随着微服务和DDD的兴起,领域这个词逐渐成为了一个大家每天讨论中的高频词。对于经验稍欠缺的同学们,刚接触领域这个词,总会感觉有点神秘。到底什么算是一个领域呢?我们经常在谈论领域模型、领域服务、领域事件、领域边界等等,如果对领域概念没有一个清晰的认识,在接受这些相关概念上想必也会遇到阻碍。本文将结合我个人的理解以及一些实践经验来谈谈对这个概念的理解,希望能帮助大家更好的认识领域,进而更好的理解和运用相关的概念,最终更好的指导软件开发实践。
概念理解
什么是领域?跟领域相关的词我们可以想到领土、领地、业务域、业务领域、自然科学领域、动物的领域等等。领域这个词我们平常的中文使用场景非常广泛,可能这也是导致这个词不容易理解的原因。领域这个词的中文解释是:(来源:http://cd.hwxnet.com/view/ahecdjginknflmnk.html)
①犹领土。国家主权管辖下的区域:国家领域神圣不可侵犯。
②意识形态或社会活动的范围:思想领域|学术领域|生活领域|科学领域。
在我们软件开发中,领域一般对应英文单词Domain,牛津词典解释如下:
an area of knowledge or activity; especially one that sb is responsible for (知识、活动的)领域,范围,范畴
例:The care of older people is being placed firmly within the domain of the family. 照顾老人仍然被确认为是家庭范围的事。
例:Physics used to be very much a male domain. 物理学曾在很大程度上是男人的领域。
似乎很简单嘛!看起来就是一个“范围”的意思。其实“域”这个词本身就是范围的意思,加上“领”字,我们可以认为是一种特殊的范围。既然就是“范围”,那么就容易理解了。我们说自然科学领域,其实就是在自然科学研究范围内;我们说业务领域,其实就是和某项业务相关的范围内;我们说正整数的范围是1到无穷大,也差不多可以理解为1到无穷大这样一个“领域”(这里一般认为只是一个“域”)。
