前几天,我在跟一位做进口贸易的朋友聊天,发现一个很有意思的事情。
他们做的是国内的高端仪器进口的进口贸易业务。主要帮助销售国外产品的公司完成竞标、合同签订、物流、海关、进口贸易政策符合、维保等等事务。
我很疑惑,为什么会有这样的业务形态存在?为什么这些产品销售公司不自己处理这些事务,反而代理出去让其他公司赚钱呢?
前几天,我在跟一位做进口贸易的朋友聊天,发现一个很有意思的事情。
他们做的是国内的高端仪器进口的进口贸易业务。主要帮助销售国外产品的公司完成竞标、合同签订、物流、海关、进口贸易政策符合、维保等等事务。
我很疑惑,为什么会有这样的业务形态存在?为什么这些产品销售公司不自己处理这些事务,反而代理出去让其他公司赚钱呢?
数据平台的一个重要功能是数据集成。数据集成听起来是要从分布式走向单体,似乎不太符合当前技术领域要尽可能分布式的趋势。
但是,数据集成常常是必要的。这种必要性可能来自于企业战略上希望打破数据孤岛,也可能来自于某些数据分析需要跨业务线跨系统进行。
实现数据集成的一个重要问题是跨系统的数据关联。为什么这个问题如此重要?这还要从企业发展过程说起。
随着AI技术的使用日益广泛,在数据平台中进行机器学习建模分析成为了越来越常见的场景。
提到AI技术,不少人会直接联系到近几年特别火的基于人工神经网络的深度学习技术。其实,在企业业务中使用最广泛的还并不是深度学习,这是因为深度学习模型的应用领域常常是图像、音视频、自然语言处理等,而企业期望的应用领域多是销售、营销、客户关系管理等。另一方面,深度学习模型的可解释性比较差,难以从业务角度分析其合理性,这也限制了深度学习的应用。
一些常见的企业AI技术的应用场景示例如下:
在上一篇文章《指标计算实践》中,我们分析了指标开发过程,并给出了一些如何复用代码的建议。在一系列指标开发出来之后,如何管理好它们,使之容易访问,并方便的对外提供服务,这是数据平台建设中不得不解决的另一个问题。这里我们将这些问题统一称为指标管理问题。本文希望分享一些相关经验。
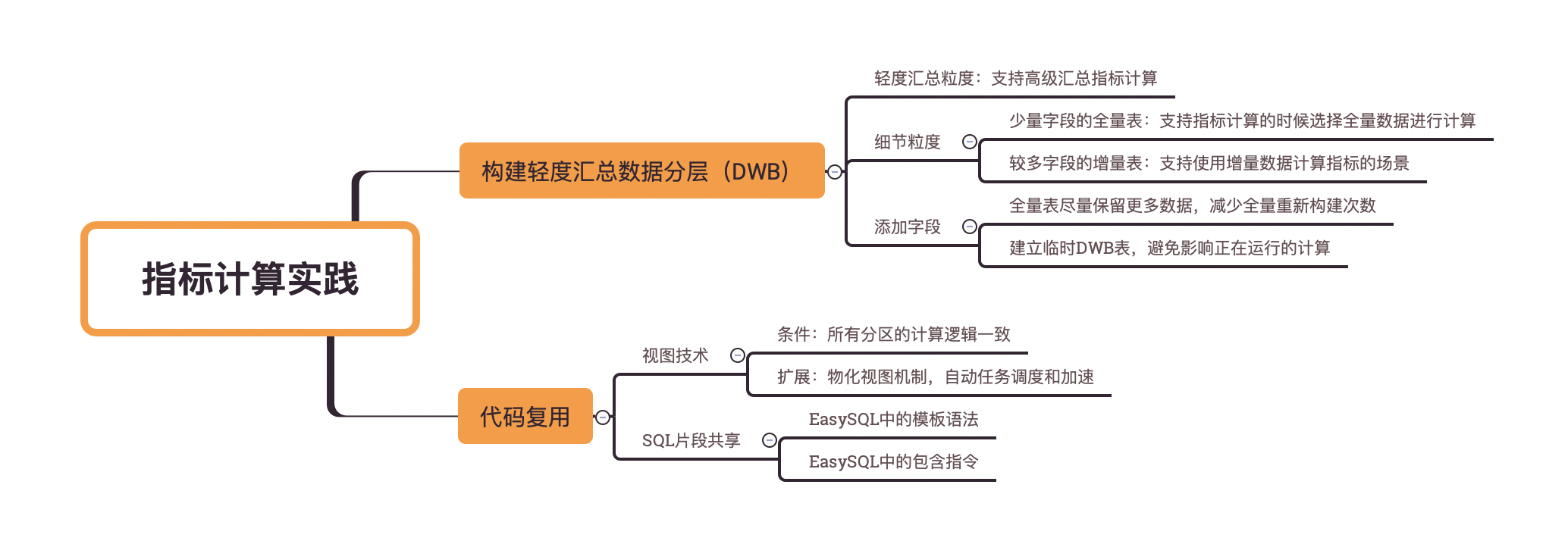
有了数据开发测试工具及DWD模型,数据开发看起来可以顺利往前推进了。下一步是数据开发真正产生业务价值的过程,即指标计算。前面的基础建设其实都是为了指标计算能高效高质量的完成。本文将尝试分享一些关于指标计算的实践经验。
在前面的文章数据平台数据管理实践中,我们提到了基础数据层(也常被称为轻度汇总层)。这一层一般以DWB的缩写来表示,其全称是Data Warehouse Basis。DWB这样的数据分层是业界常见的数据仓库分层实践,对指标计算有很好的参考意义。
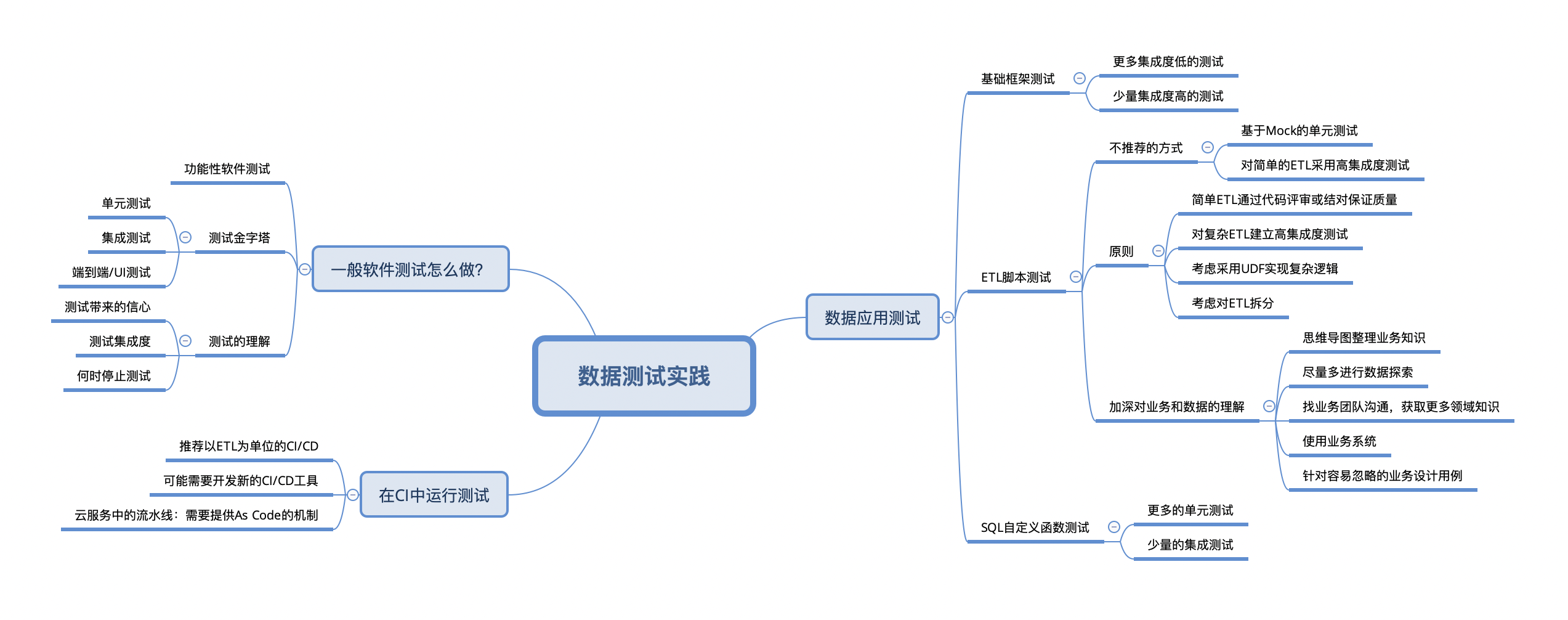
在前一篇文章《数据测试实践》中,我们探讨了数据应用如何做测试的问题。在数据测试中,ETL脚本的测试是个难题。一般而言,采用高集成度的测试方式(即运行ETL并比对结果,下文称集成测试)是更有效的做法。但是,这类测试的编写和维护却有较高的成本。如何降低ETL集成测试的成本呢?本文尝试从数据工具的角度分享一些我们的经验。
在前面的文章《数据应用开发语言和环境》中我们建议使用SQL来作为主要数据开发语言,并且,通常我们需要对标准的SQL进行增强,以便可以更好的支持复杂的数据开发。一些典型的需要新增的特性可以是变量、控制语句、模板等。
增强SQL固然是可以解决我们的数据开发问题,但是它也会给我们带来一些其他的不便。第一个烦恼可能就是,标准的SQL可以在很多数据工具中运行,比如Superset的SQL查询器、Hive的查询控制台等,而使用增强语法的SQL编写的代码则不行。由于我们将标准的SQL增强了,而SQL周边生态工具却无法感知这样的增强,这时各种不便就随之而来了。