作为一个一直对AI技术很感兴趣的软件开发工程师,早在深度学习开始火起来的15、16年,我也开始了相关技术的学习。当时还组织了公司内部同样有兴趣的同学一起研究,最终的成果汇集成几次社区中的分享以及几篇学习文章(见这里)。
从去年OpenAI发布ChatGPT以来,AI的能力再次惊艳了世人。在这样的一个时间节点,重新去学习相关技术显得很有必要。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
ChatGPT本身就具备很丰富的知识,所以ChatGPT自身实际上就是一个很好的学习渠道,我也将借助ChatGPT来学习ChatGPT。
这是此系列的第四篇,ChatGPT的模型训练。
上一篇文章我们深入分析了ChatGPT使用到的Transformer模型。了解了其最核心的模型结构是Transformer结构,本文来聊一聊ChatGPT如何训练。
介绍
ChatGPT只在论文中有一些原理的解释,并没有公布代码。因此,为了弄清楚ChatGPT是如何训练的,我们只能从开源的类ChatGPT模型入手。目前,我们能看到ChatGPT的开源平替主要是来自斯坦福大学的Alpaca模型及伯克利大学的Vicuna模型。其中,当使用GPT-4来评估模型效果时,Vicuna模型的效果达到了ChatGPT的90%。这说明这些开源平替模型的正确性和有效性。
Alpaca模型及Vicuna模型都是基于Meta发布的LLaMA模型进行微调的。LLaMA的训练使用了大量的数据,并花费了大量的计算资源。
因此本文尝试帮助大家弄清楚这些开源模型的训练。当我们了解了这些开源模型的训练时,应该也能对ChatGPT的模型训练有了一个基本的了解了。
训练过程
从ChatGPT公布的论文内容来看,有三个训练阶段:1. 无监督预训练 2. 监督微调 3. 指令微调。
无监督预训练是指直接使用大规模的文本数据作为输入来构建数据集,其输出就是当前文本中的下一个词。比如,文本“无监督训练”,可以拆分为如下几个训练样本:
- 输入“无”,让模型预测“监督”
- 输入“无监督”让模型预测“训练”
通过采集互联网上的大规模文本,可以构造一个超大规模的数据集用于无监督预训练。
监督微调是指在输入文本中放入具体的任务信息,让模型尝试预测答案。比如,对于一个中文翻译为英文的任务可以构建训练样本如下(假定要翻译的文本为“无监督训练”):
- 输入“翻译文本为英文:无监督训练。译文:”,让模型输出“Non-supervised”
- 输入“翻译文本为英文:无监督训练。译文:Non-supervised”,让模型输出“training”
监督微调阶段可以使用大量的当前NLP研究中的训练数据集。比如:
- 常识推理数据集,如BoolQ、PIQA、SIQA、OpenBookQA等
- 闭卷问答数据集,如Natural Questions、TriviaQA等
监督微调阶段使用了一些自然语言问答的模板,但是如果对话没有使用这样的模板,模型的效果就会大打折扣。于是为了训练一个ChatGPT这样的通用的模型,就需要更普适的问答模板。这就是指令微调阶段的作用。
从OpenAI开放的论文资料来看,指令微调采用了强化学习的方案。分成三个步骤完成:
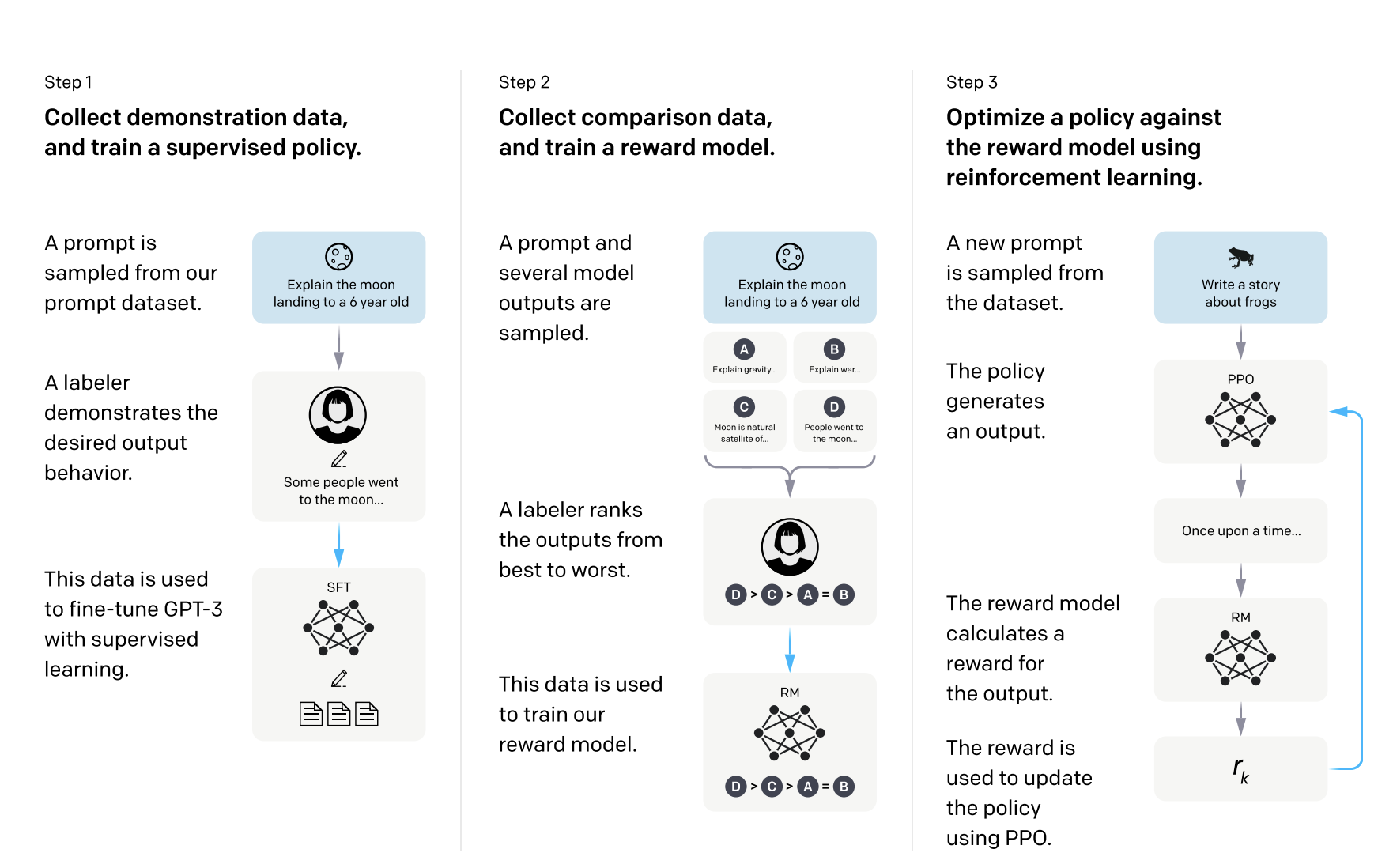
- 第一步:从测试用户提交的问答中随机抽取数据,让专业的标注人员给出高质量的答案,并使用这些数据优化模型。
- 第二步:使用前面的模型生成N个不同的回答,让专业的标注人员对回答的质量进行排序,并使用这些数据训练一个奖励模型。
- 第三步:利用前面训练好的奖励模型,无需人工标注,通过强化学习的方式自动更新模型参数。
这一阶段,通过让模型接受更广泛的自然语言回答任务,模型具备了回答通用问题的能力。
分析上述三个阶段,可以发现第三阶段用到的强化学习训练相对较为复杂,且需要大量人类的参与,目前开源替代并不多,由HPC-AI开源的ColossalChat算是较为完善的一个。
上述提到的这些开源模型分别完成的阶段如下:
- LLaMA模型:利用开放的数据集完成了第一阶段和第二阶段
- Alpaca、Vicuna模型:基于LLaMA,利用基于ChatGPT生成的指令数据,完成了第三阶段的第一步
- ColossalChat:完成了完整的三个阶段
模型训练代码
下面基于上述提到的三个模型分析一下模型的训练代码。
LLaMA的官方代码库中只有模型的结构及推理的代码,而没有包含训练的代码。虽然Meta的论文中提到了是如何训练的,但还是没有像可运行的代码这样包含所有细节。
Alpaca、Vicuna、ColossalChat模型作为开源可训练的模型,有完整的训练代码和脚本,我们主要基于它们来研究一下模型是如何训练的。
一般的机器学习模型训练主要包括三部分:定义模型结构、定义损失函数、准备训练数据。下面主要围绕这三部分来分析ChatGPT类模型是如何训练的。
数据生成
根据前文对训练过程的介绍,训练数据只需要组织成一系列的问答对即可。
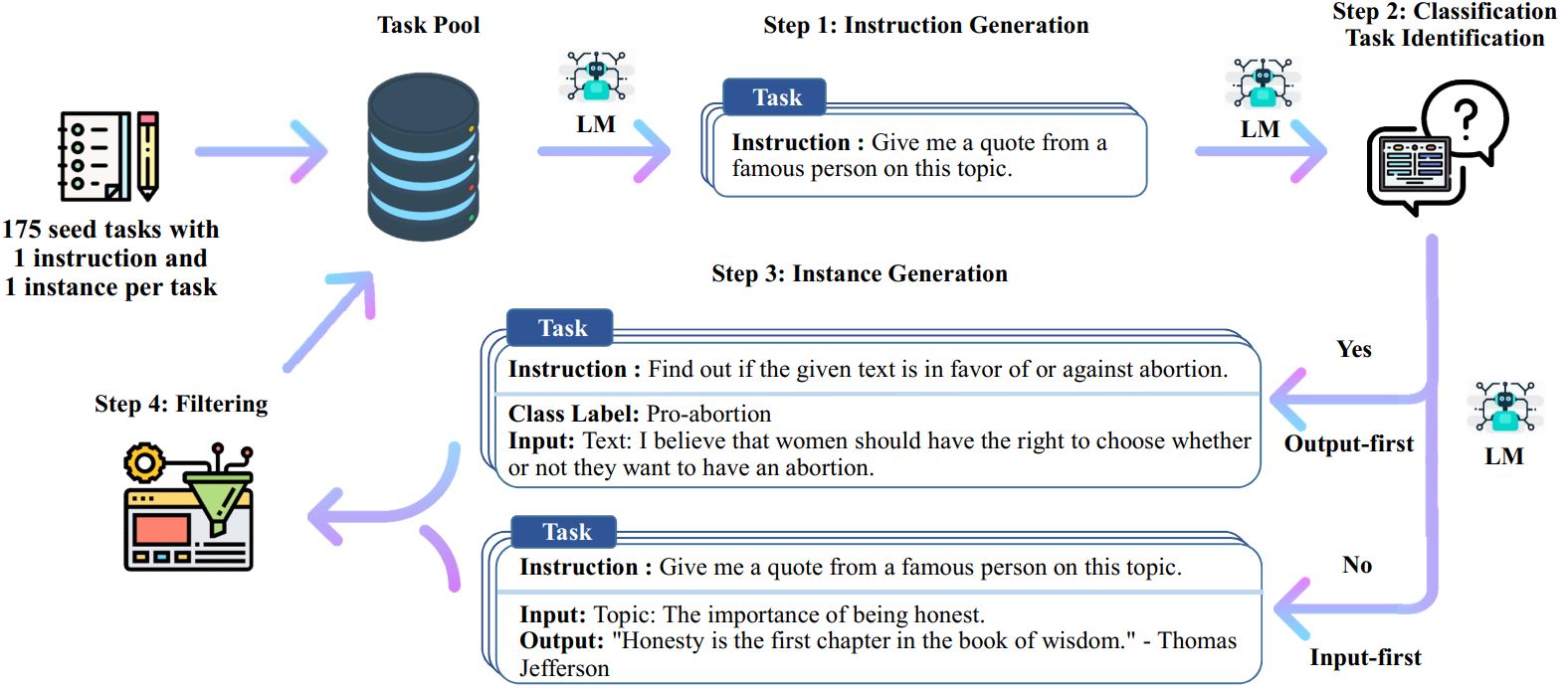
从Alpaca的官方Github代码仓库中的文档可以了解到,Alpaca用到了一种名为Self-Instruct的机制来生成数据。其原理是:
- 定义一些种子任务
- 借助OpenAI发布的模型来生成具备多样性的指令任务
- 借助OpenAI的模型生成这些任务的回复
以下是来自Self-Instruct的官方代码仓库的数据生成流程图。其中Alpaca简化了分类任务和非分类任务,将其合成了同一类问答任务。
下面是一些样例数据:
1 | [ |
Vicuna的模型效果比Alpaca好不少,而且很好的支持了多语言。它的秘诀在于其训练数据与Alpaca通过Self-Instruct的机制生成的数据不一样,质量要高很多。Vicuna的数据来源于 ShareGPT.com 网站上大家分享的与ChatGPT聊天的数据。
ColossalChat模型的性能也可以与ChatGPT比肩(信息来自代码仓库中的博客),它的训练数据来源于InstructionWild,这个数据集基于从Twitter获取的700个基础任务,然后采用与Alpaca类似的机制从OpenAI获取更多样性的任务及回复。
微调部分训练代码
阅读Alpaca和Vicuna的训练代码,可以发现训练代码非常短,主要是调用了transformers库中的Trainer类来完成训练。
所以,要了解训练过程的代码,我们需要阅读一下transformers代码库中的相应代码。
Transformers 是 Huggingface 打造的一个开源库。提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。其宗旨是为最先进的 NLP 技术提供易用性。 Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。(来自官方介绍)
由于Alpaca和Vicuna采用LLaMA作为基础模型,我们主要关注LLaMA相关的代码。源代码在这个目录下。
模型的核心代码在这里,虽然Transformers库中的实现与Meta发布的源代码有所区别,但都是基于PyTorch库,并且模型结构是一致的,就不赘述了(想了解细节的请回顾上一篇)。 下面分析一下与模型训练相关的核心代码。
1 | class LlamaForCausalLM(LlamaPreTrainedModel): |
上述对齐过程,可以举例解释如下:
- 假设有一个句子作为输入文本序列:I love eating,模型将预测下一个词是什么。
- 在这个例子中,预测结果序列为
love eating,标签序列I love eating也应该调整为与预测序列一致。 - 通过取预测结果的前N-1个及标签数据的后N-1个,就可以将logits与标签数据对齐。
可以看到这里的训练代码其实非常简单,使用最常见的基于概率的交叉熵损失即可实现损失定义。至于反向传播过程,PyTorch已经为我们实现了,训练时程序可以自动计算梯度,我们无需实现反向传播的过程。
强化学习部分训练代码
下面来分析一下由ColossalAI实现的指令微调阶段的模型及代码。根据上面的分析,指令微调阶段分为三个步骤完成:1. 与第二阶段相同的监督微调; 2. 训练一个奖励模型;3. 训练一个强化学习模型。
监督微调
看起来第一步骤的代码与Alpaca和Vicuna的代码应该是一样的,不过ColossalAI为了支持在单卡上面做训练,采用了Lora的方式进行监督微调。
Lora是一种少量参数模型微调的方法,由微软于2021年提出。其基本的思想是:
- 冻结所有原来的大模型参数
- 对某些层(一般是线性变换层)的参数,采用两个小矩阵合成一个与原参数大小一样的大矩阵(如采用一个10x2的矩阵A和一个2X10的矩阵B,两者的矩阵乘积就可以得到一个10x10的大矩阵C)
- 计算时(前向计算),参数的值采用原参数矩阵加上合成矩阵的值作为最终参数矩阵的值
- 微调时(反向传播),只更新上述小矩阵的参数
具体代码在这里,以下是核心逻辑。(ColossalAI由于支持了多个模型,其代码比较长,以下是单独看LLaMA模型的简化后的代码。)
1 | def train(args): |
可以看到,上述代码中ColossalAI还贴心的采用了一种累计梯度的机制来支持小批微调。这是因为想要在少量的GPU资源上微调大模型,批大小不能设置太大,否则显存无法支持。关于累计梯度详细的解释,可以参考这里。
奖励模型
第二个步骤是定义并训练一个奖励模型,此模型可以判断哪些回复更好。ColossalAI依然基于大语言模型,并采用Lora微调,来实现这个奖励模型。
具体代码在这里,以下是核心逻辑。(ColossalAI由于支持了多个模型,其代码比较长,以下是单独看LLaMA模型的简化后的代码。)
1 |
|
参考Huggingface上面的数据集,可了解到训练奖励模型用到的数据示例为:
- prompt (string): Human: I am trying to write a fairy tale. What is the most popular plot? Assistant: The … Human: The … Assistant:
- response (string): This sounds like a really interesting modern retelling of the story!
- chosen (string): This sounds like a really interesting modern retelling of the story!
- rejected (string): And the prince and the princess both decide that they are more powerful together than apart?
通过上面的分析,可以知道,奖励模型可以为每一个回复生成一个奖励值。这个奖励值就可以用于训练强化学习模型了。
对于奖励模型的训练,OpenAI论文原文解释如下:
RM是在一个包含两个模型输出之间比较的数据集上进行训练的。他们使用交叉熵损失,将比较结果作为标签,而奖励之间的差异表示了一个人类标注者更喜欢其中一个回答的对数几率。为了加快比较收集的速度,我们向标注者展示了K = 4至K = 9个回答供其进行排名。这为每个提示产生了K²个比较。由于每个标注任务中的比较非常相关,我们发现,如果我们简单地将比较混洗到一个数据集中,对数据集进行一次遍历就会导致奖励模型过拟合(如果将每个可能的K²个比较视为单独的数据点,那么每个完成将可能被用于K-1个独立的梯度更新。模型往往在一个epoch后出现过拟合,因此在一个epoch内重复数据也会导致它出现过拟合)。相反,我们将每个提示的所有K²个比较作为单个批次元素进行训练。这样做在计算上更加高效,因为每个完成(completion)只需要一次RM的前向传播(而不是K个完成需要K²次前向传播),并且由于不再过拟合,验证准确度和对数损失都有显著提升。
损失计算公式为:
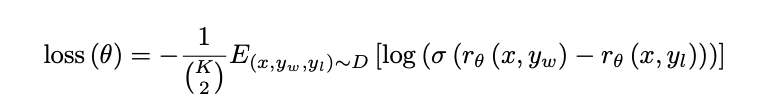
其中,rθ(x, y)是奖励模型对于提示x和完成y的标量输出,具有参数θ;yw是在yw和yl这一对完成中更受青睐的完成;D是人类比较的数据集。
最后,由于奖励模型的损失对于奖励的偏移是不变的,我们使用偏置对奖励模型进行归一化,以使标注者的演示在进行强化学习之前获得平均得分为0。
强化学习模型
强化学习模型是最为复杂的部分,涉及很多新的知识点,限于篇幅,待下一篇继续分析。
不过,事实上基于前面的监督微调部分及奖励模型部分代码,我们似乎已经能窥探到强化学习部分的内容了。
总结
到这里,我们就分析完了ChatGPT类模型的训练和微调代码。在分析代码时,我们有意忽略了很多细节及模型并行处理的部分代码,这些对于我们理解模型帮助不大。
自ChatGPT发布以来,很多人认为这是一个人类走向通用人工智能的突破,也有一些人认为它其实没什么本质的改进。有很多人对自己的职业发展产生了很深的焦虑感,也有很多人感觉触碰到了科幻世界中的未来,还有很多人觉得又是一个可以好好捞一把的机会。
也许每个人都有必要去了解一下机器学习技术的原理,这样才能形成对它的理性的认知。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
这是此系列的第四篇,ChatGPT的模型训练。
参考
- alpaca博客介绍:https://crfm.stanford.edu/2023/03/13/alpaca.html
- LLAMA Paper:https://arxiv.org/abs/2302.13971v1
- Self-Instruct: Aligning Language Model with Self Generated Instructions:https://arxiv.org/abs/2212.10560
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality: https://lmsys.org/blog/2023-03-30-vicuna/
- OpenAI开发的ChatGPT资料(Training language models to follow instructions
with human feedback): https://arxiv.org/pdf/2203.02155.pdf - OpenAI开放的GPT-3资料(Language Models are Few-Shot Learners): https://arxiv.org/pdf/2005.14165.pdf
- OpenAI开放的GPT-2资料(Language Models are Unsupervised Multitask Learners): https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- OpenAI开放的GPT资料(Improving Language Understanding by Generative Pre-Training): https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- 梯度累加:https://zhuanlan.zhihu.com/p/595716023