如果更严格一点,从数学上来认识,我们可以对应到集合这个概念。只不过,我们平常所说的领域可能是一种定义不严格的集合,只存在一个大致的边界。但是这通常不影响我们沟通交流,因为边界在当时可能不太重要。既然是集合,那么我们可以从下面这张图来对应理解领域概念。
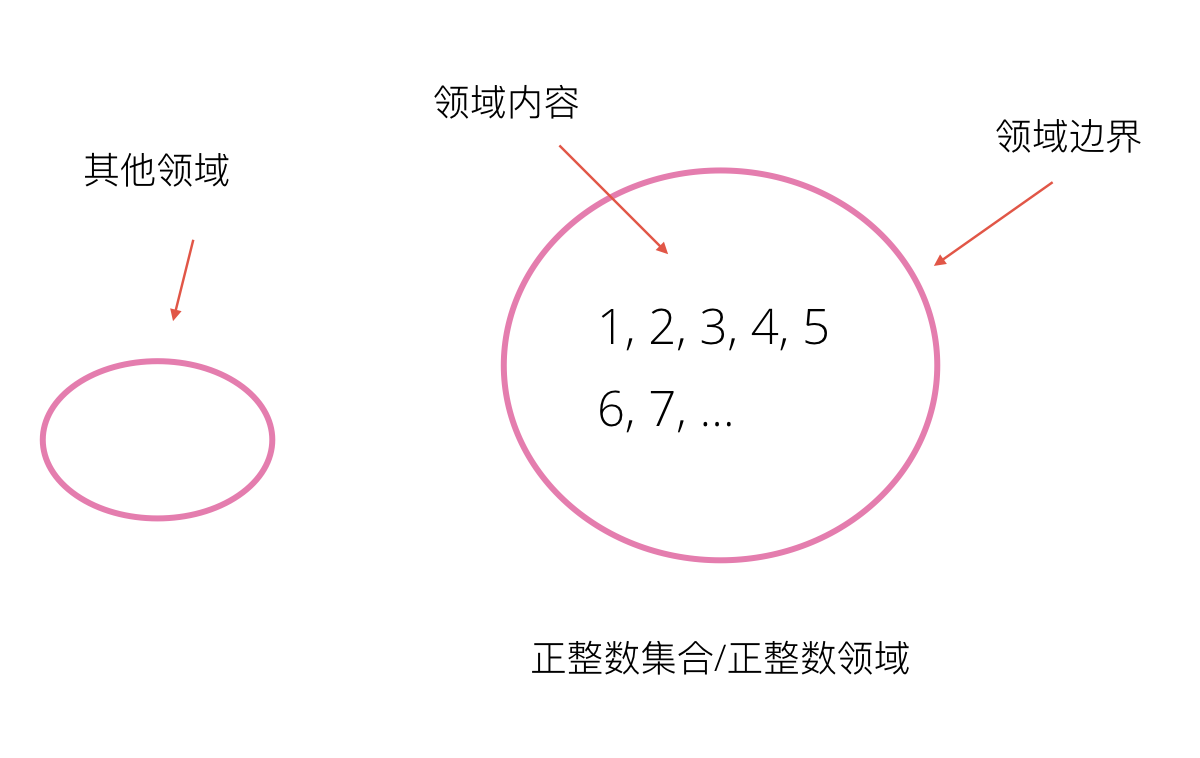
代码中的领域
有了”领域“就是”范围“这样一个简单的理解,我们回头来看我们代码中的领域,很多问题就会变得清晰起来。
比如我们有下面这个简单的求和函数:
1 | def sum(from, to): |
这里有哪些领域或者范围呢?
最底层的要算for循环体内的一个范围,也就是一个代码块。这里的代码块不仅从逻辑上构成了一个范围,在很多编程语言里面还反映在变量的作用域上,比如在这里定义的变量,代码块外面可能是访问不到的。其次是函数体构成一个范围。再次,如果这里的函数是某一个类的方法,那么该类本身构成了一个范围。再继续,类所在的包构成了一个范围,包所在的库构成了一个范围等等。按照领域来理解,我们可以认为这里的领域按照不同的细节程度和抽象程度构成了一个类似森林的结构。
再深入细节一些,我们甚至可以认为,我们常常用空格分隔起来的几行代码片段构成了一个范围或者微型的领域。
了解了范围和领域的概念如何帮助我们理解其他的相关概念呢?(下面的文字很多,但是每一节之间几乎是独立的,大家可以分成多次阅读。)
内聚和耦合
先来看一下内聚和耦合。
从领域的角度来理解,我们可以认为,领域内部的东西是内聚的,一个领域引用别的领域就构成了耦合。我们都说好的代码是高内聚低耦合的,其实反映到代码上,就是说,我们代码里面的任何一个领域尽量别去引用其他领域的东西。如果某一领域引用了极少的其他领域的东西,或者甚至没有引用其他领域的东西,那么我们就可以认为该领域可以独立自治的实现功能,它就是高内聚低耦合的。对于这样的高内聚低耦合的领域,它可能是某个函数或者某个类或者某一模块,甚至是某一个库。不管是什么,他们的理解和使用应该是非常容易的,因为除了这个领域我们很少需要理解其他领域。正是因为高内聚低耦合的代码好理解,易于使用,我们才会认为这是好代码。
有人可能会说我们几乎不可能不去引用别的领域就实现某个功能,就算是上面的求和函数,我们也引用了系统库里面的range函数。这里我们可以用DDD里面的通用领域概念来辅助理解,标准库即是一个通用领域,我们可以假定使用我们代码的人对于标准库的理解都是不错的,也就是说我们引用标准库领域一般是不会带来理解和使用上的问题。
在这里,面向对象中的封装思想可以帮我们缓解耦合的问题。通常我们更多的是去使用某一个库(这里的库不仅表示第三方库,而是更宽泛的其他领域的概念),我们也就更关注这个库好不好用,而少于关心这个库的实现是什么。对应到领域概念中,也即我们通常更关心领域的边界,而少于关心领域的内容。为什么说更关心领域边界呢?从代码层面理解,领域边界就是我们对外暴露的API,它包含所有公开函数的函数名、参数及返回值,类的构造器,类的状态变迁等。既然我们更关心接口,那么即便我们的领域比较复杂,引用很多,耦合比较高,但如果其边界比较简单,这样的领域一般也是较好的领域(之所以说它是较好的领域是因为复杂的领域存在不易阅读不易理解的缺点)。而封装就刚好可以实现将领域内部大量的事物隐藏起来,只对外暴露简单接口的作用。这里对于实践的指导就是相比代码实现的复杂度而言,我们要更关心接口的复杂度,通过封装大量细节可以让接口变得更简单。

抽象层次
再来看一下抽象层次。
很多时候,我们说一段代码做的事情应该是同一个抽象层次的事情。什么是同一个抽象层次呢?假设我们要去复印一份文件,要如何描述这个过程呢?大家想一下就可以脱口而出,我们可以通过这样几步来实现:1. 带上资料走到复印机前;2. 复印资料;3. 带走复印好的资料。这样的步骤很清晰,大家看到会很容易理解。实际上我们就可以认为这里的几件事情是同一个抽象层次的事情。
一个比较极端的反例是什么呢?可以是这样:1. 带上资料;2. 观察当前位置到打印机位置的路线;3. 选择一条路线;4. 走路;5. 绕过障碍;6. 避免跟人交谈;7. 排队; 8. 复印资料;9. 带走复印好的资料。这里的步骤就不是那么容易理解了。第一步到第七步过于细节,我们可以说它们分别和第八步、第九步不是同一个抽象层次的内容。事实上,这里过于细节的步骤会导致我们迷失方向,失去重点,大家可以想想,看了上面这些步骤之后,我们还能清楚的知道我们的目的是要复印资料吗?这里的步骤拆解其实跟代码编写是同样的道理,当我们把本该在另一个独立的函数内实现的功能放到当前代码中实现的时候,这样的问题就凸显出来了。
领域在这里如何帮助我们理解这个问题呢?上面对于抽象层次的理解其实还是比较模糊的,不同的人对于细节程度会有不同的认识。但如果我们从领域的角度来看问题,情况就会变得清晰起来。我们首先会发现反例里面涉及的内容过多(代码内的概念过多),里面有路线、走路、障碍、人、交谈、排队、复印机、资料等事物,即这是一个复杂的领域(复杂的代码)。复杂的领域难以理解,就像一个集合,里面充满了数量多而没有规律的数。如何让其变得更简单呢?我们将第一步到第七步合并为单独的领域(一个内部函数),即带上资料走到复印机前,这样就可以得到下面这样一个简单的领域(简单的代码)。
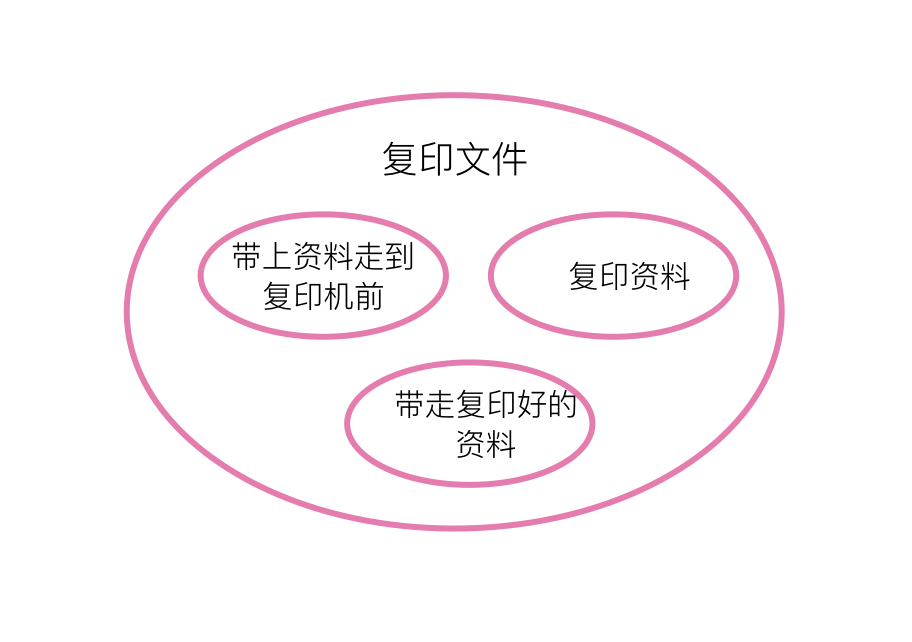
仔细观察一下上面这个更简单的领域(更简单的代码),事实上“复印资料”和“带走复印好的资料”这两个步骤的复杂度跟“带上资料走到复印机前”是差不多的,只不过我们并没有分析它们的细节而已。从领域的角度来讲,我们可以大致认为上图中的三个小圈的领域复杂度(代码复杂度)相近。这里的分析对于抽象层次的启示就是,通过领域内包含的事物的多少可以在一定程度上量化分析两个领域是否是同一抽象层次的领域。当两个领域复杂度(代码复杂度)相近时,它们就有可能就是同一抽象层次的领域。最理想的代码莫过于代码对应的领域构成了一颗平衡树,每一片枝叶都是简单而独立的存在,每一个节点的子节点都是复杂度相近的子树(复杂度相近的子域,也即同一抽象层次的事情)。这个时候,我们实际上把系统拆分为了几个复杂度差不多的模块,将每一个模块又拆分为了复杂度差不多的类和函数,而每一个类和函数又都比较小巧。
我们还会发现我们脱口而出的几个步骤通常自然的就形成了好的领域(好的代码)。这是为什么呢?其实这是和我们的思维方式是一致的,我们去理解一个复杂事物的时候,总是会将其拆分为几个小的事物去理解。而我们描述某一个事物的时候,总是自然的就得到了合适的几个部分。在同一个描述里面,通过自然的方式得到的几个事物,一般就是同一个抽象层次的事物。当然这里的自然一定是出自于某一个个体,其他人可能有不认同的地方。但是多数人至少应该容易理解这样的拆分,因为这和我们平时和其他人交谈的时候容易理解其他人的话是同样的道理。到这里,大家是不是认为写代码和说话一样简单了呢?当然可能不止说话,应该说写好的代码应该和写好的文章差不多。
