他没有做过数据开发,但是对新技术很有兴趣。项目刚开始,正是需要有能力的开发人员加入的时候,他加入了团队。
将数据实时接入数据平台可以提升数据导入性能。当前已经有一个实现,但是性能问题很突出。在数据量激增时,延迟会变得很高。他接受了这个挑战。
“搭建一套环境,重现这个性能问题,应该就能解决。”团队初步确定了思路。数据开发用到了很多技术,Oracle、OGG、Kafka、StreamSet、Kudu等等,对于他而言,都是全新的。
他没有做过数据开发,但是对新技术很有兴趣。项目刚开始,正是需要有能力的开发人员加入的时候,他加入了团队。
将数据实时接入数据平台可以提升数据导入性能。当前已经有一个实现,但是性能问题很突出。在数据量激增时,延迟会变得很高。他接受了这个挑战。
“搭建一套环境,重现这个性能问题,应该就能解决。”团队初步确定了思路。数据开发用到了很多技术,Oracle、OGG、Kafka、StreamSet、Kudu等等,对于他而言,都是全新的。
早上送完人回到家,快两岁的小孩子已经起床穿好了衣裳,家里人正在准备早餐。
“要吃饼饼”,小孩子指着一袋子蛋卷说。看看给他准备的牛奶马上就要好了,就对他说,“我们先喝牛牛好不好,喝完牛牛再吃饼饼”。小孩子一改以往得不到就吵闹的样子,嘴上说着“喝完牛牛再吃饼饼”,往摇奶器那边走过去。
前面的文章《我理解的Smart Domain与DDD》中,我们分析了 Smart Domain 的设计,尝试回答了为什么 Smart Domain 可以用于实现 DDD,并对Smart Domain和DDD进行了一些扩展性的讨论。
虽然 Smart Domain 作为一种设计范式,可以辅助我们实现 DDD。但是具体到真实项目中,建模这个过程还得结合实际的领域问题,深入思考,大量尝试,大声建模,才能得到好的模型。有哪些值得参考的案例呢?下面分享几个个人在项目中觉得还不错的建模实践。
前段时间,咱们CTO八叉在极客时间做了一次关于用Smart Domain实现DDD的分享(点击这里回看)。一个新词Smart Domain进入大家的视野。
Smart Domain是啥?为什么可以用Smart Domain实现DDD?本文尝试结合以往对DDD的学习和实践的经验,跟大家分享一下个人的理解。
八叉在分享中提到Smart Domain这个名字来源于Smart UI。我们都知道Smart UI是DDD中提到的一种反模式,只能用于解决简单问题。这里的命名略带反讽戏谑的意味。
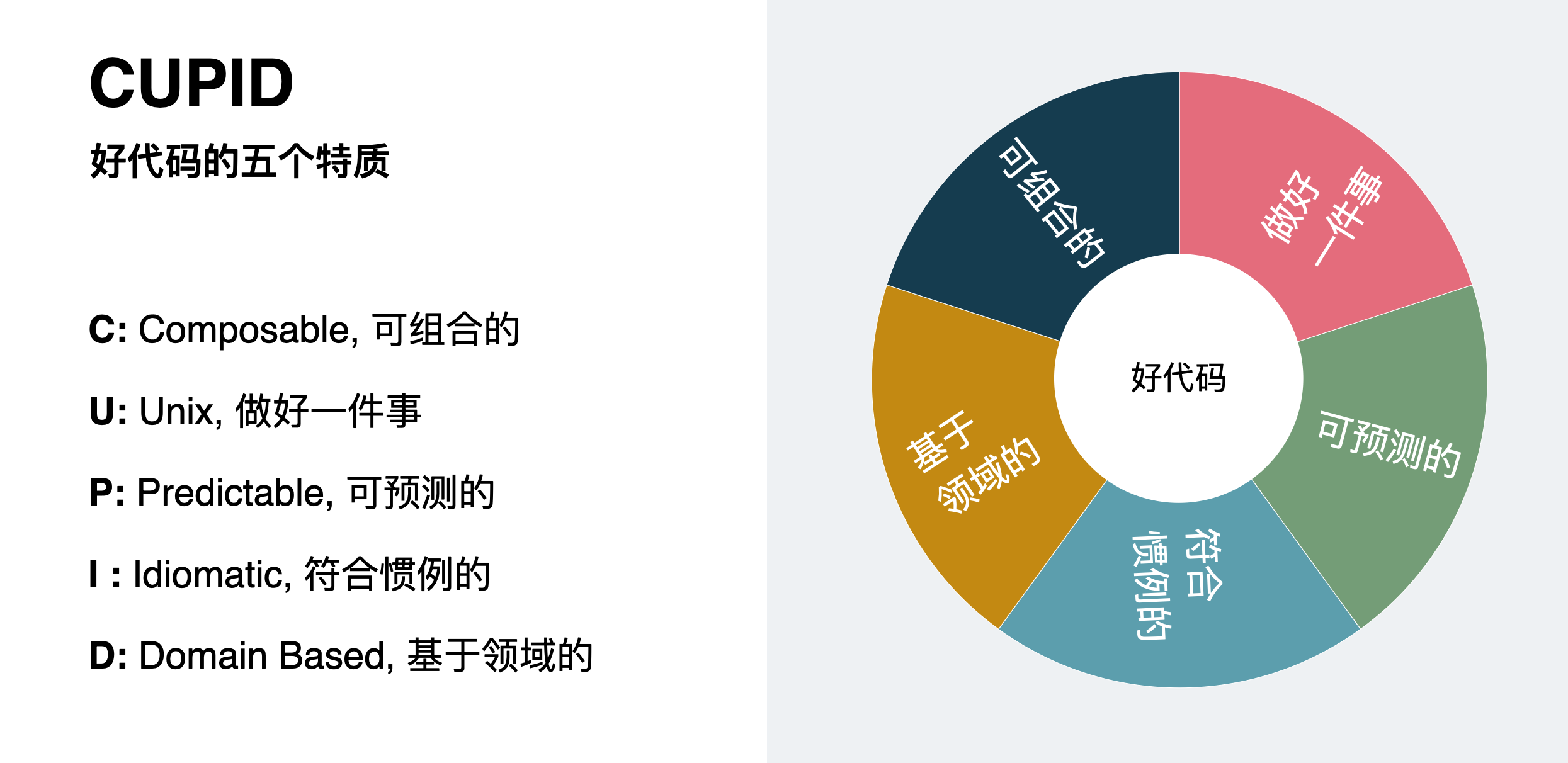
新的一期技术雷达如期发布,仔细阅读了这一期的所有条目,CUPID这一条尤其让我产生共鸣。
CUPID出自Daniel的一篇名为《CUPID—for joyful coding》的博文,即《CUPID-为了快乐编程》。CUPID是Composable/Unix philosophy/Predictable/Idiomatic/Domain based几个单词的缩写,有经验的同学一看就知道这是好代码的一些属性。知道Cupid这个单词的同学还能感受到这一组属性所蕴含的对于软件工程的热情。Cupid的中文是丘比特,是指古罗马的爱神,其意象是一个长有翅膀的小孩,拿着弓箭射向人们,以便人们可以相互爱上对方。
作为我们使用最广泛的CI/CD工具Jenkins,它对于Pipeline as Code的支持却并不能算友好。在多个项目中使用之后,我发现它存在的主要问题有:
Groovy语言相对而言还是比较小众的。其设计为一种动态类型的语言,这给编译器、IDE的类型推断带来了困难,从而导致较弱的自动代码提示。除此之外,由于Groovy可以在没有歧义的情况下省略括号和行尾分号,并且如果最后一个参数是一个闭包则可以将其写在函数调用之后,这就导致了相对比较怪异的语法出现。比如,刚接触Groovy的人可能不太能一下子理解下面这段代码的工作原理:
1 | a(1) { |
昨天和项目组的几个小伙伴去爬山。这次爬山坐标深圳梧桐山。从西北门进山,我们沿着蜿蜒的公路一路而上,历时三小时登顶。下山时不想原路返回,故意选了另一条路。从山上往下看,这条路陡峭得很。不过,对于几个血气方刚的男性,这条路正好。因为大家都觉得上山太简单不过瘾,想挑战一下高难度。于是我们一致同意换路而行。我们走的这条路就是凌云道。
说起凌云道这条路,真是名副其实。它不仅几乎呈垂直高度下降,而且台阶较窄仅有半脚宽。路两边树丛虽然茂盛,但是都不高大,山下的情形总是能进入眼帘。我一向有点恐高,在这垂直高度近1千米地方往下看,还真是心里有点慌。刚开始下山,小伙伴们见此山势,纷纷停下脚步拍照。得几张无P图片如下,大家可以感受一下:
随着微服务和DDD的兴起,领域这个词逐渐成为了一个大家每天讨论中的高频词。对于经验稍欠缺的同学们,刚接触领域这个词,总会感觉有点神秘。到底什么算是一个领域呢?我们经常在谈论领域模型、领域服务、领域事件、领域边界等等,如果对领域概念没有一个清晰的认识,在接受这些相关概念上想必也会遇到阻碍。本文将结合我个人的理解以及一些实践经验来谈谈对这个概念的理解,希望能帮助大家更好的认识领域,进而更好的理解和运用相关的概念,最终更好的指导软件开发实践。
前几天,我在跟一位做进口贸易的朋友聊天,发现一个很有意思的事情。
他们做的是国内的高端仪器进口的进口贸易业务。主要帮助销售国外产品的公司完成竞标、合同签订、物流、海关、进口贸易政策符合、维保等等事务。
我很疑惑,为什么会有这样的业务形态存在?为什么这些产品销售公司不自己处理这些事务,反而代理出去让其他公司赚钱呢?
前文讨论了敏捷数据工程实践的相关概念。有哪些具体的敏捷数据工程实践呢?本文将分享“基于代码的复用”实践。
在应用软件开发中,代码复用是一件显而易见的、开发人员几乎每天都在做的事情。良好的代码复用可以有效降低代码重复率,提高效率,并减少潜在的BUG。