随着系统功能越来越多,系统的配置也越来越多,配置管理成为了一个重要的问题。做过线上运维的同学们一定对配置的复杂性有深刻体会,多少次加班都是因为一个配置不对而导致系统无法正常工作!配置问题由于难以建立有效的自动化测试而难以检测,常常使得我们不得不花费数小时甚至数天来调试才能找到配置上的问题。
对于分布式计算,这个问题变得更加突出了,熟悉分布式大数据处理的同学们对于分布式任务的复杂配置一定深有感触。分布式系统本身的复杂性常常使得单个组件的配置就有上百个。而在微服务架构流行的当下,我们的系统越来越多以分布式的形式出现,系统的配置管理问题也越来越突出。
本文尝试分享一下我们在构建机器学习平台时对于配置管理方面的设计实践。
模块自有配置导致的混乱
结合上文中关于平台架构的分析,我们看到系统拆分了一个名为connector的通用模块,负责实现和外部系统进行对接。这一模块会同时支持Rest API及ml两个应用层模块。
由于Rest API及ml两个模块会连接同一个大数据集群进行数据操作,所以它们的不少配置是一样的。比如某一租户运行任务的缓存路径,读写的hbase的数据库名字等。一个简单的想法就是将这些与connector相关的共享配置放到connector模块中去,然后将无法共享的配置放到Rest API及ml各自的模块中去。
在刚开始时,我们确实是这样做的。但是随着系统功能慢慢的变得复杂,配置项越来越多,这样简单粗暴的配置设计越来越难以支撑系统的快速演进。主要问题表现在:1. 开发人员在新增配置的时候,对于配置放哪里(至少有3个地方)一直存在争议;2. 为了支持多个环境并避免配置重复,不得不自己实现类似Spring profile的配置加载机制;3. 某一个功能用到的配置可能分散到多个地方,出现问题的时候,需要从多个地方去识别配置问题;4. 由于配置会打包到jar包中,我们不得不为每个环境生成不同的包。
统一的配置管理设计
那么,在一个多模块的复杂系统中我们要怎么做才能有效的管理配置呢?
分析上述提到的痛点可以发现,对于一个好的配置管理设计,一个重要的点是配置要能集中进行管理。
在我们的系统中配置应该集中到哪里呢?稍加分析就能知道,配置当然要集中在某个最外层的应用层模块进行,因为各个服务实例的组装就是在这里完成的。在上面的这个场景中,我们有两个应用层的模块,即Rest API及ml。实际上ml模块并不是可以独立运行的模块,它的内部是实现了特征处理Pipeline和各种机器学习算法,以spark应用的形式提供出来。这些分布式应用的调度却来自Rest API,也就是Rest API是一个驱动器,是更偏应用层的一个模块。对于ml模块中需要的配置,我们就可以在调度其运行时通过参数的方式传入。于是,我们的配置就应该集中到Rest API模块中。
改造之后的配置如下图所示:
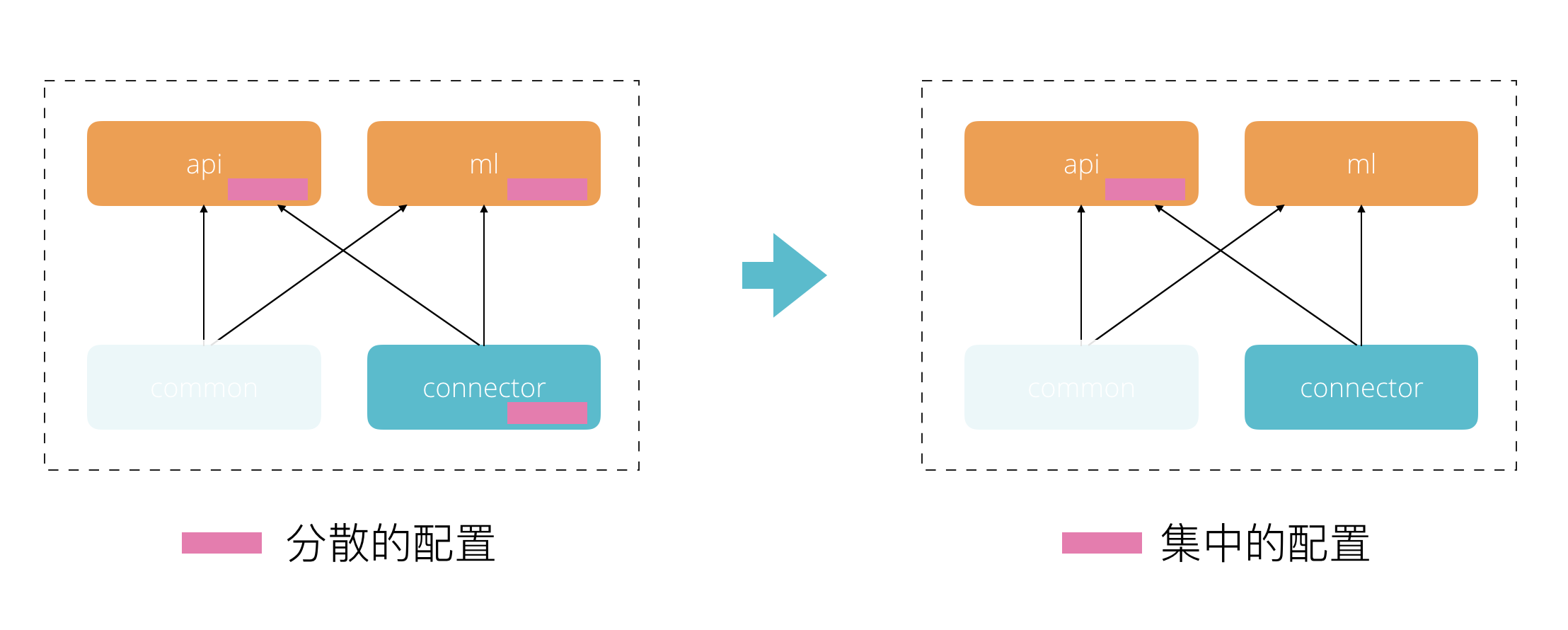
恰好Rest API模块是基于Spring Boot构建的,这样一来,就可以完全借助于Spring为我们提供的配置管理工具来实现配置管理了。
实现了这一步骤之后,整个配置设计就变得简单易懂,上面提到的配置管理问题也被有效的解决了。除了Rest API模块会根据不同的环境构建不同的包,其他的包全部都是可以按版本独立发布且可在各个环境复用的。至于Rest API模块,其实我们也可以很容易实现一个包支持多个环境,只需要我们将配置独立出来作为一个外部文件来管理即可。
为了实现这一架构调整,我们在原有系统上面进行了较大的重构。在重构过程中,有几点设计上面的经验是比较有价值的:
- 从依赖倒置的设计思想来看,作为一个通用的模块,其配置设计应该以一个接口的形式进行定义,然后在模块内部所有需要使用此配置的地方引用该接口
