作为一个一直对AI技术很感兴趣的软件开发工程师,早在深度学习开始火起来的15、16年,我也开始了相关技术的学习。当时还组织了公司内部同样有兴趣的同学一起研究,最终的成果汇集成几次社区中的分享以及几篇学习文章(见这里)。
从去年OpenAI发布ChatGPT以来,AI的能力再次惊艳了世人。在这样的一个时间节点,重新去学习相关技术显得很有必要。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
ChatGPT本身就具备很丰富的知识,所以ChatGPT自身实际上就是一个很好的学习渠道,我也将借助ChatGPT来学习ChatGPT。
这是此系列的第五篇,ChatGPT的自动优化。
上一篇文章我们深入分析了ChatGPT是如何训练及优化的,了解了如何进行监督微调,及如何让模型可以支持更广泛领域的问答。但是,监督微调始终会限于训练集中的问题模板数量,无法支持更为一般的对话。这一步骤就需要引入强化学习的训练方式,让ChatGPT可以自动进行优化。
介绍
强化学习模型是最为复杂的部分,参考ColossalAI的文档,模型的工作原理如下:
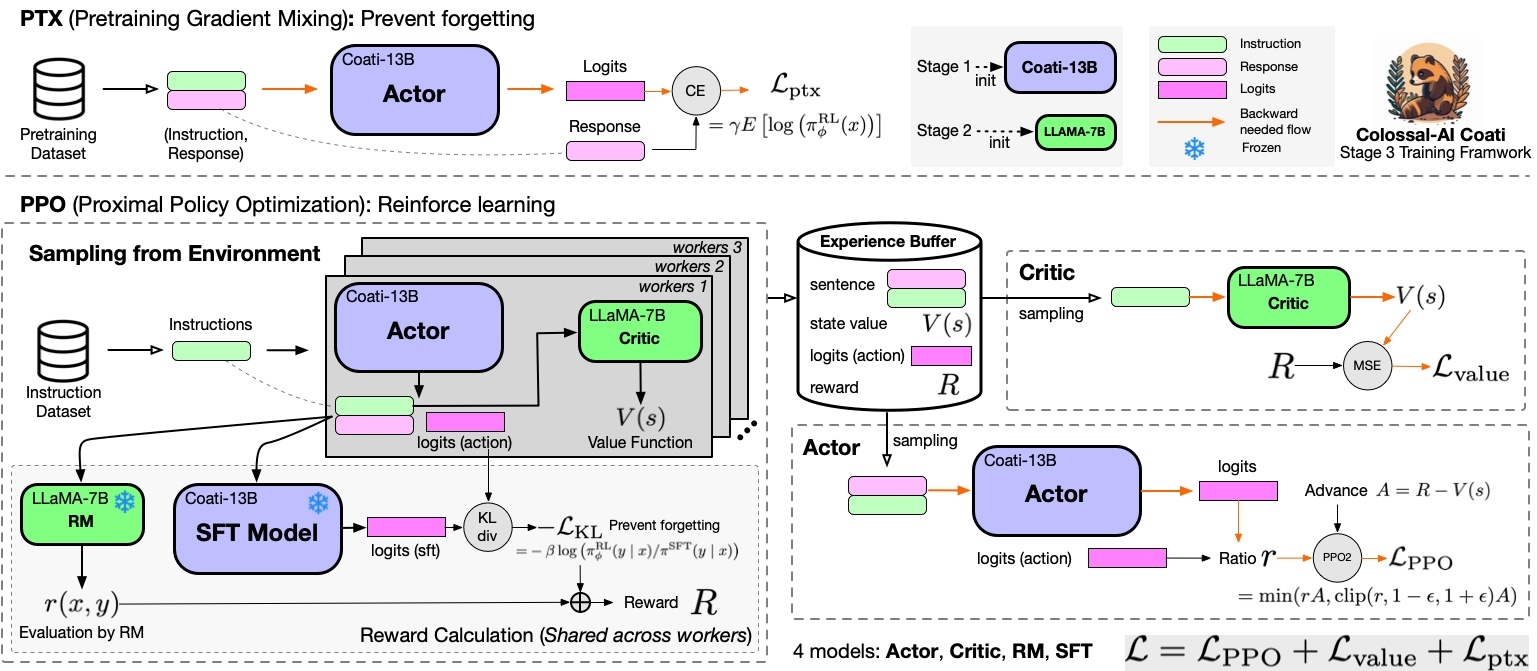
为了理解上图,需要先了解一下强化学习相关的背景知识。
强化学习
强化学习(Reinforcement Learning,简称RL)是一种机器学习方法,旨在使智能体(agent)通过与环境的交互来学习适应环境并制定实现特定目标的策略。在强化学习中,智能体通过观察环境的状态,执行动作,并接收环境的奖励或惩罚来不断调整自己的策略,以获得最大化累积奖励的能力。
强化学习的基本要素包括:
- 智能体(Agent):智能体是进行学习和决策的主体,它通过观察环境的状态、选择合适的动作,并与环境进行交互。
- 环境(Environment):环境是智能体所处的外部世界,它可以是真实的物理环境,也可以是抽象的模拟环境。环境会根据智能体的动作进行状态转移,并根据智能体的表现给予奖励或惩罚。
- 状态(State):状态是描述环境的特征或信息,它可以是完全观察的,也可以是部分观察或隐含的。智能体的决策往往基于当前状态。
- 动作(Action):动作是智能体在某个状态下可以执行的操作或策略。智能体的目标是根据当前状态选择最优的动作。
- 奖励(Reward):奖励是环境根据智能体的动作和表现给予的反馈信号,用于指示动作的好坏。智能体的目标是通过最大化累积奖励来学习合适的策略。
在ChatGPT这个场景中,ChatGPT模型即智能体,环境是一个对话系统,状态是当前对话的上下文及当前消息,动作是如何选择某一个回复,奖励是人类反馈的回复质量好或差。
强化学习的核心问题是通过智能体与环境的交互来学习一个最优的策略,以使智能体在长期累积奖励的过程中能够获得最大化的回报。强化学习算法通常基于价值函数或策略函数来进行决策和优化,其中价值函数用于评估状态或状态动作对的价值,策略函数用于指导智能体在特定状态下选择动作。
强化学习常常应用于机器人控制、游戏智能、自动驾驶等领域。
强化学习算法
如何学习最优策略呢?常见的学习算法包括Q-learning、SARSA、Deep Q-Network(DQN)、Policy Gradient、Proximal Policy Optimization(PPO)、Actor-Critic等。
以下简要介绍和RLHF相关的算法:
- Q-learning: 核心思想是学习一个状态-动作价值函数(Q函数),它衡量在给定状态下采取特定动作的长期累积回报。可根据贝尔曼公式
Q(s,a) = Q(s,a) + α(r + γ * max(Q(s',a')) - Q(s,a))更新及优化Q函数,其中α是学习率,γ是折扣因子,r是奖励,s’是新的状态。 - Policy Gradient(策略梯度)算法: 不需要建立值函数模型,而是直接优化策略(动作的选择)。其基本思想是通过采样经验轨迹(trajectory),通过最大化累积奖励来计算策略梯度,并利用梯度信息更新策略参数。
- Proximal Policy Optimization(PPO):一种基于策略梯度的强化学习算法,旨在通过有效地优化策略函数(通过引入一个重要性采样比率和一个剪切函数来限制策略更新的幅度,以保持策略的相对不变性)来提高强化学习的性能和稳定性。
- Actor-Critic(演员-评论家)算法:结合了值函数和策略函数的强化学习算法。它通过同时学习一个策略函数(演员)和一个值函数(评论家),以提高强化学习的效率和性能。演员根据评论家的评估结果来更新策略,从而改进策略的质量。评论家则通过学习一个值函数来估计每个状态的值或动作值,以提供演员关于策略改进的反馈。
RLHF算法结合了PPO和Actor-Critic算法的优势,所以可以高效而又稳定的优化ChatGPT的模型。
代码分析
有了前面的了解,下面咱们跟着代码一起来了解一下算法的细节。
使用PyTorch实现Policy Gradient
下面来看PyTorch的示例中提供的一个参考的策略梯度算法实现。
先介绍一下gym库,这个库提供了一个模拟环境,内置了很多小游戏,可以帮助我们开发强化学习算法。
比如下面这个平衡杆小游戏,我们要想办法控制平衡杆使其一直位于连接点的上方。有两个动作可以用来控制游戏中的连接点,即左和右。控制连接点向左时,可以避免平衡杆往左倾倒。控制连接点向右时,可以避免平衡杆往右倾倒。
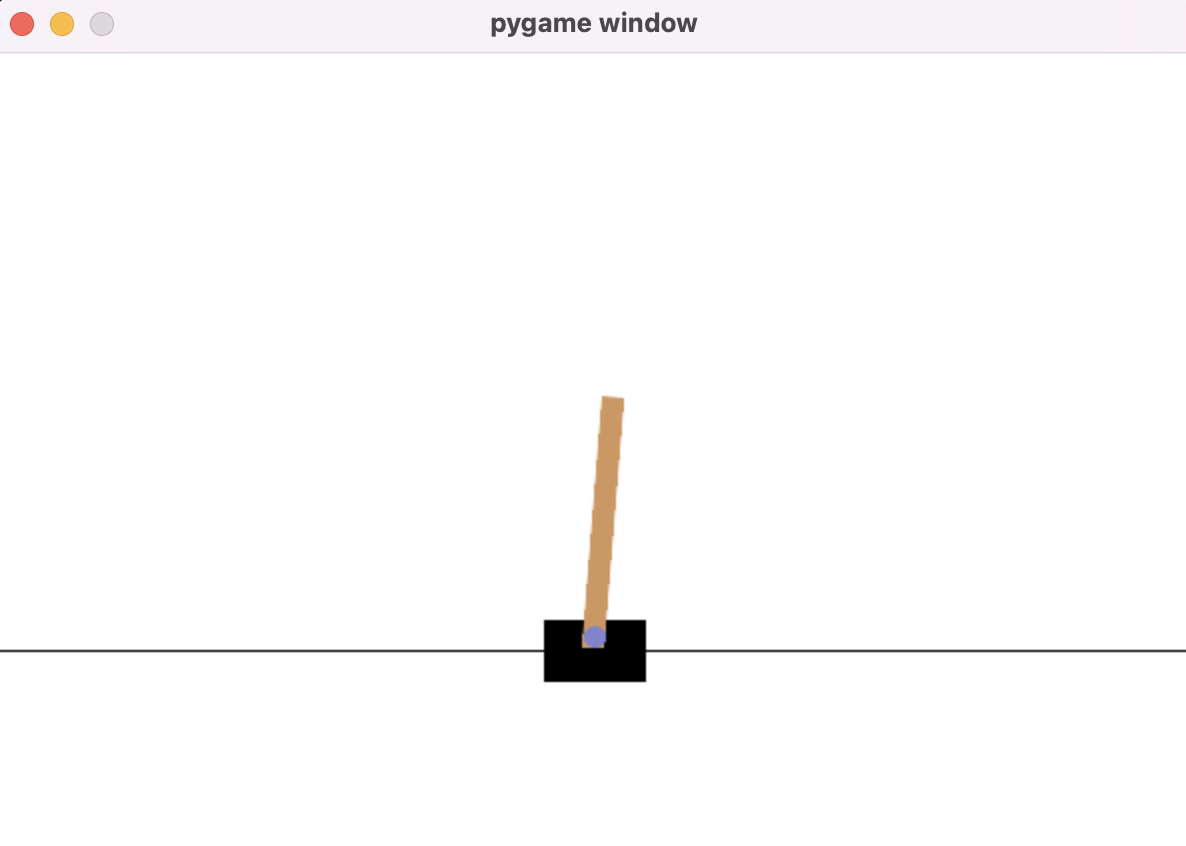
下面来用策略梯度的方法训练一个强化学习算法让机器人自动玩游戏。
1 | class Policy(nn.Module): # 定义策略函数网络,输出每个动作对应的概率 |
完整代码见这里。运行以上算法可以看到以下日志:
Episode 10 Last reward: 21.00 Average reward: 16.30
Episode 20 Last reward: 41.00 Average reward: 24.02
Episode 30 Last reward: 33.00 Average reward: 33.05
Episode 40 Last reward: 64.00 Average reward: 50.71
Episode 50 Last reward: 73.00 Average reward: 59.70
Episode 60 Last reward: 41.00 Average reward: 63.28
Episode 70 Last reward: 59.00 Average reward: 63.88
Episode 80 Last reward: 86.00 Average reward: 80.87
Episode 90 Last reward: 125.00 Average reward: 91.54
Episode 100 Last reward: 224.00 Average reward: 136.09
Episode 110 Last reward: 95.00 Average reward: 182.31
Episode 120 Last reward: 200.00 Average reward: 170.03
Episode 130 Last reward: 80.00 Average reward: 149.48
Episode 140 Last reward: 102.00 Average reward: 148.63
Episode 150 Last reward: 644.00 Average reward: 349.26
Solved! Running reward is now 550.1608406568259 and the last episode runs to 2888 time steps!
可以看到,在算法玩了150多次游戏的时候,已经可以玩得非常好了。但是我们也能注意到算法有一些波动,特别是在100局到110局时,曾经达到一个不错的水平,但是后来突然又有一些下降。
使用PyTorch实现Actor-Critic
Actor-Critic算法与Policy Gradient算法是类似的。下面看一下代码:
1 | SavedAction = namedtuple("SavedAction", ["log_prob", "value"]) |
完整代码见这里。运行以上算法可以看到以下日志:
Episode 10 Last reward: 32.00 Average reward: 14.11
Episode 20 Last reward: 89.00 Average reward: 32.64
Episode 30 Last reward: 20.00 Average reward: 45.73
Episode 40 Last reward: 32.00 Average reward: 47.44
Episode 50 Last reward: 332.00 Average reward: 142.78
Episode 60 Last reward: 410.00 Average reward: 428.13
Solved! Running reward is now 476.8880228063767 and the last episode runs to 1334 time steps!
可以看到算法在经历60多次的迭代之后就有一个很好的效果了。
ChatGPT的RLHF算法
ColossalAI中使用的强化学习算法与上述算法基本一致,完整代码的入口在这里, 代码比较长,以下是简化后的代码:
1 | def main(args): |
上述代码中用到了KL散度。KL散度(Kullback-Leibler divergence)是一种用于衡量两个概率分布之间差异的指标。在信息论和统计学中广泛应用。
给定两个离散概率分布P和Q,它们的KL散度定义为:KL(P || Q) = Σ P(i) * log(P(i) / Q(i)) 其中,P(i)和Q(i)分别表示P和Q在第i个事件上的概率。
KL散度不具备对称性,即KL(P || Q) ≠ KL(Q || P)。它度量的是从P到Q的信息损失或差异。KL散度的值为非负数,当且仅当P和Q相等时,KL散度等于0。当P和Q之间的差异增大时,KL散度的值也会增大。
在深度学习中,KL散度常用于衡量生成模型生成的样本分布与真实数据分布之间的差异。通过最小化KL散度,可以使生成模型逼近真实数据分布,从而提高生成样本的质量。在上述代码中,KL散度被用于计算奖励信号。通过比较动作对数概率与基准动作对数概率之间的差异,可以衡量动作选择与基准模型之间的差异程度,进而调整奖励的大小。
RLHF算法总结
回顾RLHF算法的过程,可以看到,由于我们之前训练了一个奖励函数,RLHF算法在执行过程中,可以没有人类的参与而自动进行。奖励函数代替人给出了对于模型生成的回复的质量的反馈。
到这里,大家可以理解为什么ChatGPT可以如此智能的回复大家的任意的自然语言问题了吧?OpenAI开放ChatGPT模型给大家使用,随着大家使用越多,OpenAI就可以根据RLHF的算法让模型接触到更多的对话,从而基于这些对话自动的优化ChatGPT!
总结
到这里,我们就分析完了所有的ChatGPT类模型的训练和微调、RLHF微调的代码。在分析代码时,我们有意忽略了很多细节及模型并行处理的部分代码,这些对于我们理解模型帮助不大。
到这里大家应该对ChatGPT类模型的训练有一个较为深入的认识了。
自ChatGPT发布以来,很多人认为这是一个人类走向通用人工智能的突破,也有一些人认为它其实没什么本质的改进。有很多人对自己的职业发展产生了很深的焦虑感,也有很多人感觉触碰到了科幻世界中的未来,还有很多人觉得又是一个可以好好捞一把的机会。
也许每个人都有必要去了解一下机器学习技术的原理,这样才能形成对它的理性的认知。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
这是此系列的第五篇,ChatGPT的自动优化。
参考
- alpaca博客介绍:https://crfm.stanford.edu/2023/03/13/alpaca.html
- LLAMA Paper:https://arxiv.org/abs/2302.13971v1
- Self-Instruct: Aligning Language Model with Self Generated Instructions:https://arxiv.org/abs/2212.10560
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality: https://lmsys.org/blog/2023-03-30-vicuna/
- OpenAI开发的ChatGPT资料(Training language models to follow instructions
with human feedback): https://arxiv.org/pdf/2203.02155.pdf - OpenAI开放的GPT-3资料(Language Models are Few-Shot Learners): https://arxiv.org/pdf/2005.14165.pdf
- OpenAI开放的GPT-2资料(Language Models are Unsupervised Multitask Learners): https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- OpenAI开放的GPT资料(Improving Language Understanding by Generative Pre-Training): https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf