有了数据开发测试工具及DWD模型,数据开发看起来可以顺利往前推进了。下一步是数据开发真正产生业务价值的过程,即指标计算。前面的基础建设其实都是为了指标计算能高效高质量的完成。本文将尝试分享一些关于指标计算的实践经验。
在前面的文章数据平台数据管理实践中,我们提到了基础数据层(也常被称为轻度汇总层)。这一层一般以DWB的缩写来表示,其全称是Data Warehouse Basis。DWB这样的数据分层是业界常见的数据仓库分层实践,对指标计算有很好的参考意义。
指标计算除了要处理指标逻辑之外,一个核心实践就是抽象和构建DWB数据层。本文将尝试分享一般的DWB构建过程,并从开发工具支持上提供一些思路来辅助解决数据应用中的复用问题。
数据应用中的复用
回顾前面文章中计算空调销量的例子,我们会考虑订单的状态,产品的范围等因素。在实现时,一般需要在第一步就根据这些条件做数据过滤,选出来需要做计算的数据。我们常常将这类数据过滤逻辑称作取数逻辑。
同样取数逻辑常常会在很多其他指标计算中使用。比如,当需要统计某一个用户产生了多少笔订单以确定高价值用户时,这里的指标取数逻辑就可能跟空调销量指标的取数逻辑相同。这提醒我们需要进行一定的抽象将这部分逻辑在项目中复用起来,以便可以有效的避免bug,并提高交付效率。
在一般的功能性软件开发中,我们可以通过代码复用来解决这个问题(比如抽象一个公共的模块)。在数据开发中,除了代码复用,还需要考虑计算复用,因为很多大数据量的计算是比较消耗资源的。
计算复用的一个典型示例还可以从“轻度汇总层”这个名字中引申得到,即某些高级汇总指标可以通过轻度汇总指标计算得到。比如计算空调销量,在业务上,除了希望能计算每日销量,还需要计算每月销量。在计算月销量时,可能可以根据日销量汇总得到。如果这样做,统计月销量可能只需要计算几十条数据就可以了,这可以非常快速的完成。
在数据应用开发中,我们需要有一些解决复用问题的方案。
构建DWB层
解决数据应用中的复用问题的一个常用思路就是抽象出DWB数据层。由于DWB的数据常常是由一个独立的数据任务产生,所以它同时解决了代码复用和计算复用的问题。
如何构建一个好的DBW数据层呢?
可以采用代码重构的思路。比如,在开发第一个指标的时候,我们将所有的代码放在了一起。开发第二个指标的时候,我们发现可以和第一个指标有一定的逻辑复用,于是我们抽象了一个DWB层的数据表,将公共的计算逻辑抽取出来用于构建这个表。构建这个表的代码一般还会形成一个独立的数据计算任务,在数据管道的另一个任务中执行。经过几轮重构之后,我们将得到一些比较稳定的公共层数据表,DWB数据层也就慢慢丰富起来了。
采用重构的思路构建DWB层数据表存在效率不高的问题。因为计算额外的数据表并不只是需要修改代码,我们还常常需要因此多次重跑数据。对于很多指标而言,都需要计算历史数据指标,这里的量级通常是很大的,在我们的实践过程中,重新跑一次全部历史数据可能需要一天到一周。相比修改代码,其实重新跑数据花费的时间更长。
更高效的做法可能是一开始就能有一个好的DWB表设计。这需要对业务和数据有足够的了解,同时有较多的数据开发经验。从我们的实践来看,这里的设计也有不少值得参考的经验。
从需要设计的数据表来看,一般的数据统计都会基于事实表展开,所以,我们常常可以对常用的事实表设计对应的DBW表。
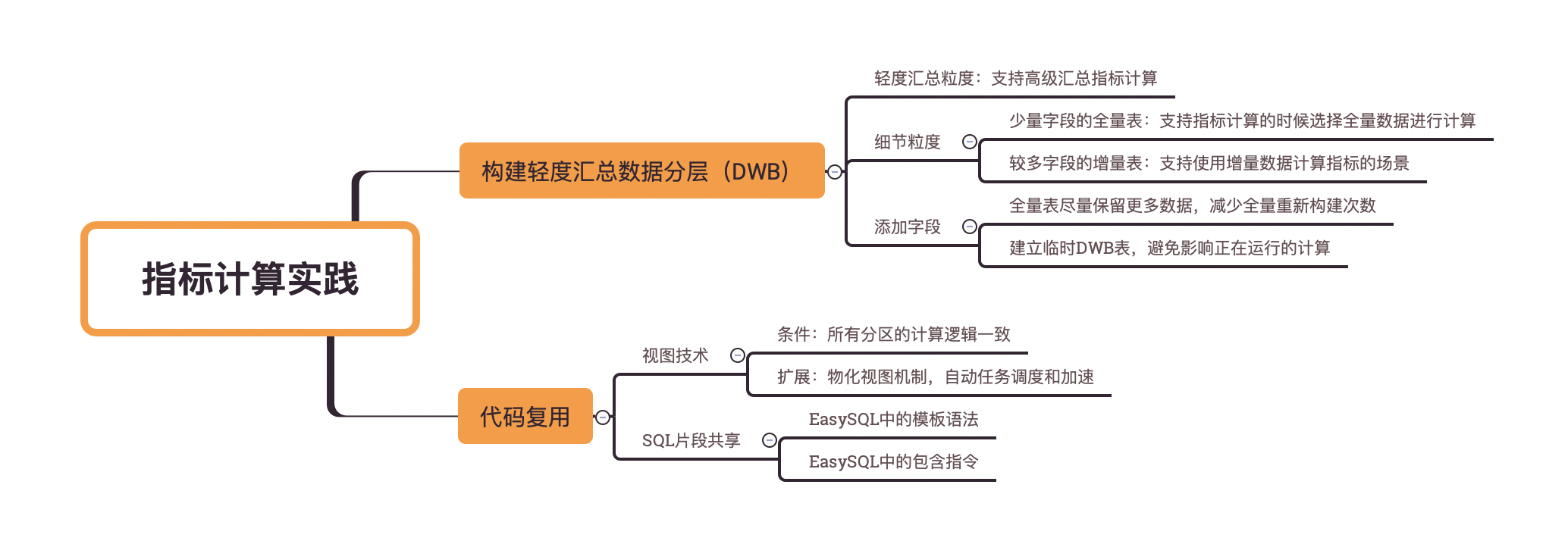
从特定表的设计来看,首先是要选择合理的粒度。一般而言,可以选择轻度汇总粒度,也可以选择细节粒度。为了能灵活的支持所有上层指标,选择细节粒度的情况可能是居多的。选好粒度之后,主要有两种设计思路可以参考。一是建立少量字段的全量表,二是建立较多字段的增量表。
轻度汇总粒度
如果选择了轻度汇总粒度来构建DWB层,我们会发现一些DWB直接就存储了最终需要的指标数据。比如每日销量可以作为一个轻度汇总指标,它可以支持高级汇总指标月销量的计算。
这看起来有点奇怪,不过我们也无需担心,只需要在DM输出层建立一个数据映射即可。这一映射可以通过构建一个简单的物理表来实现。如果不想管理数据任务,也不想产生数据复制,还可以考虑通过数据表视图来实现。
少量字段的全量表
接下来,我们来看一下如何建立少量字段的全量表。为了阐述这一设计思路,我们主要需要回答几个相关问题。
为什么需要全量表?答案很简单,因为很多统计需要提取所有数据进行计算。空调销量就是一个例子,从逻辑上看,其统计时间范围是全量数据。有人可能会觉得是不是可以基于每天的销量数据进行汇总。这不总是能得到正确的值,因为订单存在取消、退货等情况。一个正确的销量统计可能需要根据所有订单的最新状态进行计算。
为什么是少量字段呢?这里的设计方式是建立全量表,即每天的数据分区都是一份全量的数据。既然如此,如果大量的字段都需要每天复制存储,那将带来巨大的存储空间占用。
字段少到什么程度是合适的呢?这个问题并没有统一的答案。可以参考以下做法:
- 一般而言,我们需要提取所有的状态字段(如订单的状态,删除标记状态等),然后根据这些状态字段计算一些标记字段供上层使用。比如可以将完成状态且非内部奖励且非翻新产品订单标记为
is_new_valid_order,在计算销量的时候,可以简单的按这个标记字段进行数据过滤。 - 一些常用的关联维度放到这个全量表通常也是合适的。
- 某些数据量特别大的关联表的维度,比如用户的年龄、性别等,尤其可以考虑放到全量表中。由于数据量大(用户表通常可以到千万级别),表关联是很慢的,放在
DWB数据层来完成就可以避免上层多次进行数据关联,从而提高效率。 - 某些数据量特别小的关联表的维度,比如经销店的属性,可以考虑在全量
DWB表中仅保留关联经销店ID,然后在上层进行表关联获取相关维度。是否要应用这个建议可能还需要评估加入这些维度之后会带来多大的存储增量,由于数据都是压缩存储的,这里带来的额外存储可能没有想象的那么大。
- 某些数据量特别大的关联表的维度,比如用户的年龄、性别等,尤其可以考虑放到全量表中。由于数据量大(用户表通常可以到千万级别),表关联是很慢的,放在
较多字段的增量表
一些指标的计算无需使用全量数据,这样的指标计算就可以只关心每日增量数据了。可以根据每日增量数据构建DWB表。
对于这样的增量数据DWB表,其数据量通常不大,因此,我们常常可以在此完成大部分维度的统一关联。这样上层的指标计算将能更简单更快的完成。
除了可以在此类DWB表中尽可能多的存储关联维度,计算并存储上面提到的标记字段也是合理的。这样可以推进取数逻辑复用,并有效简化上层指标计算的代码。
增量的添加字段
DWB表的设计很难一蹴而就,因为指标需求往往不是一开始就确定的,而是随着业务的发展逐步完善的。因此,DWB表的设计需要具备一定的扩展性。这里的扩展性可以通过一定的方法来实现,比如:
- 在全量表中尽量保留所有的数据,避免出现由于数据不够用需要全部重新构建数据表的情况
- 在新加字段之后,
DWB的数据需要重跑,通常耗时很长。此时可以建立一个临时的DWB表,将数据输出到这个临时表中。一旦所有历史数据准备完毕,再一次性将原表归档(可以通过重命名实现)并将临时的DWB表重命名为原表名
采用上述这样增量的方式完善DWB表,将可以有效减少由设计修改带来的对生产正在运行的指标的影响。
代码复用
构建一个物理的DWB层有一定的副作用,主要是需要管理额外的数据计算任务,并且,由于额外的数据计算任务的出现,DWB层计算逻辑的变更可能需要引入大量的数据重新计算。此时,我们也可以考虑只在代码层面进行复用,不构建单独的物理数据分层。
在刚开始的时候,DWB的设计还不够稳定,经常需要修改,DWB层的变更会尤其频繁,在此时选择只在代码层面进行复用就是一个好的时机。
我们的指标计算代码一般都是通过SQL编写而成,如何实现SQL代码的复用呢?这可能需要新的技术,或从数据工具上做一些支持。
视图技术
一个可选的可直接替代物理DWB分层的技术是视图。特别是对于增量的DWB表,可以考虑用视图的方式来构建。
通过视图构建DWB表有一些前提条件,那就是所有分区的计算逻辑是一致的,也即每个分区的数据可以由DWD层的对应分区计算得来。比如活跃用户数指标,如果计算口径是最近三天有交互,其计算需要选择最近三天的数据,这就不适合用视图来解决问题了。
除了视图技术,还有一个新的选择,那就是物化视图。
Hive 3.0中引入了对Materialized view的支持,这就是物化视图了。顾名思义,物化视图就是物理化的视图,即提前计算好的视图,相当于有一个物理表。
在进行视图查询时,SQL引擎会将视图对应的SQL扩展到待执行的SQL中,所以实际的查询常常很复杂,速度也很慢。而物化视图就可以解决这个问题。
使用物化视图时,我们无需关心这个物理表的数据是什么时候跑出来的,也无需关心什么时候应该更新,Hive帮我们管理好了这一切。
由此看来,相比视图,物化视图可能是更好的选择。不过,Hive中的物化视图需要开启事务支持,这增加了一些限制。
SQL片段共享
除了可以用视图技术来实现代码的复用,另一个更直接的方式就是共享SQL代码片段。这与我们编写其他语言的代码时抽象一个公共模块的思路一样。
在数据应用开发语言和环境一文中,我们提到了一个新的SQL语法,即模板。一个简单的包含模板的ETL可以是:
1 | -- target=template.a |
模板可以支持在单个ETL文件中共享代码片段。但我们这里的问题是跨ETL共享代码。其实只需要对SQL处理器进行很少的修改就可以支持共享模板了。
简单来说,我们可以将共享模板定义到一个单独的文件里面,然后在运行时,先执行共享的模板,再执行模板ETL即可。
另一个思路是,继续增强SQL,增加新的语法,比如可以支持一个称为include指令的语法。include指令的工作方式类似c语言中的include指令,它可以将指令指定的文件内容扩展到当前位置。有了include指令,我们的ETL写起来可能是下面这样:
1 | -- shared_code.snippet.sql |
1 | -- etl.sql |
为支持这个新语法,我们需要在SQL处理器里面增加一个预处理的过程,在该预处理阶段完成文件内容扩展。
总结
指标计算过程中的一个重要问题是如何进行复用。本文尝试从DWB的构建及公共SQL片段提取两个方面分享了我们的一些实践经验。