作为一个一直对AI技术很感兴趣的软件开发工程师,早在深度学习开始火起来的15、16年,我也开始了相关技术的学习。当时还组织了公司内部同样有兴趣的同学一起研究,最终的成果汇集成几次社区中的分享以及几篇学习文章(见这里)。
从去年OpenAI发布ChatGPT以来,AI的能力再次惊艳了世人。在这样的一个时间节点,重新去学习相关技术显得很有必要。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
ChatGPT本身就具备很丰富的知识,所以ChatGPT自身实际上就是一个很好的学习渠道,我也将借助ChatGPT来学习ChatGPT。
这是此系列的第二篇,ChatGPT使用的技术概览。
上一篇文章我们聊到了开发人员对于ChatGPT的认知。本文来聊一聊ChatGPT用到的机器学习技术。
机器学习技术的发展
要聊ChatGPT用到的机器学习技术,我们不得不回顾一下机器学习技术的发展。因为,ChatGPT用到的技术不是完全从零的发明,它也是站在巨人的肩膀上发展起来的。
机器学习技术的分类
实际上机器学习技术可以追溯到上个世纪三四十年代,一开始就与统计学分不开。早在1936年,著名的统计学家Fisher发明了线性判别分析方法(LDA)。LDA利用方差分析的思想,试图将高维数据分开。这后来演化为一类基础的机器学习技术任务,即分类问题。
在计算机出现之后,大量的基于计算机的机器学习算法出现,比如决策树、SVM、随机森林、朴素贝叶斯、逻辑回归等。它们也都可以用于解决分类问题。
分类问题是指我们事先知道要分为哪几类,这些类通常是人为定义的。比如人分为男性和女性,编程语言分为c/c++/java等。
还有一类问题是我们无法预先知道要分为几类的,比如给定一系列的新闻,按照主题进行分组,而我们可能无法事先人为的确定好有几个主题。此时可以利用机器学习算法自动去发现新闻中有几个类,然后再把不同的新闻放到不同的分类。这种问题是聚类问题。
有时,这个分类可能是连续的,比如,我们要用一个机器学习模型去预测某个人的身高,此时可以认为结果是在某一个范围内连续变化的值。这类问题,我们把它叫做回归问题。与分类的问题的区别仅仅在于我们希望输出一个连续的值。
除此之外,一些典型的机器学习问题还包括:降维、强化学习(通过智能体与环境的交互来学习最佳行动策略)等。
除了根据问题不同进行分类,还可以从机器学习技术使用数据的方式进行分类。从这个角度可以将机器学习技术分为有监督学习、无监督学习、半监督学习等。有监督学习要求我们为模型准备好标签值。无监督学习则无需我们准备标签值,只需数据即可开始训练。半监督学习是指需要一部分有标签值的数据。
从解决的问题上来看,ChatGPT可以认为是一个分类模型,它根据输入的文本预测下一个要输出的词是什么,而词的范围是确定的,即模型的输出是一个确定的分类。
从ChatGPT使用数据的方式来看,可以认为是使用了大量的无监督数据,加上少量的有监督的数据。所以,可以认为ChatGPT是一个半监督的机器学习技术。
传统的机器学习算法与基于人工神经网络的机器学习算法
上面提到的决策树、SVM、随机森林、朴素贝叶斯、逻辑回归等算法,多是基于可验证的可理解的统计学知识设计的算法。它们的局限性主要在于效果比较有限,即便使用海量数据也无法继续提升,这要归因于这些模型都是相对简单的模型。由于这些算法都是很早就被开发出来了,并且一直很稳定,没有什么更新,我们一般称这些算法为传统的机器学习算法。
另一类机器学习算法是基于人工神经网络的机器学习算法。这一类算法试图模拟人类的神经网络结构。其起源也很早,要追溯到1943年,W. S. McCulloch和W. Pitts提出的M-P模型。该模型根据生物神经元的结构和工作机理构造了一个简化的数学模型,如下图。
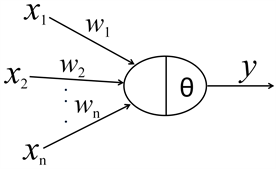
其中,xi代表神经元的第i个输入,权值wi为输入xi对神经元不同突触强度的表征,θ代表神经元的兴奋阀值,y表示神经元的输出,其值的正和负,分别代表神经元的兴奋和抑制。
该模型的数学公式可以表示为: 𝑦=∑𝑤𝑖*𝑥𝑖−𝜃 ,如果所有输入之和大于阀值θ则y值为正,神经元激活,否则神经元抑制。该模型作为人工神经网络研究的最简模型,一直沿用至今。
虽然这个模型看起来很简单,但是由于其可扩展可堆叠的特性,实际上可以用于构造一个非常复杂的网络。至于如何扩展和堆叠,其实就是人工神经网络数十年的发展要解决的问题。
这个模型如何优化呢?这里的优化其实就是修改wi的值,依靠一种名为反向传播的优化方式可以优化它。其计算过程,相当于对wi求偏导数,然后和学习率相乘再加回到原来的wi值上。
人工神经网络模型的算法思想非常简单,其效果只有在网络规模达到一定程度之后才会体现出来。但是一旦网络形成规模之后,对算力和数据的要求就非常高了。这也是为什么在21世纪之前这样的算法无法获得发展的原因。