- 对模块内某一个具体类的配置设计,应该考虑最小信息原则,仅支持类自身需要知道的几个配置,而尽量不要直接引用一个大而全的配置对象
- 在模块内部,可以考虑提供一个配置接口的实现,以便提供一些合理的默认配置
- 在配置设计上需要尽量保持配置项的独立,避免设计一些本可以通过原子配置计算得到的配置,这样可以减少配置数量
微服务中的配置
除了要考虑模块中的配置设计,另一个要考虑的配置问题就是各个微服务中的配置设计。
由于微服务需要独立的为外部系统提供服务,我们无法将其当做一个模块来对待,所以配置是不得不存在的。
Spring Cloud Config为我们提供了一个中心化管理微服务配置的思路,它考虑了支持配置文件的集中加载、版本管理(可以通过git实现)、容错等需求的实现。但是多部署一个组件来管理配置引入了额外的复杂度,多数团队不太希望引入一个需要额外维护的模块。
k8s的ConfigMap及Persistent Volume设计为我们管理配置提供了另一种方式。我们可以将配置放到某一个共享的ConfigMap或Persistent Volume中。
在实践中,我们采用了k8s提供的配置管理机制。
在我看来,采用何种配置管理机制的一个主要考量是有多少重复的配置。如果各个微服务间的重复配置特别多,我们甚至可以参考helm管理k8s配置的机制,即通过模板系统来提供一个更高层的配置抽象,从而得到更少的配置项,然后通过程序自动生成不同的微服务的配置。
这里另一个需要思考的问题是为什么会有这么多的重复配置,是不是微服务拆分本来就不合理呢?因为一旦有重复的配置,就说明不同的微服务间有一个相同的依赖。这即是微服务耦合的体现。在微服务设计时,一个指导原则就是要采用DDD的思路进行拆分,避免出现高耦合的分布式大泥球。高内聚低耦合是我们进行系统设计的不懈追求,如果我们发现是由于服务拆分不合理导致的配置重复,那我们就得更早的进行调整,防止带来更大的损失。
在机器学习平台系统中,我们拆分出来的Spark-Meta Monitoring MLServing Rest API等几个微服务间几乎没有配置重复,这也使得我们在管理微服务的配置上面变得非常轻松。
配置的存储和更新
在进行配置设计时另一个我们经常关注的问题是配置怎么存放及更新的问题。比如,对于某一个配置项,我们是将其放置到配置文件中呢,还是放到数据库中?还比如,对于某一个配置项,如果我们有需求要进行动态的更新要如何实现?
对于配置的存储位置,一般而言,我们会优先考虑存储到配置文件中。如果存储到数据库中,实际上我们是将配置当做数据进行管理了。既然是数据,那么其访问权限就要被严格限制,否则将带来安全隐患,比如配置文件中通常要存储一些系统间通信的账号密码,我们如何保证这些数据的安全性呢?一些将配置存放到数据库中的想法可能来源于配置的更新可以通过维护数据库中的数据来简单的实现。然而,配置的动态更新需要程序逻辑的支持才行。比如,对于缓存的配置要何时更新?已经创建的对象要如何重建?这些可能是非常复杂的问题,远非修改一个数据库数据可以实现。因此,如非必要,我们还是要优先考虑将配置存储到配置文件中。
Spring为我们提供的配置管理实现了在线更新配置的接口,我们可以直接修改某一个配置,而无需重启服务。但是这样一来,这些更新了的配置就只是在当前进程中生效了,一旦重启这些配置将不复存在。在当前容器化的时代,我们一般不会想通过这种方式来管理配置。而希望用一种更易于管理的方式实现,比如我们可以把配置的更新当做应用程序的一次更新,然后通过滚动升级的方式应用这个更新。在广泛使用k8s进行应用运维的当下,要实现不停服升级是轻而易举的。
总结
本文分享了在机器学习平台系统建设过程中,我们对于配置管理设计方面的思考和实践,还分享了关于配置的存储和更新的一些思考。如对于内容有任何疑问,或者有其他有用的实践分享,欢迎留言讨论。