背景
在最近的一个项目上,我们再次碰到了需要处理长时任务的场景。事实上,随着要处理的业务问题越来越复杂,要集成的系统越来越多,在Web服务器端开发中,长时任务处理已经成为了一个普遍的问题。
以下场景均可看作长时任务场景:
- 在
GitHub提交了一个PR,要分别向上百个相关用户单独发送邮件 - 用户上传了一个文件,需要扫描这个文件是不是带病毒
- 用户想以
pdf格式下载某一个文档,需要先将文档转换为pdf格式
这些问题的一个共同特征是执行时间比较长,不能简单的用单线程的Web服务请求-响应模型来实现。
分析问题,识别难点
在应对这些需求场景时,一个关键的设计是需要用异步API模型进行建模。如下图所示:
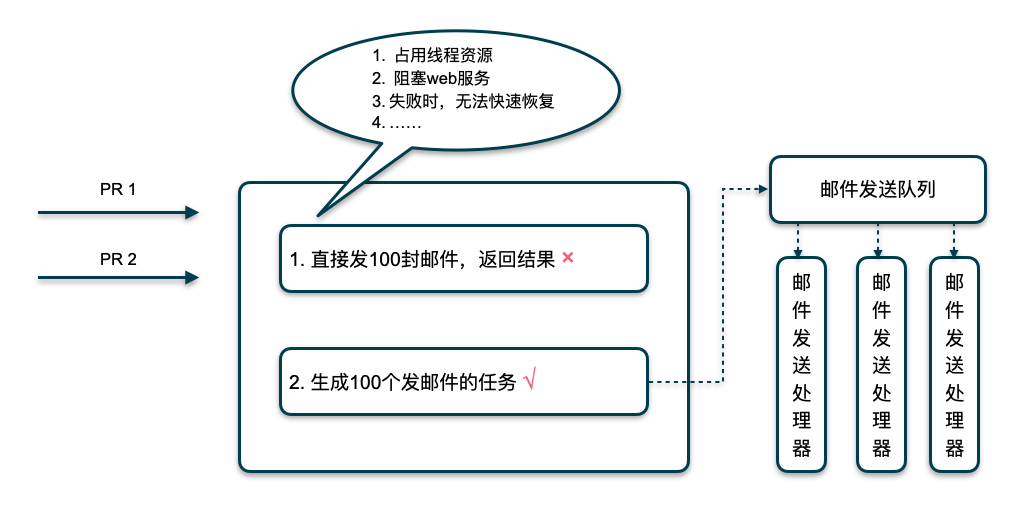
通常的做法如下:
- 采用事件模型(
Event Model),将长时任务包装为一个事件,放入事件队列 - 将待处理事件从事件队列中推送给事件消费者(或者消费者主动拉取新的事件)
- 事件消费者处理事件,并保存事件处理结果
- 关注事件结果的客户端查询事件处理状态,并提取事件处理结果
这看上去并不太难,但是,如果仔细思考一下事件的处理过程,会发现情况不对,这里面还存在以下一系列问题:
- 如何尽量避免多个事件消费者同时处理此事件,以便节省计算资源?
- 如果恰好同时有多个事件消费者在处理事件,会发生什么问题?
- 如果有多个相关事件正在被同时处理,如何处理资源竞争问题?
- 如何避免长时任务可能导致的长时数据库事务问题?

以下方案可用于应对上述问题:
- 在事件分派时,通过并发控制或者资源锁定机制,确保只将事件分派给某一个事件消费者
- 保证事件处理器的实现是幂等的,即:即便多次同时执行,其最终结果也是一致的
- 将任务处理过程拆分为多个短数据库事务过程,避免长期持有数据库锁引起性能问题
经过以上分析可以发现,异步任务模型是相对比较复杂的模型,程序实现及上线之后的问题分析、调试成本都比较高。在进行系统设计时,如果发现系统可以接受一定的延迟,并且并发也不高,就应尽量避免引入异步任务模型。
近年来,CQRS(命令查询分离)+Event Sourcing(事件溯源)设计模式越来越受到大家的关注。这一模式中,所有的写操作均采用异步事件的方式进行处理。准备采用这一模式时,一定要评估是否值得,因为异步任务将带来与上述类似的非预期复杂度。同时,如果事件使用不当还容易导致更复杂的情况。比如,如果在事件处理过程中生成了其他的事件,就可能产生一个由任务序列组成的有向图,甚至图中带环,从而使得处理过程的分析变得异常复杂。
TDD方法简介
TDD可以用于辅助我们进行复杂软件设计。是不是可以用TDD帮助我们实现这一复杂的异步任务处理系统呢?下面来做一下尝试。
在回答这个问题之前,我们先了解一下TDD的基本思想及其实施过程。
从驱动设计的角度来看,TDD的基本思想是,在还没有代码的时候,先站在使用代码的用户的角度来定义测试(编写测试就是在使用代码,所以可以自然的站在用户角度),由于使用了用户视角来定义系统组件及其接口,就可以使得到的组件和接口易于使用。
很多人无法在没有代码的时候编写测试,或者会由于IDE给出的一系列红色警告(由于组件还未定义)而感到不自然。
写不出测试
写不出测试一般是由于没有理解问题或不了解现有架构。可以采用Tasking(任务拆解)的方式来验证自己是否理解问题并了解架构。其基本思想是,对于一个问题,如果可以列出解决它所需的一系列清晰而合理的步骤,那就说明对问题和架构都较为清楚了。所以,在实施TDD时,一般需要先进行Tasking任务拆解。
红色警告让人感到不自然
对IDE给出的红色警告感到不自然的问题一般来自习惯。在编写测试代码时,需要调整视角,以完成设计和验证结果为重心。事实上,先写测试还会带来一个额外的好处,那就是在写完测试之后,可以让IDE帮助我们生成绝大多数代码,从而更快的完成代码编写。
用TDD辅助开发基于数据库的队列服务
下面看看如何用TDD来设计一个满足上述需求的异步任务处理系统。
经过前文的分析,我们大致了解了解决长时任务的关键方案。方案里面有一个核心的组件,那就是队列服务。
可以找到很多开源软件用来做队列服务,比如RabbitMQ,Apache ActiveMQ,Apache RocketMQ,Kafka,Redis等。甚至很多云端的SaaS服务也可以用来解决这个问题,比如AWS SQS,Azure Service Bus queues, GCP Pubsub等。
在很多项目的上下文中,可以预期并不会有太多的长时任务。此时,为了保持系统简单,避免引入其他的依赖,可以考虑基于数据库来实现这样的一个队列服务。下面分享一下如何用TDD指导我们开发一个基于数据库的长时任务系统。
第一个测试
采用TDD的思想,首先我们站在(长时任务)系统的用户(将来使用长时任务API的开发者)的角度思考如何使用长时任务的API完成程序功能。
假设有一个长时任务,它应该可以被添加到队列中。
队列应该启动一个后台线程,即消费者线程,从队列中取出任务开始执行。
由于任务在消费者线程中执行,消费者线程应该需要知道任务所对应的可执行代码是什么。
所以,在消费者线程开始运行之前,需要注册好任务对应的可执行代码。
基于上面的分析,使用Java进行编码,可写出对应的测试如下:
1 | class TaskQueueTest { |
到这里,一个基本的测试用例就定义好了。上述代码用到了JUnit及Mockito测试库的一些API。在编写测试的过程中,我们完成了基本的组件拆分及功能设计。值得注意的是,这里用到的类的名字、方法的名字、方法的参数等均是从用户的角度进行设计的。
因为我们直接写出了这样的测试代码,此时,IDE会显示很多红色警告,因为测试中用到的类和方法都还未被创建。如果使用Idea进行开发的话,可以将光标移动到红色警告处,按下Alt+Enter,Idea将提示创建类或变量,跟随IDE的指引,就可以很容易的完成这些代码的编写。
到这里我们就完成了第一个测试,并生成了对应的代码框架。整个系统设计的第一步已经初步完成。
引入新的设计,改进测试
由于我们希望基于数据库来实现任务队列,而数据库访问一般用Repository进行抽象。对应这里的设计,任务队列应该需要把数据读写的职责拆分出去。
考虑如何在测试中使用Repository,可以在之前的测试基础上增加Repository相关接口设计。有几处需要修改的地方:
- 测试开始时,应该构造一个模拟的
Repository对象。 - 当新任务加入队列时,任务队列应当调用
Repository的接口保存新任务。 - 当任务队列消费者开始运行时,它应当从任务队列取出新任务,而任务队列使用
Repository查询新的任务。 - 当任务被取出,将要运行时,其状态应当被修改为开始执行,并保存到数据库中,此时应当采用批量保存的方式。
- 在任务执行期间,其状态将有一系列变化:待运行、开始执行、执行中、执行成功/失败。在任务状态变化时,将调用
Repository更新数据库的状态。 - 在保存任务的时候,任务的参数需要以一种方式序列化为字符串才能在数据库中保存。可以使用常用的json序列化方式。
修改测试如下(完整代码见这里):
1 | class TaskQueueTest { |
上述测试中,我们模拟了TaskRepository对象,并基于这个模拟对象进行测试。通过模拟这个对象的接口,我们可以完成整个TaskRepository的API设计。
同样的,可以利用IDE辅助我们生成大量的模板代码,在实现时,只需要在不同的地方填入代码即可。
加入数据库事务支持,进一步改进测试
由于程序需要访问数据库进行数据存取,数据库事务控制是一个需要注意的问题。从性能上考虑,数据库事务应当较短,不适合将长时任务运行过程放入事务过程中。
数据库事务实现可以基于Spring框架提供的事务抽象,即TransactionTemplate接口。可以对以下可快速完成的过程进行事务控制:
- 取出新任务后,将任务标记为开始执行。使用排它锁进行事务控制,防止其他任务消费者取到同一个任务
- 任务开始执行时,将任务标记为正在执行状态,使用基于版本的乐观锁进行事务控制
- 任务执行完成之后,更新任务状态,使用基于版本的乐观锁进行事务控制
修改测试如下(完整代码见这里):
1 | class TaskQueueTest { |
实现现有的接口
由于目前只是通过IDE生成了一些代码框架,尚未提供实现,上述测试会失败。接下来的一步就是为现在的设计提供一个实现。
有了前面的分析,及测试的保障,实现起来应该不是什么难事。有兴趣的同学可以自己试着写一写代码。
一个参考实现见这里。
其他的考虑
为保证我们的长时任务实现具有较好的易用性,还可以考虑增加以下特性:
- 任务消费者异常退出时,任务应该被回收,以便新的任务消费者可以重新处理该任务。
- 任务消费者应当被周期性的唤醒,以便可以定时的从队列中取出新任务进行处理。
- 当有新任务加入时,任务消费者应该快速被唤醒,以便新任务可以及时得到处理。
- 如果执行任务时,任务处理器未被注册,则应该抛出异常,并将任务标记为失败。
- 如果任务执行失败,可以进行一定次数的重试。
- 可以实现
Restful API来完成添加任务、获取任务状态、查询任务列表、重启任务等功能。
这些特性都可以通过TDD的方式进行实现。
部分上述特性的详细实现过程及代码可以参考这里的提交记录。
值得注意的是,除了按照前文进行基本的TDD开发。在设计测试时,还需要考虑整体的测试策略。一般而言,测试应该可以按照集成度的从小到大构成一个金字塔的结构。即,大量集成度小的单元测试,中等数量集成度中等的测试,少量的集成度高的测试。在进行TDD时,需要考虑用哪种集成度的测试更好。
一般的策略是:
- 先写一个简单的高集成度测试,通过这个测试驱动编写面向用户的接口,同时也作为面向用户的功能验收。
- 再编写少量中等集成度的测试,通过这些测试驱动完成各个组件及其交互接口的设计,同时验证这些组件确实按照设计工作。
- 然后再以类级别或函数级别的测试为主,为类或函数的实现提供正确性保障。
在TDD的过程中,通常还会结合重构来进行局部代码优化。在上述实现中,也有一些可以参考的地方。比如,任务处理器最初命名为TaskRunnable,后来改为TaskHandler,以便更符合语义。
总结
编写有效的自动化测试是专业的开发人员的一项基本技能。然而,很多团队一味追求快速写完代码,忽略了锻炼开发人员的自动化测试技能,这对于开发人员的能力提升是不利的。
很多开发人员或者执着于追求底层技术,或者执着于为实现高并发高性能而引入的技巧,或者执着于某个复杂的算法,或者执着于理解某一框架的实现细节。他们认为这些才是自己技术能力的体现。这些确实可以体现一部分开发人员的能力,但是,别忘了,这些始终只是别人创造的成果。
真实的日常工作常常只是将一个个特定场景下的需求变成可工作的软件,并应对复杂的业务及将来的变更。针对这些特定的问题给出相对简单的合理的设计的能力,编写优雅且高质量的代码的能力,才是开发人员最重要的能力。自动化测试和TDD在这方面可以给开发人员很大的助力。
事实上,自动化测试和TDD不仅可以帮助完成高质量软件的开发,对前面提到的技术提升也很有帮助。因为,为了编写有效的测试,需要我们对所使用的框架或库有足够的了解,这就促使我们去了解它们的实现细节,同时,可运行的测试还可以用于确认我们的理解。
本文展示了在一个相对复杂的场景下,如何用TDD帮助我们开发拥有良好设计的代码。可以发现,TDD不仅为我们提供了测试护航,而且,面向用户的接口设计,领域语言的运用,都可以在TDD的加持下自然的落地。
最后,只看不练并不能带来能力的提升,要想熟练的掌握TDD还需要在日常工作中抓住每一个机会刻意练习。
相关文章: