作为一个一直对AI技术很感兴趣的软件开发工程师,早在深度学习开始火起来的15、16年,我也开始了相关技术的学习。当时还组织了公司内部同样有兴趣的同学一起研究,最终的成果汇集成几次社区中的分享以及几篇学习文章(见这里)。
从去年OpenAI发布ChatGPT以来,AI的能力再次惊艳了世人。在这样的一个时间节点,重新去学习相关技术显得很有必要。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
ChatGPT本身就具备很丰富的知识,所以ChatGPT自身实际上就是一个很好的学习渠道,我也将借助ChatGPT来学习ChatGPT。
这是此系列的第六篇,突破ChatGPT的知识限制。
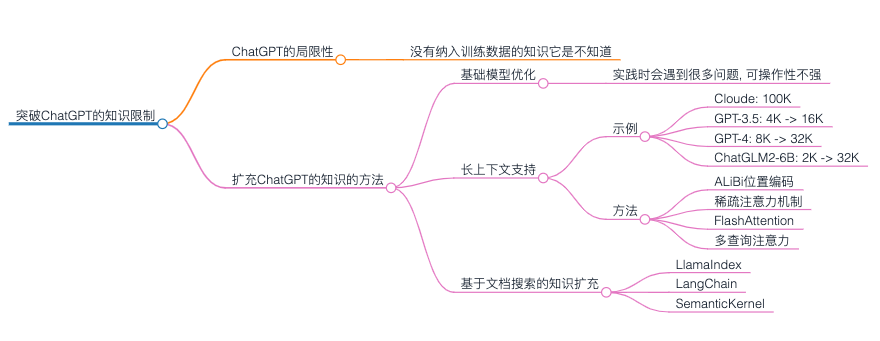
ChatGPT的局限性
上一篇文章我们深入分析了ChatGPT如何结合奖励模型和强化学习算法进行自动优化。 OpenAI开放ChatGPT模型给大家使用,随着大家使用越多,产生的对话就越多,ChatGPT就能自动优化得更智能。
虽然ChatGPT能力很强,但是其局限性也很明显,对于没有纳入训练数据的知识它是不知道的,从而也没法给出我们期望的回复。但由于我们的日常工作往往要基于大量的ChatGPT不知道的背景知识进行判断和决策,所以很多场景我们也没法简单的通过向ChatGPT提问来得到想要的答案。
如何突破ChatGPT的知识限制,让ChatGPT具备更强大的能力,以便可以更好的辅助我们完成工作?这就是本文想要讨论的问题。
扩充ChatGPT的知识的方法
基础模型优化
如何让ChatGPT认知到这些复杂的背景知识?最简单的想法是把这些知识整理成文本,制作成数据集,然后让ChatGPT进行模型优化。
如何优化呢?前面ChatGPT模型训练内容我们分析了ChatGPT类模型的训练过程,分为三个阶段:基础语言模型训练、监督微调及指令微调。其中监督微调及指令微调阶段的数据量小,主要是解决模型的指令跟随问题。如果想在ChatGPT之上加入背景知识,看起来应该在基础语言模型训练阶段实施。
进行基础语言模型调优理论上是可行的,但是实践时会遇到很多问题。比如:
- 如果新数据中存在错误、噪音或不准确的信息,将可能对模型的性能产生负面影响
- 使用这些新数据进行训练时,必须要非常小心的调整学习率,否则可能让ChatGPT遗忘之前学习到的通用知识,变得更笨
- 基础模型优化可能会影响第二和第三阶段的优化结果,使得ChatGPT没法很好的进行问答
- 模型本身太大,进行模型调优需要的计算资源更大,以目前的算力成本来看,很难负担得起
目前来看,这一方法的可操作性不强。当然,在将来某一天,模型优化到一定程度,或者算力成本降低到一定程度时,也许这一方案也变得可行了。
长上下文支持
另一种扩充ChatGPT知识的方案是想办法增加模型的上下文支持能力。模型支持的上下文越长,表示我们可以输入给模型的内容越多,从而可以让ChatGPT基于更多的背景知识回答问题。
目前ChatGPT可以支持的上下文长度为4k或16k,而GPT-4支持的上下文长度为8k或32k(参考这里)。
从前面文章对于ChatGPT原理的分析来看,要想将上下文变长并不是一件容易的事。主要的挑战有:
- 显存消耗增长:由于计算自注意力结果时需要计算并保存所有上下文计算出来的中间结果,增加上下文长度会导致模型需要更多的显存来存储这些中间计算结果。
- 计算复杂度增加:随着上下文长度的增加,每一个训练样本的计算复杂度都会增加,计算时间和计算资源的需求也会增加。
- 长期依赖问题:更长的上下文导致信息在序列中的传播路径更长,这可能导致模型难以捕捉到远距离的依赖关系。
然而,最重要的可能是并没有如此高质量的数据集供模型训练。特别是针对监督微调及指令微调阶段的数据集。
有很多分析和研究表明(参考这里),如果模型在4k上下文的数据集上面训练,是很难直接让它支持超过4k长度上下文的。具体表现就是模型性能严重下降。这就是所谓的模型的上下文长度外推能力。
目前有一些方法来增强模型的外推能力,如文章《语言大模型100K上下文窗口的秘诀》中提到的有:
- ALiBi位置编码: 分两个阶段进行训练,首先在2K个词元的上下文长度上训练基本模型,然后在更长的上下文(例如65K)上进行微调。对于网络模型,则移除位置正弦嵌入,采用线性偏置注意力代替(通过附加一个与当前词元距离具有比例关系的惩罚来修正查询出来的注意力分数)。
- 稀疏注意力机制:基于并非所有长上下文内容都是相互关联的这一假设,在计算注意力分数时仅考虑部分词元,具体实现有滑动窗口技术、BigBird等
- FlashAttention:在GPU的注意力层实现时,采用IO更高效的优化手段,以便可以支持快速训练与预测
- 多查询注意力:优化模型中间结果缓存,在推理过程中能够显著加快增量注意力分数的计算
最近的很多模型更新显示业界大家都在尝试实现更长的上下文支持。如:
- Anthropic在5.11日发布新的Cloude模型,表示支持100K上下文
- OpenAI也在近期更新了GPT-3.5及GPT-4模型的上下文长度支持,分别从4K增加到16K和从8K增加到32K
- 国内清华系近期开源的ChatGLM2-6B模型的上下文长度从2K扩展到了32K
显然,这已经是大模型开发厂商们正在努力的方向。
基于文档搜索的知识扩充
长上下文固然可以提高模型的背景知识,但在企业应用中,我们往往拥有海量的背景知识,全部依靠长上下文还是显得力不从心。
为了支持海量背景知识,可以对比参考我们人类解决问题的方法。一种常见的步骤是:
- 查找相关文档,进行大量调研
- 汇总各类信息形成基本的解决方案
- 执行
可以发现,即便人类所具有的背景知识也是有限的,人类也可以很好的解决问题。这是因为人可以主动的去查找相关信息,然后汇总形成方案。
这一思路就是基于搜索的思路,它是目前可操作性更强的方案。
在ChatGPT类的模型中应用搜索机制就变成:
- 将所有知识文档搜集起来,然后拆分为小的文档,比如一篇文档2000字
- 对每一篇2000字的小文档进行向量化(采用大语言模型将其编码为向量,并使得这个向量与可能的问题具备较高的相关度),然后存储起来
- 在用户提出一个问题之后,将问题采用相同的方式编码为向量
- 将问题对应的向量与所有知识小文档向量计算相关度,选出相关度最大的几个文档
- 将这些选中的小文档提取出来,构造一个提示语传给大语言模型,让大语言模型根据这些上下文回答问题

目前有很多开源库支持以这样的方式来扩充ChatGPT类模型的知识。比如LlamaIndex、LangChain等。
它们的主要特点是:
- 支持很多直接可用的经过验证文档向量化模型(如OpenAI的Ada模型、基于LLAMA的各类开源模型等)
- 提供多种方式实现上述第4步中的相关文档查找,比如基于向量存储库、基于树索引等
- 提供了一些常见的小文档使用模式及对应的上述第5步中的提示语,比如直接组合小文档的方式,基于每个小文档一步一步优化答案的方式,并行基于每个小文档生成回复然后一次性组合的方式等,详见这里
一个简单的用LangChain实现的用例只需要几行代码:
1 | from langchain.embeddings.openai import OpenAIEmbeddings |
虽然看起来基于搜索的方案是目前给大语言模型注入知识的最佳方案,但实际效果却未也必能达到预期。
从实现原理来看,有很多因素可以导致效果下降,比如大文档切分时将关键的文本句子拆分为了不合理的小文档,文档搜索漏掉了某些关键的文档,搜索出来的相关但非关键的文档排名更靠前,组合得到的提示语过于简单等。
事实上,人类在决策时大量还是基于记忆而非搜索的知识的,这部分可能只能通过第一种方式(基础模型优化)才能更好的解决。
总结
本文分享了ChatGPT类大语言模型在当下应用时的局限性,并分析了改善的方法。虽然目前大语言模型还远未达到完美,但我们可以看到很多聪明的大脑正在为解决这个问题贡献极具创意的方案,相信不久的将来这些问题都会迎刃而解!
将来的大语言模型的应用会是怎样的?大胆的猜测一下,大概是每个人一个模型,每个团队一个模型,每个公司一个模型吧,这些大语言模型具备不同程度的背景知识,可以更精准更贴心的帮助我们更智慧的解决问题。
自ChatGPT发布以来,很多人认为这是一个人类走向通用人工智能的突破,也有一些人认为它其实没什么本质的改进。有很多人对自己的职业发展产生了很深的焦虑感,也有很多人感觉触碰到了科幻世界中的未来,还有很多人觉得又是一个可以好好捞一把的机会。
也许每个人都有必要去了解一下机器学习技术的原理,这样才能形成对它的理性的认知。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
这是此系列的第六篇,突破ChatGPT的知识限制。
参考
- 语言大模型100K上下文窗口的秘诀: https://juejin.cn/post/7249173717751087164
- Transformer升级之路:7、长度外推性与局部注意力:https://kexue.fm/archives/9431
- Transformer升级之路:8、长度外推性与位置鲁棒性: https://kexue.fm/archives/9444
- Transformer升级之路:9、一种全局长度外推的新思路: https://kexue.fm/archives/9603
- The Secret Sauce behind 100K context window in LLMs: https://blog.gopenai.com/how-to-speed-up-llms-and-use-100k-context-window-all-tricks-in-one-place-ffd40577b4c
- What are Embeddings: https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
- FlashAttention: https://shreyansh26.github.io/post/2023-03-26_flash-attention/
- Fast Transformer Decoding: One Write-Head is All You Need: https://arxiv.org/abs/1911.02150
- LangChain-Question answering over documents: https://python.langchain.com/docs/use_cases/question_answering.html