依赖倒置
再来看一下依赖倒置。
我们说依赖倒置,就是说要依赖于抽象,而不要依赖于实现。这是什么意思?为什么依赖抽象是更好的?这里的抽象我们是指某一个抽象的概念,通常反映在代码中就是接口,或者至少是抽象类。依赖抽象的好处在于我们可以根据需要在运行时将这个依赖替换为任意一个实现。有了这样的特性,我们可以方便的在测试中使用测试替身(test double)来替换掉某个依赖,于是测试就更易于编写。有了这样的特性,我们还能方便的提供多个实现,而在运行时根据需要选择一个,比如当我们抽象了一个repository接口来存储数据时,我们可以基于RDBMS数据库提供一个实现,同时基于NOSQL数据库再提供一个实现,然后根据需要选择任意一个实现而无需改变代码。这里依赖倒置为我们编写代码提供了非常大的灵活性。
从领域的角度如何理解依赖倒置带来的好处呢?我们还是要回到领域简单与否上面来。一般而言在某一个类里面依赖另一个类时,我们不会依赖另一个类的所有的API,而只是依赖于和当前待实现的功能相关的API。这个时候,如果直接依赖于另一个类,我们需要完全理解另一个类之后才能理解当前这个类。这就是说我们的领域更难以理解了。更好的方式是什么呢?通常我们可以将当前真正需要依赖的API抽象为一个新的概念,新建一个接口,然后依赖于这个接口进行当前类的实现,同时将之前的依赖类添加实现这个接口的声明。这样一来,由于依赖的东西变少了,当前这个类的实现就变得更简单更易于理解了(简单的领域)。这里可能还是有点绕,不太好理解。举例说明一下。假设我们要实现一个类,它将依赖一个队列来实现其功能,我们可以编写代码如下:
1 | interface Queue { |
在SomeCls中使用抽象的Queue接口相比于使用某一个库里面的Queue类给我们带来了很明显的好处,它使得我们理解SomeCls更容易了。因为我们明确的知道在SomeCls的实现中只会使用一个仅带有push和pop两个API的Queue,而不会使用可能的Queue的size,isFull这样的方法。而同时我们可以轻易的利用已有的标准库或者第三方库中的Queue实现去实现这里定义的Queue接口,只需要编写极少的额外代码。另一个好处是,通过接口定义,我们的依赖变得更清晰了,它只依赖这样一个Queue,这个Queue无需多一个API,也不会少一个API。也就是说,对于SomeCls这个领域而言,其边界是简单而清晰的,这个领域就是更易于理解的。同时我们可以看到这个类也是低耦合的,因为它引用了更简单的东西。
这里还可以举一个关于防腐层的例子。在DDD里面我们经常提到防腐层的概念。一个微服务在使用其他的微服务时,其他微服务的数据模型容易侵入当前的微服务代码而造成影响,防腐层就可以很好的解决这个问题。比如在电商的场景下,积分微服务定期访问订单微服务来更新积分(这里的流程仅用于举例)。订单微服务提供了一个API用来查询订单,这个API会返回订单的详情信息,但是积分微服务在查询订单的时候只想得到订单价格。在积分微服务与订单微服务进行集成时,如果我们直接将订单微服务返回的数据模型作为我们积分微服务的领域模型,那就将导致积分微服务的领域腐化。因为积分微服务根本无需关心订单详情,当我们在领域模型中加入了其他无关信息时,我们的理解负担就无形中加重了。而且这可能会带来订单详情信息在积分微服务代码里面滥用的问题。防腐层可以提供一层抽象,做一次映射将从订单微服务拿到的订单信息转化为积分微服务内真正需要的领域模型。这里的防腐层我们可以理解为保护了我们的领域。其实防腐层还可以理解为使我们的领域边界更清晰了,因为在积分微服务的实现里,我们只需要使用防腐层的接口,而无需访问订单API获取数据,也就是我们依赖了一个防腐层的抽象,而不是依赖于某一个REST API的真实实现。这里解决问题的方式是不是和上面的依赖倒置有相似之处呢?大家可以仔细体会一下。
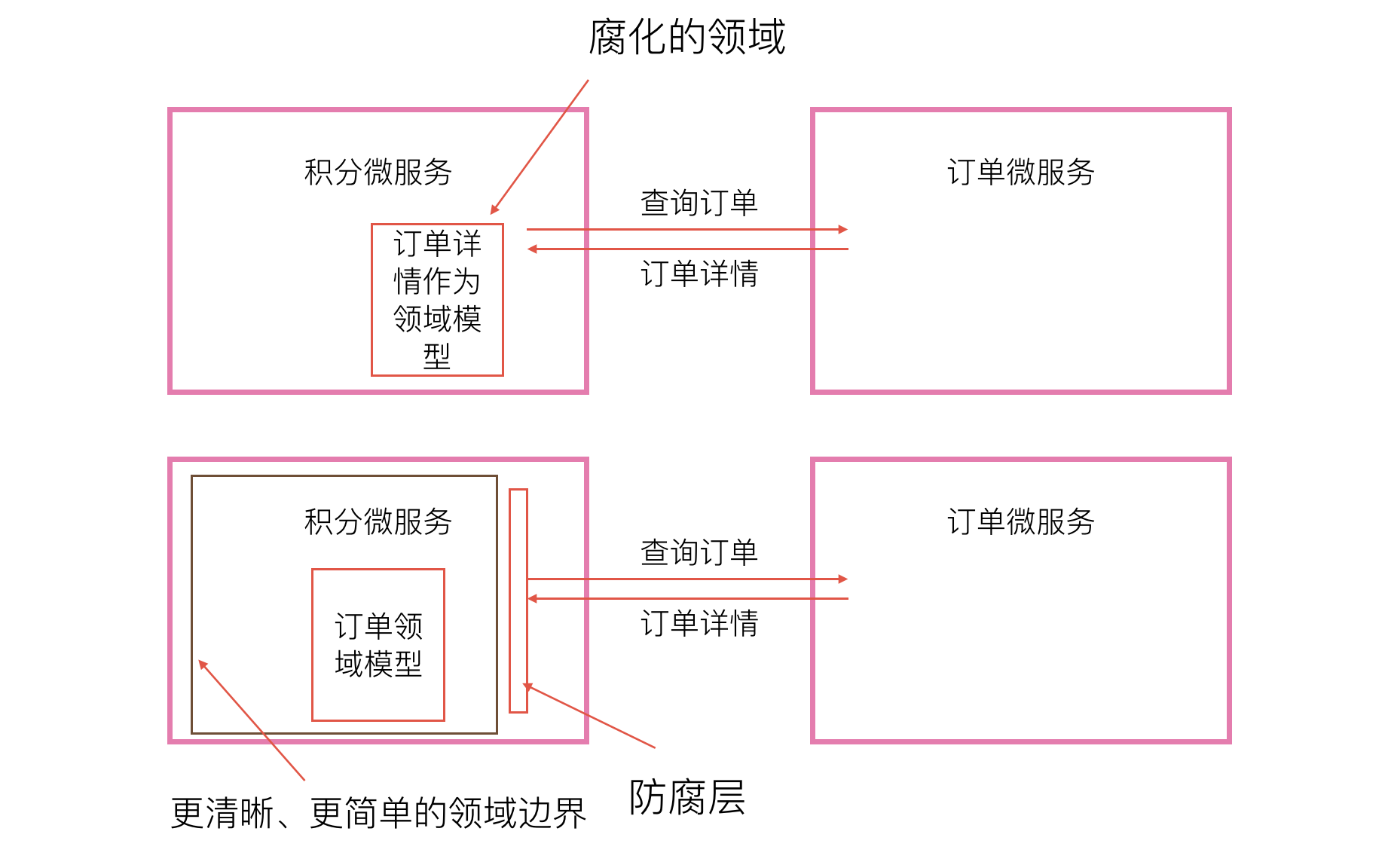
使用领域语言编写代码
有了领域这个概念之后,我们就可以延伸到领域语言,领域语言就是用来在领域内部进行沟通的语言。我们说好的代码需要用业务语言来编写,这里可以认为业务语言就是一种领域语言。如果要下一个严格一点的定义,领域语言是仅使用某一个领域内的概念和大家都理解的通用的助词,通过语法规则而构成的语言。如何更好的使用领域语言呢?什么情况下,我们是使用了领域语言写代码呢?
这里的问题我们可以分层次来理解。通过前面对领域的分析,我们可以将代码按照细节层次不同分为函数或方法领域,类领域,模块领域,服务领域,系统领域等。从函数或方法领域来看,我们要仅使用领域内的概念和通用助词来编写代码,也就是说我们的变量命名,使用到的函数或者类的名字需要是包含于这个领域内的概念。比如上面的求和函数,分析求和过程可以得到这样的几个概念或过程:起始值,结束值,获取迭代范围,迭代过程当前值,当前累加结果值。他们分别对应了代码中的from to range i total。如果我们分析代码发现除了这些领域内的名字,没有使用其他的名字,我们就可以说这是用领域语言在编写代码。如果不用领域语言,试想我们将total这个变量名改为了一个领域外的名字,如multiply_result,大家还能轻易的读懂这段代码吗?
1 | def sum(from, to): |
我们可以使用同样的方法去分析类领域,模块领域,服务领域,系统领域等。
使用领域语言写代码还有这样一些需要注意的地方。
-
使用领域语言写代码,要求我们尽量多使用业务名词,尽量少使用技术名词。一些典型的技术名词包括
sockettcpudphttpjsonmysqlrabbitmq等。如何尽量少的使用这些名词呢?一个办法就是用一个短小的类将这些名词的封装成一个领域概念。由于多了一层封装,这些技术名词就不会泄露到其他代码中去了。更进一步我们可以采用上述依赖倒置的手法,将这些概念抽象为接口,让领域代码依赖这个接口去实现功能,而这些技术名词就自然的被放到某个具体的接口实现代码中去了。这通常是合理而有效抽象手法,为了做到这样的抽象,我们在进行设计时可以像下面这样自问一下。当我们需要mysql时,我们是不是只需要一个抽象的RDBMS?当我们需要RDBMS时,我们是不是只需要一个抽象的存储服务?当我们需要RabbitMQ时,我们是不是只需要一个抽象的队列?当我们需要转换为json时,我们是不是只需要一个抽象的序列化过程? -
使用领域语言写代码,要求我们使用一致的命名。比如,我曾经在一些代码里面发现对于同一个“位置”概念,代码里面有的地方用的命名是
position而有的地方又使用location,这就是不一致的表现。不一致的命名将给我们理解代码带来困难,因为我们在看到这两个词时,只能猜测它们是否是同一个意思,而不能肯定的给出答案。而且使用不同的词,看上去给领域增加了新的概念,导致领域变复杂了。这在多个人同时编写代码的时候尤其容易出现,这就需要我们每个人都注意:在新编写代码的时候,使用大家都在谈论的领域字典中的名字;在修改代码的时候,使用和之前代码一致的名字;在重构代码的时候,将不一致的名字修改为领域字典中的名字。 -
使用领域语言写代码,要求我们使用更有意义的名字。很多同学喜欢用类似
rulebusinessobjectcontext这样的单词,这样的单词由于适用范围过于广泛,其实对于我们阅读代码时理解领域的帮助很少很少。我们几乎可以直接去掉这样的单词来理解代码,这样一来这些单词不仅仅没有给我们理解代码带来方便(可读性不高),反而带来了干扰。
这里可能有人会担心不同的领域(函数)内会有相同的概念(比如多个函数里面都有total这个变量),从而导致混淆,这其实是正常情况。它们确实可能是使用同一个名字的概念,但是它们的内涵往往不同。我们平时交谈中使用的词语其实也常常是多义词,但这几乎不影响我们交谈,因为我们交谈中有上下文。我们阅读代码时也一样,代码对应的领域往往提供了比较明确的上下文,这就让我们区分不同内涵没那么困难了。
尝试理解更多
上面的分析有些过于发散,总结起来,通过领域去理解编程原则,我们可以尝试:
- 将“领域”对应到“范围”去理解,
- 在不同的层次(函数或方法领域,类领域,模块领域,服务领域,系统领域等)去理解某一个编程原则。
总之,领域还可以用来帮助理解更多的概念和编程原则,大家在遇到一些不容易懂的概念时,可以尝试从领域的角度来尝试理解,看看是不是更容易。