数据流水线
在数据平台中进行数据开发时,数据任务流水线是常用于组织各个计算任务的方式。
比如,我们要想完成一个指标计算。第一个数据任务是将数据接入到数据平台,接着,需要一个任务将数据进行初步的数据清洗形成DWD中的数据,然后,下一个任务可能是计算初级汇总数据存入DWB,再然后,需要一个数据任务计算得到最终的指标结果,还有一些后续任务,比如宽表构建,导出到外部数据库中进行大屏展示等。
这一系列的任务需要按照先后关系一步步的完成,于是它们就构成了数据任务流水线。
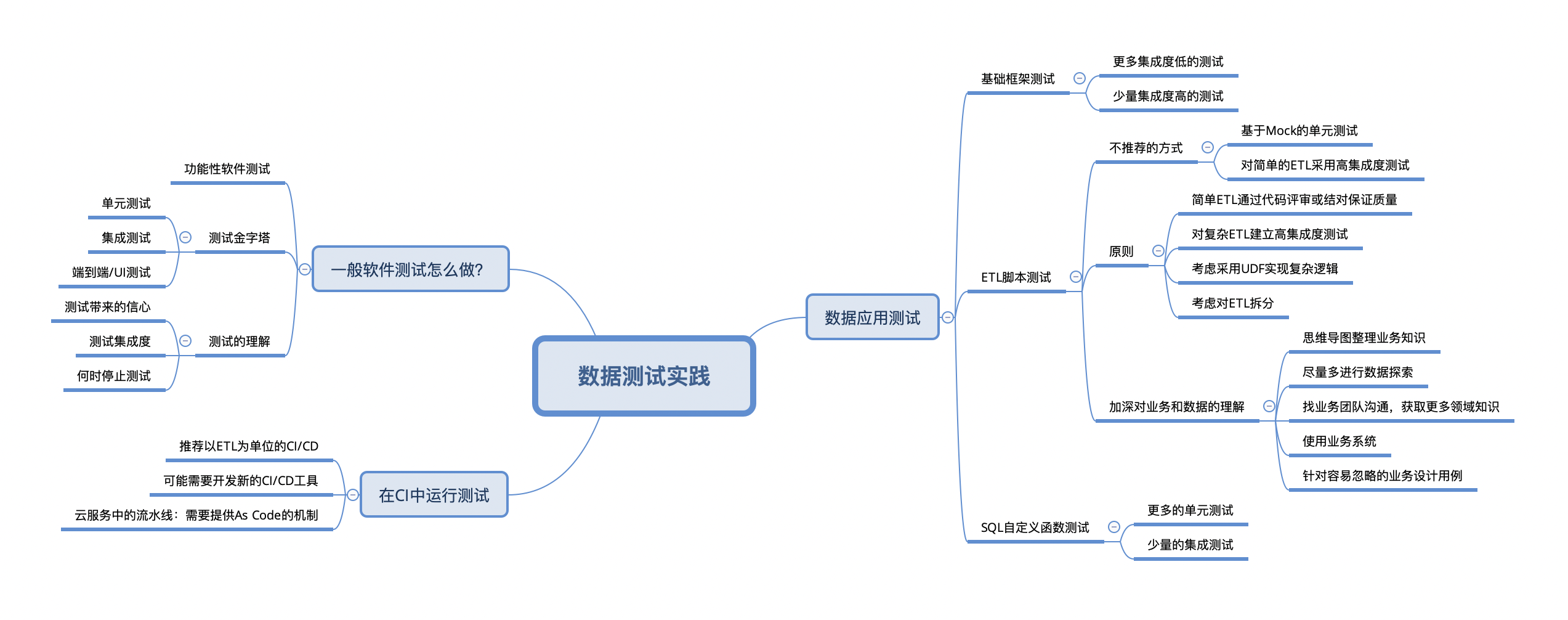
在前一篇文章《数据测试实践》中,我们探讨了数据应用如何做测试的问题。在数据测试中,ETL脚本的测试是个难题。一般而言,采用高集成度的测试方式(即运行ETL并比对结果,下文称集成测试)是更有效的做法。但是,这类测试的编写和维护却有较高的成本。如何降低ETL集成测试的成本呢?本文尝试从数据工具的角度分享一些我们的经验。
在前面的文章《数据应用开发语言和环境》中我们建议使用SQL来作为主要数据开发语言,并且,通常我们需要对标准的SQL进行增强,以便可以更好的支持复杂的数据开发。一些典型的需要新增的特性可以是变量、控制语句、模板等。
增强SQL固然是可以解决我们的数据开发问题,但是它也会给我们带来一些其他的不便。第一个烦恼可能就是,标准的SQL可以在很多数据工具中运行,比如Superset的SQL查询器、Hive的查询控制台等,而使用增强语法的SQL编写的代码则不行。由于我们将标准的SQL增强了,而SQL周边生态工具却无法感知这样的增强,这时各种不便就随之而来了。
在前文《数据仓库建模实践》中,我们提到了在确定DWD层的构建原则之后,可以通过开发数据建模工具来辅助实现。这样的工具应该设计成什么样子呢?
一个理想的建模工具应该具备良好的易用性和灵活性。
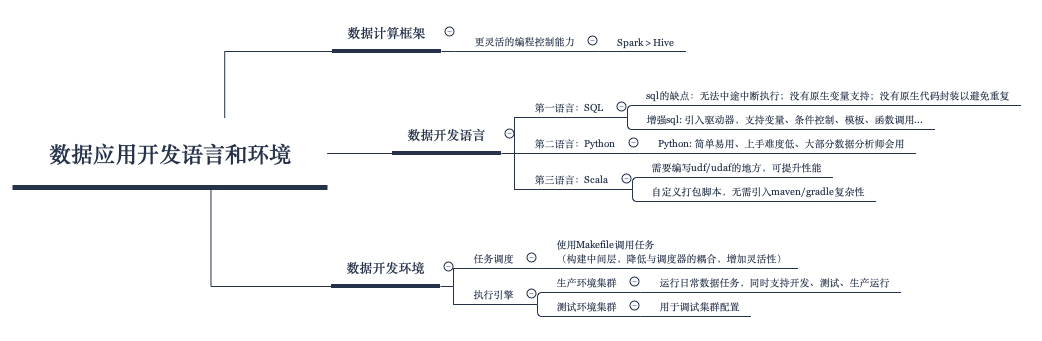
在数据进入到数据平台之后,我们就可以正式开始构建数据应用了。一个常见的数据应用是数据报表和数据指标的开发。如何开发这样的数据应用呢?首先要决定的就是使用什么样的开发语言及如何构建开发环境。本文将结合我们的实践经验一起聊一聊这个话题。
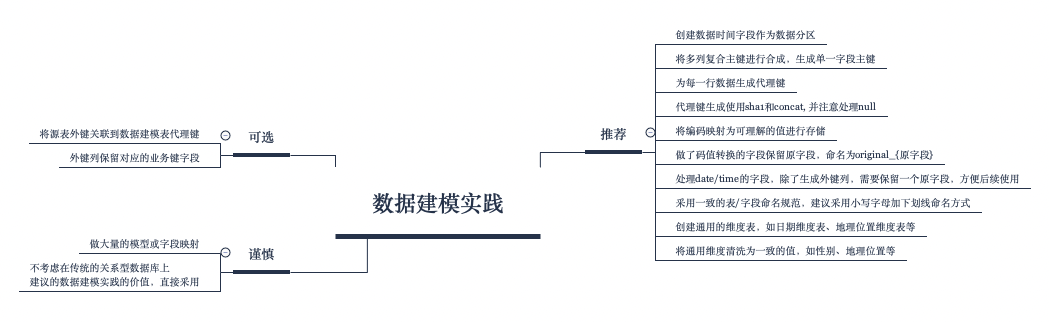
前面的文章中我们讲到了数据仓库。我们都知道,仓库的一般意义是指一个特别大的是用于存放各种物品的库房,所以,数据仓库常常可以给人一个很直观的理解,就是一个可以存放各种数据的大的存储。
在建设数据仓库时,我们常常要对数据进行分层,比如常见分层方式:ODS层->DWD层->DWB层->DM层->ADS层。
数据仓库建模通常是指DWD层的建模,因为DWD是数据仓库中使用最广泛的数据分层,我们需要尽可能保证这一层的易用性。DWD层的模型很大程度上影响了一个数据仓库项目甚至数据平台项目的成败。本文将针对DWD层数据建模分享一下我们在项目上的实践经验。
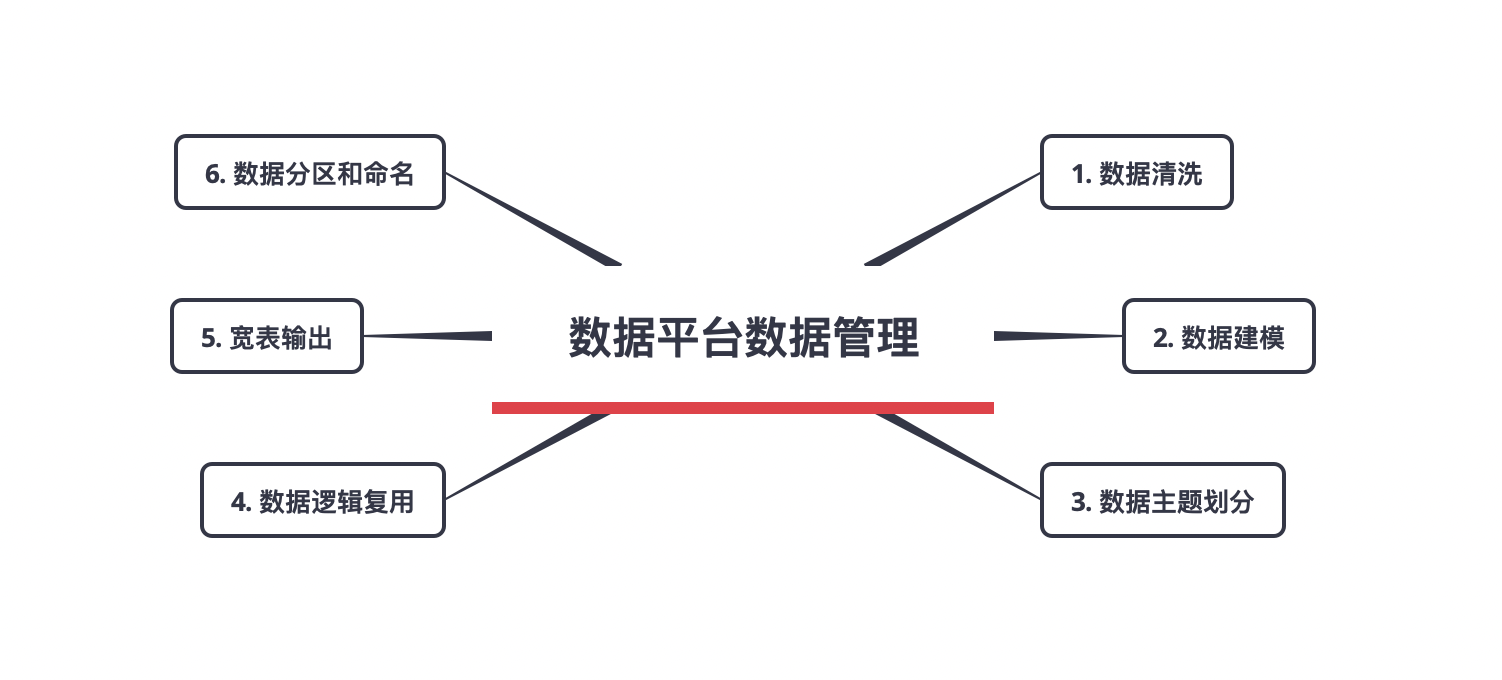
我们在前面的文章中讨论了如何将数据接入到数据平台。一般而言,接入到数据平台的数据会来自众多的业务系统,这样一来,我们就拥有了大量不同来源的数据。如何将这些数据有效的管理起来是一个很大的挑战。本文将尝试结合我们的项目实践经验做一些分享。
(数据仓库可以理解为数据平台中所有数据的一个集合,所以,数据平台中的数据管理也可以说是数据仓库中的数据管理。下文中数据平台和数据仓库会经常交替使用,其意义基本一致。)
快速、高质量、稳定的将数据从业务系统接入到数据平台是至关重要的一环。前面的文章中,我们分别提到了关系型数据库的数据接入和非关系型数据库的数据接入。除了来自技术上的挑战,数据接入还会遇到哪些其他挑战呢?
本文将尝试基于项目中的实践,给大家分享一下我们的思考。
一般而言,实施数据接入将可能碰到如下问题: