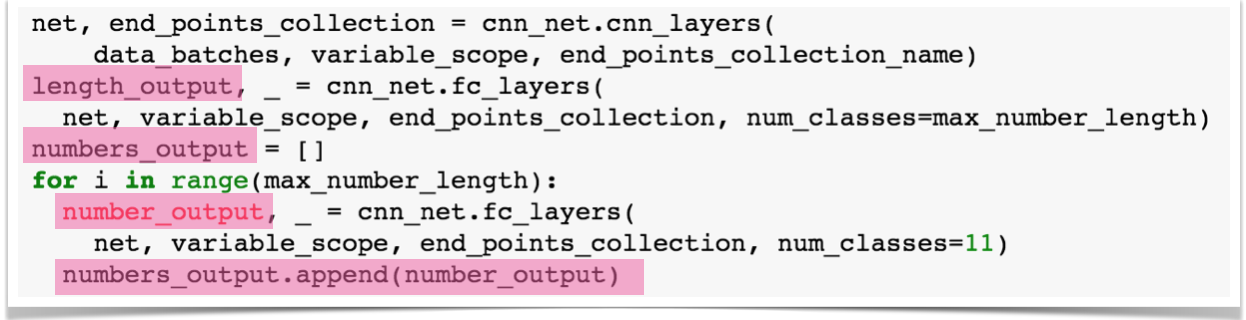
可以看到,我们使用了前面定义好的卷积层函数来定义模型的卷积层,使用全连接层函数来定义输出层,在数字序列长度限制为5时,一共有6个输出层,即一个长度输出层,将输出5个类,5个数字输出层,每个输出11个类。
再来看看损失函数定义代码:

对每一个输出,我们都使用了交叉熵损失,然后总的损失,就是各个输出的损失之和。
在定义好模型和损失之后,我们就可以开始训练了。整个训练过程大概会在半小时左右,取决于迭代次数设置。
在模型训练好了之后,下一步就是导出模型并在Android应用中导入模型和运行识别过程了。以下代码展示了如何使用tensorflow导出模型:

导入模型到android:

在Android应用中运行识别过程:

实际应用
接下来我们来看看在实践过程中的一些问题。
训练结果
在我们的实验中,在以batch_size大小为32,训练30000次迭代之后,总损失变化如下:
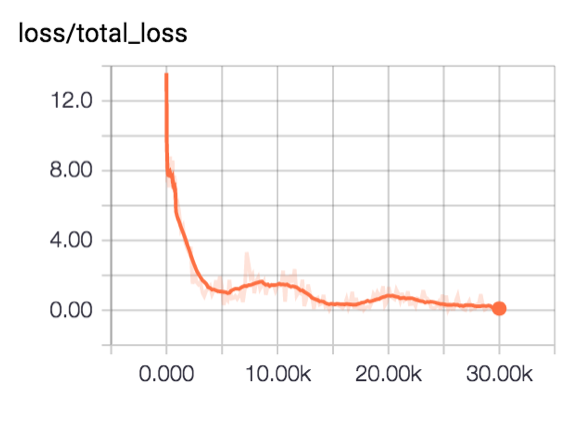
在测试集上面的正确率可以达到91%,如果增加训练集和迭代次数,模型还可能表现更好。
只训练边框(Bounding box)内的图像
另一个在我们的实验中遇到的问题是,如果直接把原图作为输入,模型将很难收敛到一个较好的值,原因是有太多的噪声像素了。
取而代之,我们的模型实际上是在数字序列的边框内部进行训练的,我们在处理输入数据的时候,会根据边框数据进行图像切割,之后才会输入到模型。在边框内部进行训练,我们可以得到90%以上的正确率。在这里大家也可以看到这个模型的局限性。
训练另一个模型,提取矩形边框
为了解决上面提到的模型的局限性,我们可以训练另一个模型用于提取数字的边框。对于这个模型,我们可以同样使用卷积神经网络来实现。
对于每一个输入图像,我们可以定义我们的标签为四个值,即一个坐标点(top, left)和图像的宽高(width, height)。
那么损失函数怎么定义呢?我们可以简单的定义如下的损失函数:
|top - top_| + |left - left_| + |width - width_| + |height - height_|
即每个标签值取差值的绝对值,然后相加起来就可以了。目前这个模型还没有达到一个理想的精度,大家可以线下基于现有代码进行优化。
精度不够
另一个问题是,当我们的模型精度不够时该如何处理?比如,我们上面的模型的正确率只有91%,而人类可以达到99%以上。这样的模型是不是不能在实际中应用呢?
当然不是,事实上,由于我们使用softmax函数作为模型的输出,我们可以得到一个概率分布,这个概率分布我们可以理解为模型的预测准确度。比如,如果我们选定的输出对应的概率值为0.3,虽然我们是得到了一个值,但是我们可以知道模型对于这个值不是很有信心。
在这样的情况下,我们就可以定义一个置信度阈值,只有当模型预测的输出的信心指数超过这个值,我们才认为是一个有效的预测。通过设置这样的阈值,我们可以把模型的正确率调整到99%以上。我们就可以基本上认为模型的预测都是正确的了。
在实际应用中,我们还可以将预测出的数据作为输入数据进行再训练,这样构成一个反馈循环,我们的模型表现就会越来越好。
总结
内容:
- 问题:基于街景图片提取门牌号
- 方案:共享卷积层,针对性地设计损失函数
- 代码:定义及训练模型 导出到Android并用于识图
- 实际应用:设计模型提取边框 在边框内训练门牌号模型 限定置信度
** 参考:**
- Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
- https://github.com/tensorflow/models/tree/master/slim
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android