从2000年开始,互联网进入了爆发式发展的阶段,大量的数据被累积起来,并且计算机算力也经历了数十个摩尔周期得到了长足的发展。于是基于人工神经网络的机器学习算法得到爆发式的发展。
各个研究领域都纷纷开始尝试利用人工神经网络来提升机器学习模型效果。
卷积神经网络(一种基于M-P模型的变种结构)在计算机视觉领域表现突出,逐渐演变为计算机视觉领域的基础结构。循环神经网络和长短期记忆网络(另一种基于M-P模型的变种结构)在自然语言处理领域表现突出,逐渐演变为自然语言处理领域的基础结构。
这两类网络结构曾经风靡一时,即便到现在也有很多问题是基于这两类结构的网络算法去解决的。它们在很大程度上促进了人工神经网络的机器学习算法的发展。
但是,研究人员从未停止对于网络结构的探索。在2017年的时候,Google的研究团队提出了一个名为Transformer的网络结构,强调了注意力机制在网络结构中的表示和应用。Transformer模型结构简单而一致,却表现出了非常好的效果。
ChatGPT的故事可以认为从这里开始了。在Transformer模型结构发布之后,后续有大量的研究基于Transformer开展起来,都取得了很好的效果,这里面就包括各类GPT模型。
最初的Transformer模型主要是应用在自然语言处理领域。近两年的研究发现,这一结构也可以被用到计算机视觉认为上,当前流行的Vision Transformer模型就是它在计算机视觉领域的应用成果。从这个趋势来看,Transformer有着要统一所有模型结构的势头。
ChatGPT技术概览
有了前面的了解,终于轮到ChatGPT出场了。
ChatGPT用到了哪些技术呢?可以简要列举如下:
- 基础模型结构:基于注意力机制的Transformer模型
- 超大规模的模型堆叠:GPT3堆叠了96层网络,参数数量高达1750亿
- 超大的训练数据:采用了45TB的原始数据进行训练
- 超大的计算资源:基于微软专门设计的包含数千块GPU的超级计算机完成训练
- 大规模并行训练:将模型分布到多个实例,多块GPU上并行计算完成训练
- 基于人类反馈数据进行调优:采用了大量的基于人类反馈的数据进行优化,使得对话更加自然、流畅而具有逻辑性
由于OpenAI并未公布太多的ChatGPT的训练细节,所以,上述有一些模糊的估计数据。
值得注意的是,ChatGPT用到的核心技术其实并非原创,其核心模型结构Transformer来自于Google的研究成果。
这里只是列举了ChatGPT用到的技术,后面的内容我们将结合开源的代码示例,从原理上深入解构这些技术,敬请期待。
总结
自ChatGPT发布以来,很多人认为这是一个人类走向通用人工智能的突破,也有一些人认为它其实没什么本质的改进。有很多人对自己的职业发展产生了很深的焦虑感,也有很多人感觉触碰到了科幻世界中的未来,还有很多人觉得又是一个可以好好捞一把的机会。
也许每个人都有必要去了解一下机器学习技术的原理,这样才能形成对它的理性的认知。
ChatGPT的内容很多,我计划采用一个系列,多篇文章来分享学习我自己学习过程中的一些理解。本系列文章,我将站在一个普通开发人员的角度展开,希望对想了解ChatGPT技术原理的普通开发者们有帮助。
这是此系列的第二篇,ChatGPT使用的技术概览。
参考
- wikipedia词条罗纳德·艾尔默·费希尔:https://zh.wikipedia.org/zh-sg/羅納德·愛爾默·費雪
- 人工智能与神经网络发展研究:https://image.hanspub.org/Html/2-1540922_23773.htm
- OpenAI开发的ChatGPT资料(Training language models to follow instructions
with human feedback): https://arxiv.org/pdf/2203.02155.pdf - OpenAI开放的GPT-3资料(Language Models are Few-Shot Learners): https://arxiv.org/pdf/2005.14165.pdf
- OpenAI开放的GPT-2资料(Language Models are Unsupervised Multitask Learners): https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- OpenAI开放的GPT资料(Improving Language Understanding by Generative Pre-Training): https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf