数据流水线
在数据平台中进行数据开发时,数据任务流水线是常用于组织各个计算任务的方式。
比如,我们要想完成一个指标计算。第一个数据任务是将数据接入到数据平台,接着,需要一个任务将数据进行初步的数据清洗形成DWD中的数据,然后,下一个任务可能是计算初级汇总数据存入DWB,再然后,需要一个数据任务计算得到最终的指标结果,还有一些后续任务,比如宽表构建,导出到外部数据库中进行大屏展示等。
这一系列的任务需要按照先后关系一步步的完成,于是它们就构成了数据任务流水线。
实际项目中的流水线通常会非常复杂,因为我们有很多指标需要计算,它们各自会依赖不同的表。最终的数据流水线形态会是一系列有向无环图,这就是我们常说的DAG。
数据任务流水线看起来和CI/CD流水线有类似的特点。技术人员甚至会觉得可以用持续集成流水线来构建这样的数据任务流水线。事实上,用Jenkins或者GoCD也可以构建这样的流水线,但是由于它们主要被用作持续集成工具,实际使用下来会发现缺乏了很多数据流水线管理需要的功能。
流水线设计
那么,这样的数据流水线应该如何设计?需要有哪些管理功能呢?
回顾数据任务的各个步骤,可以发现需要设计以下这些数据流水线:
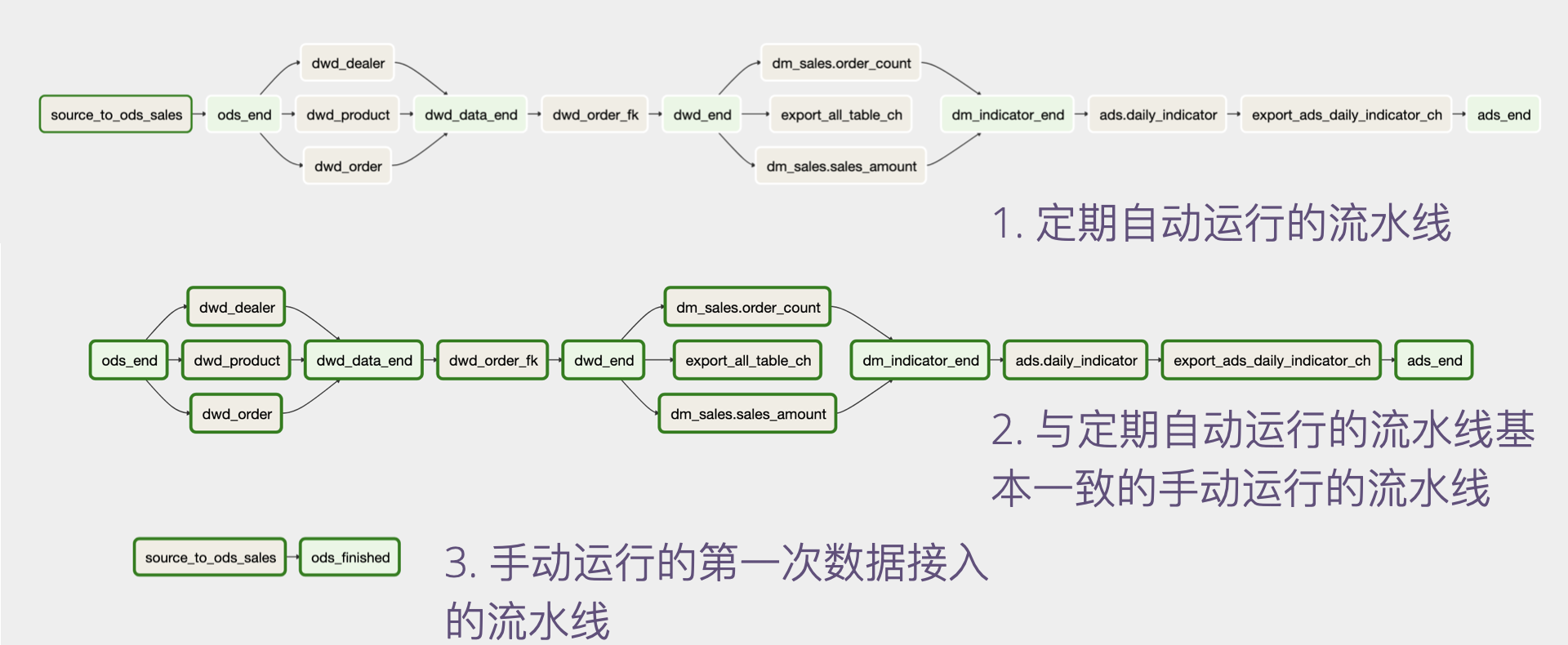
一、定期(如每天)自动触发的数据任务流水线,它将完成定期的数据接入,清洗,指标计算,宽表构建,宽表输出这一系列任务。这一流水线通常是端到端可输出指标结果的流水线。
二、首次全量数据接入任务流水线,用于第一次将全量数据接入到数据平台。它应该是手动触发的。
三、与定期自动运行的流水线相同的,但只能手动触发运行的一条流水线。这一流水线的引入是必要的,因为它可以很好的应对日常数据开发运维工作。
第一条流水线是比较好理解的。在实践中,一般我们会设计一个名为data_date(数据时间)的流水线参数,所有数据任务都需要计算这个参数指定的时间的数据。
第二条流水线也是必要的,因为第一次全量数据接入任务难以通过自动流水线来支持。如果强行通过参数来支持,将导致流水线的复杂度上升,同时也不便于团队理解。从单一职责原则来讲,也不建议用定期执行的流水线来支持需要手动执行的、运行次数很少的流水线。
第三条流水线的引入可能不太好理解。前面提到它是为了解决日常的数据开发运维工作,具体是指哪些呢?请看下面这些场景。
第一个场景是,当我们新开发了一个指标,除了需要计算指标上线之后的数据之外,还需要计算历史的数据的时候。此时,我们往往无法在自动触发运行的流水线中完成这样的任务,因为历史数据的时间跨度可能很长(比如一年),而自动运行的流水线一般只能计算某个固定时间点(如某一天)的数据,这将导致大量的历史任务需要调度运行,从而带来性能问题。
这里的性能问题可以简单分析一下。在执行分布式计算任务时,第一步是需要分配并启动计算资源。这一步常常比较耗时,如果使用流水线来调度,则每一个任务都需要重复这一过程,从而产生了大量的无必要的时间消耗。一个直接的优化方式是只启动一个任务,分配一次资源,将一系列的同类任务一次性执行完。不仅如此,如果多个时间点的数据计算可以通过分组聚合(group by + aggregation)来实现(比如,每日订单数量指标就可能可以通过分组聚合一次性计算一个长时间范围的数据),那将可以直接一次性计算一段时间的指标数据,这显然是性能更好的优化方式。不过,这样一来,就可能无法和自动运行的流水线共享同一套代码了。
通过一条独立的手动运行的流水线将很容易做到上述这些优化,所以,单独设计这样的流水线是值得的。
另一个类似的场景是在需要修改已有的指标的计算口径时。此时也常常需要重新计算一个很长时间段的数据任务。
除了上面的场景,还有一些其他的场景,比如某一天在ODS层执行了必要的数据修改,需要重跑某一些数据任务。
总之,设计一条与自动运行的流水线相同的手动运行的流水线好处多多。从我们的实践来看,是非常值得推荐的做法。
从上面的分析来看,这个手动运行的流水线还需要很好的支持只运行流水线中的部分任务。这一特性可以通过设计流水线参数来实现。比如,在我们的流水线中设计了两个参数,即include和exclude,分别表示需要包含的和需要排除的数据任务。
一个示例的数据任务流水线如下:
任务间依赖的实现
通过数据流水线可以较好的管理数据任务间的依赖,同一条流水线中的任务总是会按照流水线中的先后顺序运行。
在实践过程中,我们会发现还存在一类跨流水线的任务依赖。比如,一般而言,我们会为每一个业务系统设计一条数据流水线(如售前系统流水线、售后系统流水线),但某些指标的计算会同时依赖多个业务系统的数据(比如售前到售后的转化率就需要依赖售前系统和售后系统数据)。这类指标的计算任务就会产生跨流水线的任务依赖(对于售前到售后转化率指标,它将同时依赖售前系统和售后系统流水线中的DWD数据层构建任务)。
如何解决跨流水线的任务依赖呢?一些流水线工具为这种场景提供了支持,比如,Airflow提供了一个虚拟的ExternalTaskSensor任务,它将等待其它流水线中的某一个任务完成,然后才会完成。
依赖流水线工具完成依赖任务检查是一个简单可行的方案。但是在实践中,仅使用工具进行依赖管理还显得不太够。比如,处于某种维护目的,我们需要将某一个数据分区删除重建。手动删除该分区之后,在数据流水线中,该任务的后续任务不会失败,而是会继续运行,这就可能导致其计算的结果不对。
所以,我们更推荐的做法是,除了使用工具来管理任务依赖,最好还能在任务的ETL代码中先对依赖的数据执行严格的检查再执行计算。
使用我们前面提到的SQL增强语法,一个简单的依赖检查示例如下。
1 | -- 销量指标的计算依赖当天的`DWD`数据层中的订单表构建完成,强制检查对应的数据分区是否存在 |
上面的检查实际上是一个双保险,可以更进一步确认前置步骤是完成了的。
对于跨流水线的任务依赖,用这种方式有更好的效果。因为如果使用流水线工具来实现,则会导致流水线难以理解。试想,如果有两条以不同频率运行的流水线,我们能简单的推断出有跨流水线依赖的任务会什么时候运行吗?
但是,如果通过ETL代码检查来保证这种依赖关系,情况就会更简单了。代码里面明确的指定了ETL的输入依赖。
我们甚至可以摈弃掉复杂的跨流水线依赖配置,仅通过ETL代码来保证依赖关系。此时,我们可能需要配置好该检查的重试次数及超时时间(根据数据任务启动及运行时间进行设置)。
流水线管理及工具选择
前面分析了数据任务流水线的设计,可以看到,这样的设计对流水线工具提出了一些要求。持续集成工具如Jenkins或GoCD在这一领域提供的功能比较有限,在工具选择上,我们还需要更为专业的特定工具。
由于这类流水线工具的核心的功能是辅助进行ETL任务调度,我们也常常将其称作调度系统。常用的此类调度系统有Oozie Airflow Azkaban等。
这类调度系统通常提供了非常丰富的任务调度功能,其中有些是必要的,而另一些在数据流水线管理中则使用较少。下面,我们从任务调度需求出发,来分析一下一些基本的功能需求。
流水线创建和编辑
最基本的调度系统功能是需要支持以上流水线设计。如果流水线的配置人员更习惯使用界面化的配置,那应该提供一套基于web的配置界面,可以让用户可视化的编辑流水线,实现如添加节点,修改节点,配置节点任务,配置节点参数的功能。
可视化流水线配置可以很好的提升易用性,但其功能实现会较为复杂,且对于流水线的变更不易进行版本控制。
另一类流水线配置工具仅提供了基于配置文件的配置方式。比如Oozie支持使用XML进行配置,Airflow支持使用Python代码进行配置。它们虽然没有提供可视化的流水线编辑,但是大都提供了可视化的查看。这类工具对于习惯编写代码的开发人员其实更为友好,因为流水线配置文件代码可以很好的用版本管理工具管理起来,且可以通过代码实现配置的复用。
任务调度
除了流水线的创建和编辑,流水线的任务调度管理是另一个核心的功能。需要支持哪些调度管理功能呢?一般而言,下列功能是需要具备的:
- 周期性流水线调度运行。
- 手动触发任务重新运行。在一些任务运行失败时,常常需要手动恢复运行,此时,常常还需要支持同时运行该任务的所有下级任务。
- 查看任务运行日志。任务日志是分析任务执行失败、时间过长等原因的重要手段。
- 控制并发任务数量。由于计算资源限制,常常需要控制可以并行运行的任务数量。还有一些任务,虽然任务间的执行顺序没有要求,但是多个任务不能并行运行,这也可以通过控制并发任务数量来实现。
- 周期调度的任务可以依赖前一个调度时点的任务。很多复合指标的计算会依赖上一个时点的数据,如今日销量比昨日的增量,这就需要调度系统可以支持设置这样的依赖。
- 支持跨
DAG的任务依赖。在一些场景中,我们需要实现跨流水线的集成指标计算,此时就可能需要支持跨DAG的任务依赖。
Airflow和Azkaban可以较好的支持上述功能。它们实际上提供了一个任务状态的抽象,任务可以处于未开始运行、调度中、运行中、重试中、成功、失败等状态。对于上面提到的功能,比如按照依赖关系重新运行一组任务,可以通过将这组任务的状态重置到某一个状态来实现。
一个完善的任务调度系统的实现是很复杂的,如果有兴趣深入了解,大家可以参考对应的文档,或者阅读对应的开源代码。
总结
本文结合我们的项目实践,分析了如何在数据平台中设计数据流水线。一般情况下,三条流水线的设计可以较好的支持大部分的数据应用场景。
同时,本文分析了如何使用调度系统来支持流水线的实现,提到了一些重要的流水线调度功能。一个完善的数据平台最好能提供一站式的功能,而非使用各类设计风格各异的开源工具组合。我们在平台建设阶段虽然可以更多的使用这些工具,但是最好能划清任务调度系统在数据平台中的功能边界,即,有限制的使用这些工具。这可以为后续可能的自研调度系统铺平道路。