作为一个一直对AI技术很感兴趣的软件开发工程师,早在深度学习开始火起来的15、16年,我也开始了相关技术的学习。当时还组织了公司内部同样有兴趣的同学一起研究,最终的成果汇集成几次社区中的分享以及几篇学习文章(见这里)。
从去年OpenAI发布ChatGPT以来,AI的能力再次惊艳了世人。在这样的一个时间节点,重新去学习相关技术显得很有必要。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
ChatGPT本身就具备很丰富的知识,所以ChatGPT自身实际上就是一个很好的学习渠道,我也将借助ChatGPT来学习ChatGPT。
这是此系列的第三篇,ChatGPT使用的Transfomer模型。
上一篇文章我们聊到了ChatGPT使用的技术概览。了解了其最核心的模型结构是Transformer结构,本文来聊一聊Transformer模型。
介绍
Transformer的网络结构最早是Google在2017年的时候提出的,论文名称是《Attention Is All You Need》。从论文名称也能看出,Transformer结构强调了注意力机制在网络结构中的表示和应用。
当时这篇论文面世时,不少研究人员还认为标题有点夸大了注意力机制的作用。现在来看,似乎还真有注意力机制一统天下的势头。
下面我们将一起来揭开这个网络结构的面纱。
原始的Transfomer模型
原始的Transformer的整体结构比较复杂,以下是来自论文中的截图。
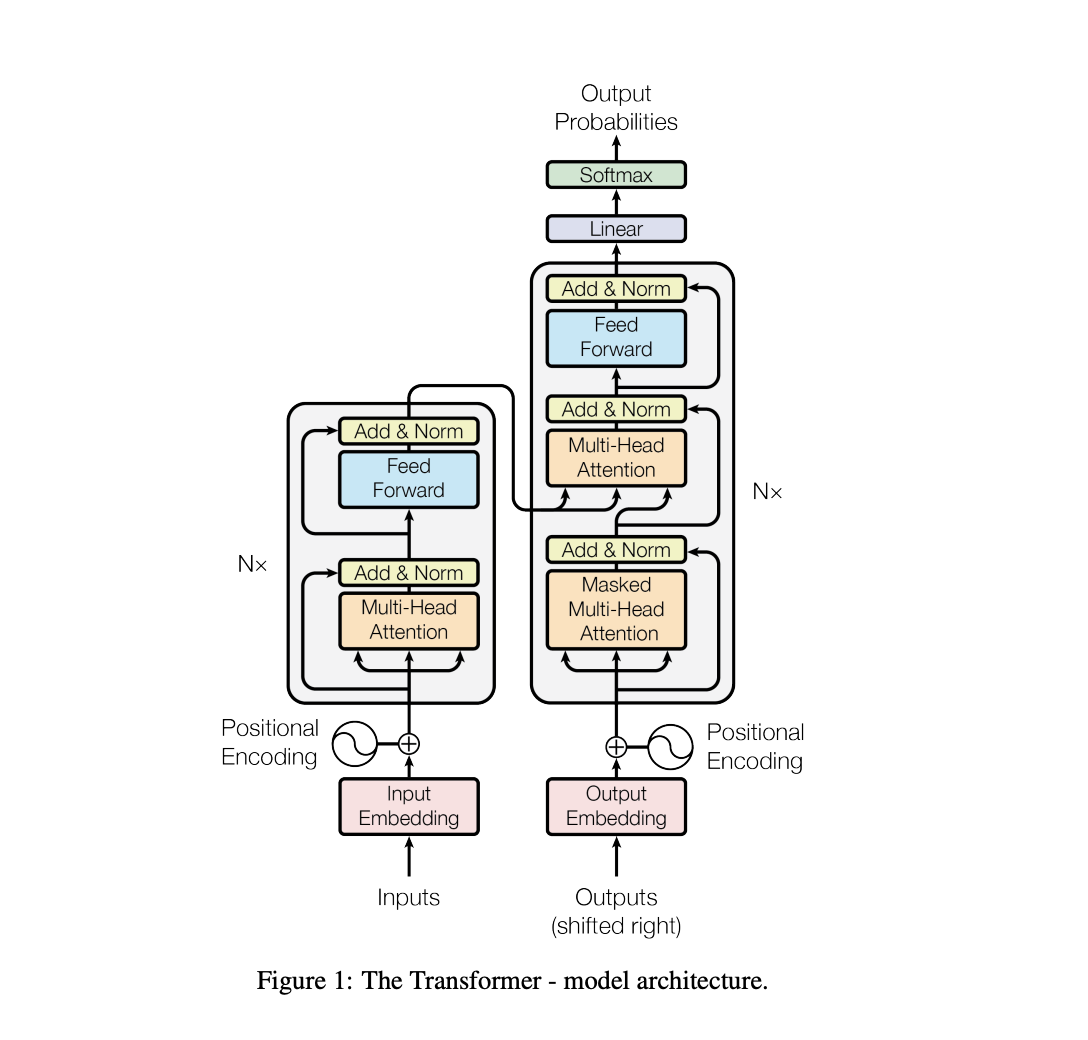
可以看到,Transformer网络的主要由编码器和解码器组成。虽然看起来复杂,但实际上,编码器和解码器都是由多个相同的层堆叠而成,并且编码器和解码器结构也很相似。
编码器(Encoder)每一层内结构为:
- 输入嵌入(Input Embedding):将输入序列中的每个单词或符号转换为连续的向量表示。
- 位置编码(Positional Encoding):为输入序列中的每个位置添加一个表示位置信息的向量。
- 多头自注意力(Multi-Head Self-Attention):通过对输入序列中的每个位置进行自注意力计算,从全局上理解输入序列间的关系和重要性。
- 前馈神经网络(Feed-Forward Neural Network):在每个位置上应用一个全连接前馈神经网络,以对自注意力输出进行进一步的非线性变换。
- 残差连接(Residual Connections)和层归一化(Layer Normalization):在每个子层之间应用残差连接和层归一化,以帮助梯度流动和减少训练中的梯度消失问题。
解码器(Decoder)每一层内结构为:
- 编码器-解码器注意力(Encoder-Decoder Attention):除了自注意力,解码器还对编码器的输出进行注意力计算,以利用编码器对输入序列的理解。
- 解码器自注意力(Decoder Self-Attention):类似于编码器的自注意力,但在解码器中应用于当前位置以前的输出。
- 前馈神经网络:与编码器中的前馈神经网络相同。
- 残差连接和层归一化:与编码器中的残差连接和层归一化相同。
通过堆叠多个编码器和解码器层,Transformer可以具备强大的能力。注意力机制还允许Transformer网络模型自动学习输入序列中的各个单词的依赖关系,并且可以通过并行计算来加速计算过程。
这里有一篇博客详细的介绍了每一个结构内部的实现机制。推荐大家阅读以了解细节。
如果希望阅读完整的代码,Transformer的完整代码在Google的TensorFlow框架和Meta的PyTorch框架中均有实现。TensorFlow的代码入库在这里,不过其代码风格偏函数式风格,并不是很容易理解。PyTorch中的代码相对更容易理解,有兴趣阅读代码的可以看这里,只需要阅读其forward函数即可了解到整个网络的结构。
ChatGPT中的Transfomer模型
ChatGPT中的Transformer模型与原始的Transformer模型有一些差异。主要区别是将Transformer中的Encoder-Decoder双模块设计简化为只有一个Decoder模块。其实也可以认为是只有一个Encoder模块,因为Encoder和Decoder模块本来就很相似。这里之所为大家认为是Decoder,是因为Transformer和ChatGPT的Decoder是自循环的,因为Decoder会根据前一部分的文本生成下一个单词。
在这个单模块中,Self-Attention被替换为了Masked Self-Attention。
Masked Self-Attention在计算时,会将当前输入文本中不存在的部分给遮蔽掉,只对已知的文本信息进行计算。遮蔽其实只是在训练阶段有效,因为训练阶段的输入文本是已知的所有文本。遮蔽掉当前单词的后续单词就可以让模型在无法获取后面单词的信息,使得这一场景与预测阶段的一致。
作为一个程序员,如果不能从代码的粒度去理解,始终会觉得理解不够透彻。下面我们结合代码来详细了解一下Transformer的计算过程。
在这里,我将用来做LLAMA模型的代码实现作为参考,与大家一起结合代码进行分析。LLAMA模型是Meta的研究团队开发的一个与ChatGPT类似的模型,其核心模型结构与ChatGPT的模型是一致的。
LLAMA的实现代码非常短,很适合拿来作为学习材料。完整的代码在这里。下面将结合代码与Transformer的原理进行分析。
文本生成逻辑
LLAMA生成文本的代码入口在这里,下面说明一下代码中关键的行为:
(为了说明代码主要的功能,以下代码仅截取了关键的代码行,并进行了注释,以便大家更容易阅读。)
1 | # 整个程序的入口函数 |
这就是入口代码的主要逻辑。下面我们分析一下涉及到的几个核心子步骤。
词嵌入
词嵌入是将文本编码为数值的过程。LLaMA在进行词嵌入时,选择了sentencepiece库来实现。
SentencePiece 是一个开源的文本处理库,用于处理和生成分词模型。它的主要作用是将文本分割成子词(subwords)或标记(tokens),以便用于各种自然语言处理任务,例如机器翻译、文本分类、命名实体识别等。
SentencePiece 提供了基于不同分割算法的分词方法,包括未经训练的模型和基于训练数据的模型。它支持的分割算法包括 BPE(Byte-Pair Encoding)、Unigram 等。使用 SentencePiece,可以根据具体任务和需求创建自定义的分词模型。
通过使用 SentencePiece 库,可以实现以下功能:
- 文本分词:将文本分割成子词或标记,提供更细粒度的语言处理单元。
- 词汇表生成:根据训练数据生成词汇表,用于构建词汇表索引或编码器-解码器模型。
- 子词编码:将文本转换为子词序列,以便在模型中进行处理和表示。
- 子词解码:将子词序列转换回原始文本,用于生成文本或进行后处理。
SentencePiece 被广泛应用于各种自然语言处理任务和模型,特别是在跨语言和非常规语言处理方面具有很大的灵活性和适应性。它的灵活性使得可以根据不同语言、文本类型和任务的需求,定制化地构建分词模型,从而提高模型性能和效果。
下面是Tokenizer的核心代码分析:
1 | class Tokenizer: |
温度参数
生成文本时,有两个重要的参数:温度(temperature)和top-p。它们是如何产生作用的呢?
温度参数(temperature)在生成文本过程中起到控制多样性的作用。较高的温度值会增加生成文本时的随机性,使得模型更加倾向于选择概率较小的标记,从而产生更多样化的输出。
具体来说,温度参数会影响 softmax 操作中的指数运算。在 softmax 函数中,通过将 logits 值进行指数运算并归一化,将其转换为概率分布。温度参数的作用是调整指数运算的敏感度。较高的温度值会使指数运算的结果更加平滑,减小了各个标记之间的概率差异,降低了概率较大的标记相对于概率较小的标记的优势。这样,在生成过程中,模型更有可能选择概率较小的标记,从而产生更多样化的输出。
举个例子,假设有一个具有三个候选标记的生成任务,对应的 logits 为 [1.0, 2.0, 3.0]。当温度参数为较低的值(例如1.0)时,通过 softmax 运算后,对应的概率分布为 [0.09, 0.24, 0.67]。可以看到,概率较大的标记 3 相对于其他标记有明显优势,模型更有可能选择标记 3。而当温度参数为较高的值(例如2.0)时,通过 softmax 运算后,对应的概率分布为 [0.19, 0.31, 0.51]。可以看到,概率差异缩小,标记 3 相对于其他标记的优势减小,模型更容易在标记之间进行随机选择。
因此,通过调整温度参数,可以在生成文本时控制多样性。较高的温度值可以增加生成文本的随机性,产生更多样化的输出;而较低的温度值可以增加生成文本的准确性,更倾向于选择概率较大的标记。根据具体的任务需求和应用场景,可以选择合适的温度值来平衡准确性和多样性之间的权衡。
top-p参数
top-p参数用于控制生成文本时的文本选择范围。
实现时,首先,计算 softmax 操作后的概率分布。然后,按照概率从高到低的顺序对概率进行排序。接下来,按照累积概率的方式逐个考虑排名靠前的标记,直到累积概率超过 top-p 的阈值。此时,只有排名靠前的文本才会被保留在选择范围内,其他排名较低的文本会被舍弃。
换句话说,top-p 参数通过动态地确定生成时所需的标记范围,使得生成的结果更加多样化且避免选择概率极低的标记。这种方式比传统的 top-k 采样更加灵活,因为 top-p 参数不依赖于固定的 k 值,而是根据概率分布动态地确定需要保留的标记数量。
下面函数是相关的实现:
1 | def sample_top_p(probs, p): |
函数接受两个参数:probs 是经过 softmax 操作得到的概率分布,p 是 top-p 参数,用于确定保留的概率范围。
根据top-p进行结果选择的逻辑如下:
- 对概率
probs进行排序,并记录排序后的索引,使得概率从高到低排列。 - 计算概率的累积和。
- 创建一个布尔掩码,用于确定哪些概率需要保留。如果累积概率超过了
top-p阈值,则对应的概率置为 0。 - 将概率归一化,使其和为 1,以便进行多项式分布采样。
- 使用多项式采样方法从归一化的概率分布中选取一个下一个标记。
- 使用排序后的索引
probs_idx获取对应的下一个标记。 - 返回选取的下一个标记
next_token。 - 这段代码实现了根据
top-p参数选择结果的逻辑,确保生成的结果在给定的概率范围内,并增加生成文本的多样性。
模型结构
在生成文本的主流程中,构造了Transformer模型进行下一个单词的预测,下面分析一下Transformer模型的结构。
下面的代码需要有一些PyTorch构建神经网络模型的基础知识。对于不了解相关知识的同学,以下是一些要点:
- PyTorch抽象了一个Module类用于构建基本的模型构造块
- 在构建模型构造块时,需要继承Module类并实现其forward方法将输入变换为输出
- 在构建模型构造块时,需要在类的初始化方法
__init__中初始化用到的子构造块 - 在构建模型构造块时,一般不需要关注参数更新的部分,PyTorch提供了自动计算梯度(参数的偏导数)的机制
- PyTorch提供了很多内置的模块或函数,如
fulltriumatmulsilu等,帮助我们更快的复用标准构造块
Transformer相关的完整代码在这里,下面分析一下关键的实现。
1 | class Transformer(nn.Module): |
上述代码用到的核心结构TransformerBlock代码分析如下:
1 | class TransformerBlock(nn.Module): |
注意力机制
Transformer 中的注意力机制(Attention Mechanism)是核心组成部分之一,它在模型中用于捕捉输入序列中的相关信息,并为每个位置分配权重。
注意力的意思就是让模型关注在重要的地方,权重比较高的位置将得到更多的关注。如何实现?通过在每个位置上计算一个加权和就可以了!
Transformer 中使用的是自注意力机制(Self-Attention),即将输入序列中的每个位置视为查询(query)、键(key)和值(value)。通过计算查询与键的相似度得到权重分布,然后将权重与值进行加权求和得到每个位置的输出。
下面是 Transformer 中自注意力机制的主要步骤:
- 对输入序列进行线性变换,分别得到查询(Q)、键(K)和值(V)。
- 计算查询与键的相似度分数,通常使用点积或其他函数(如缩放点积)计算相似度。
- 对相似度分数进行归一化处理,通过 softmax 函数将分数转换为注意力权重。
- 将权重与值进行加权求和,得到加权和作为该位置的输出。
- 将每个位置的输出进行线性变换,得到最终的自注意力输出。
自注意力机制的优势在于它能够捕捉输入序列中的长距离依赖关系,并且能够对不同位置之间的相关性进行灵活的建模。通过自注意力机制,Transformer 可以同时考虑输入序列中所有位置的信息,而无需像循环神经网络那样依次处理序列。
在 Transformer 中,注意力机制通常通过多头注意力(Multi-Head Attention)来进行扩展,即使用多组不同的查询、键和值进行注意力计算,并将它们的输出进行拼接和线性变换,以增加模型的表达能力和学习能力。
总结起来,注意力机制是 Transformer 模型中重要的组成部分,它通过计算查询与键的相似度来为每个位置分配权重,并将权重与值进行加权求和得到输出。它能够捕捉输入序列中的相关信息,提升模型的表达能力和学习能力。
TransformerBlock代码使用到的核心的Attention模块就是注意力机制的实现。这个模块的代码如下:
1 | class Attention(nn.Module): |
旋转嵌入
旋转嵌入(Rotary Embedding)是一种在注意力机制中引入周期性信息的技术,用于增强模型对序列中的顺序关系的建模能力。它通过将输入的查询(Q)和键(K)进行旋转操作,以捕捉序列中位置之间的相对角度。
在注意力机制中,查询和键是通过点积运算来计算相似度得分的,而点积运算本质上是计算两个向量的内积。通过旋转嵌入,可以将原始的查询和键进行旋转操作,将它们的信息编码成一个复数的表示形式,从而引入角度信息。
旋转嵌入的具体操作如下:
- 首先,将查询和键的维度分为实部和虚部两部分。
- 然后,使用三角函数(sin 和 cos)计算旋转角度的正弦和余弦值。
- 将原始的实部和虚部分别与正弦和余弦值相乘,得到旋转后的实部和虚部。
- 最后,将旋转后的实部和虚部重新组合成查询和键的表示。
通过旋转嵌入,查询和键之间的点积运算相当于在复数域中进行了旋转操作,这样可以更好地处理序列中的相对位置关系。旋转嵌入的使用可以提升模型对序列中长距离依赖的建模能力,并有助于捕捉序列中的顺序信息。
需要注意的是,旋转嵌入只应用于查询和键,而值(V)保持不变。这是因为在注意力机制中,查询和键的作用是计算相似度得分,而值则用于根据得分对序列进行加权求和。旋转嵌入的引入主要是为了增强相似度计算的准确性,而对值的处理不需要引入旋转操作。
对应的代码为:
1 | def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0): |
旋转嵌入部分代码略显复杂,并且用到了一些数学计算技巧。如果大家在此理解有困难,也可以忽略它,只需要明白旋转嵌入是为了计算注意力中的查询和键的相似度即可。
如果我们阅读GPT2的代码,可以发现并没有使用旋转嵌入,只是简单的做了矩阵乘法。这是LLAMA引入的一个模型优化方式。
前馈神经网络
整个前馈神经网络的结构为:
- 将输入进行线性变换并输入激活函数
- 将输入进行另一个线性变换并与上述结果相乘
- 将相乘后的结果再次经过线性变换得到最终的输出
对应的代码为TransformerBlock代码使用的FeedForward模块代码,如下:
1 | class FeedForward(nn.Module): |
RMSNorm
上述代码中多次用到了RMSNorm归一化,这是什么技术呢?
其实,RMSNorm(Root Mean Square Normalization)是一种归一化技术,用于在神经网络中对输入进行标准化处理。它旨在增强网络的鲁棒性和稳定性,并有助于减轻输入数据中的噪声和变化对模型的影响。
RMSNorm 的核心思想是基于输入的均方根(RMS)进行标准化。它通过计算输入张量沿指定维度的均方根,并将每个元素除以该均方根值来进行归一化。这种归一化方法相比于传统的均值和方差归一化(例如 Batch Normalization)更加简单和直观。
其代码实现如下:
1 | class RMSNorm(nn.Module): |
掩码
掩码部分也有一些技巧,下面来看看它是如何实现的。
在Transformer的前向计算时,会计算一个掩码矩阵。然后,在计算注意力时,使用此掩码来遮蔽掉无效位置。对应的代码片段如下:
1 | class Transformer(nn.Module): |
在生成掩码时,上述代码生成了一个上三角掩码,以屏蔽未来位置的注意力。
在计算注意力分数时,通过将未来位置的分数设置为负无穷,可以使模型在自回归任务中只依赖于当前及之前的信息。这样可以确保模型在生成序列时不会看到未来位置的信息,保持了模型的自回归性质。
生成掩码的方式如下:
- 首先,创建一个名为 mask 的变量,并将其初始化为 None。这意味着在开始时没有生成掩码。
- 如果 seqlen 大于 1,表示当前处理的序列长度大于 1,存在需要屏蔽的位置。
- 创建一个形状为 (1, 1, seqlen, seqlen) 的张量 mask,并将所有元素的值设为负无穷(float("-inf"))。这里使用 float("-inf") 是为了在计算注意力分数时将被掩盖的位置的注意力分数设为负无穷大,从而在softmax操作后将其值近似为0。
- 使用 torch.triu() 函数将 mask 张量的下三角部分(包括对角线)设为负无穷。这是通过设置 diagonal 参数为 start_pos + 1 来实现的,表示从对角线位置 start_pos + 1 开始屏蔽。这样,注意力机制在计算时将只关注当前位置及之前的位置,而忽略之后的位置。
- 最后,将 mask 张量的数据类型转换为输入张量 h 的数据类型,并将其赋值给 mask 变量。
在代码中,scores 与 mask 相加,实际上是将 mask 中的非负数值添加到 scores 对应位置的元素上。通过这样的操作,可以将特定位置的注意力分数调整为一个较小的值,从而有效地屏蔽或降低模型对该位置的关注度。
总结
到这里,我们就分析完了整个LLAMA模型的代码。需要注意的是,这里的代码只是LLAMA模型在生成文本时(即预测时)要执行的代码。LLAMA在训练阶段会有更多的技巧,也会涉及更多的代码。可惜Meta并没有公布相关的训练代码。
在分析代码时,我们有意忽略了模型并行处理的部分代码,这些是一些并行优化的机制,对于我们理解模型帮助不大。但如果我们希望将这个模型创建为一个服务,从而为大规模的用户服务时,并行处理部分就比较关键了。
在代码分析过程中,我借助了ChatGPT辅助进行理解,并引用了部分ChatGPT生成的内容,当然,也修正了ChatGPT回复中的一些明显的错误。在这个过程中,ChatGPT可以帮助提供足够多的详细的信息,我也深刻的体会到ChatGPT对于代码和我提出的问题的准确理解。可以说,ChatGPT很大程度上帮助我提升了代码分析的效率和学习的效率。
自ChatGPT发布以来,很多人认为这是一个人类走向通用人工智能的突破,也有一些人认为它其实没什么本质的改进。有很多人对自己的职业发展产生了很深的焦虑感,也有很多人感觉触碰到了科幻世界中的未来,还有很多人觉得又是一个可以好好捞一把的机会。
也许每个人都有必要去了解一下机器学习技术的原理,这样才能形成对它的理性的认知。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
这是此系列的第三篇,ChatGPT使用的Transfomer模型。
参考
- Google的Transformer原始论文:https://arxiv.org/pdf/1706.03762.pdf
- Transformer模型详解(图解最完整版):https://zhuanlan.zhihu.com/p/338817680
- LLAMA Paper:https://arxiv.org/abs/2302.13971v1