在前文《数据仓库建模实践》中,我们提到了在确定DWD层的构建原则之后,可以通过开发数据建模工具来辅助实现。这样的工具应该设计成什么样子呢?
建模工具的基本方案
建模工具的特点
一个理想的建模工具应该具备良好的易用性和灵活性。
易用性可以体现在:
- 支持数据建模人员方便的查看,快速的编辑
- 有错误提示
- 有版本控制
灵活性是指:
- 可以很容易的自定义数据转换逻辑而无需修改工具代码
- 支持灵活的任务参数定义,以便适应不同量级的数据
- 一旦建模人员希望引入新的建模规则,可以很容易的修改这个工具进行支持
建模工具交互界面
常见的具备良好易用性的工具是一套完善的拥有良好交互体验的Web系统,用户打开浏览器即可使用。但是这样的系统构建成本通常较高,而且一旦有新的建模规则或特性想要支持,也要花费更多的时间去修改系统。
有没有更简单轻量的工具呢?
做数据分析最常用的工具当属Excel电子表格了。电子表格有着非常强的灵活性,可以支持大部分数据分析场景。同时,团队成员通常也都具备熟练的使用电子表格的能力。基于此,我们可以考虑使用Excel作为用户交互界面。
我们可以设计一套电子表格的模板,然后,建模人员通过填表的方式进行模型配置,接着,建模工具通过读取模型配置来运行数据建模任务。
使用电子表格作为交互界面可以大大降低建模工具开发成本,使得我们可以将主要精力放在建模本身这件更有业务价值的事情上。虽然舍弃了一定的易用性,但是考虑到开发成本的降低及灵活性的提升,这个选择应该是比较合理的。
很多电子表格还支持协同编辑,此时可以让相关团队成员一起协作完成DWD模型的配置。
建模工具实现思路
有了电子表格中定义的模型配置,建模工具的核心功能就变成:
- 读取模型配置;
- 运行数据建模任务。
分析一下如何实现这两个功能。读取模型配置在实现上没什么问题,运行数据建模任务这个步骤还显得不够清晰。任务是以什么形式在什么环境里面运行呢?
回顾前面的文章《数据应用开发语言和环境》,经过分析,我们建议使用sql来作为主要数据开发语言,使用Spark作为任务执行引擎。那么这里的任务是不是可以以sql代码的形式体现,然后通过Spark来执行呢?
当然是可以的!前文中,我们还提到了一个可执行增强sql语法的sql驱动器。在这里,事实上,我们可以通过建模工具将模型配置进行转换,生成一个可执行的sql文件,然后通过sql驱动器在Spark中执行。
生成中间sql文件的方式带来了另一个好处,我们可以有更好的版本管理了。电子表格的版本是不容易维护的,但生成的sql是纯文本的,可以很容易实现版本管理。
建模工具设计与实现
有了前面的分析及基本工作流程设计,我们来看一下如何设计实现这一工具。
表格模板设计
首先来看表格模板的设计,下图展示了一个设计好的电子表格模板:
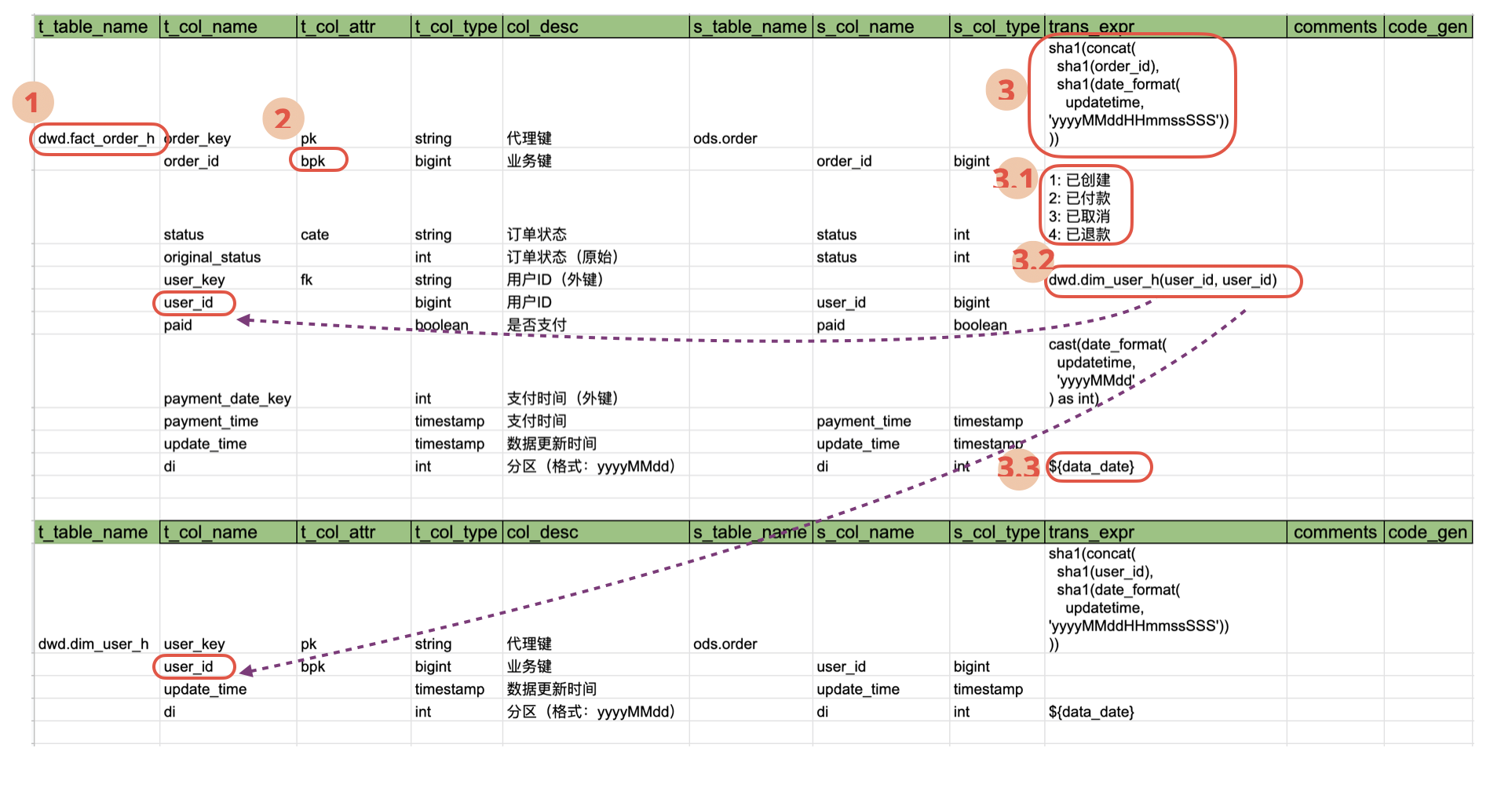
上述表格记录了订单事实表fact_order_h和用户表dim_user_h的模型配置,包括了多个列,其中:
- t_table_name: 目标表名,一般需要带上数据库名,只需要首行数据有值(参考上图示例①)
- t_col_name: 目标表字段名
- t_col_attr: 目标表字段属性,比如主键
pk,外键fk,分类字段cate等(参考上图示例②) - t_col_type: 目标表字段类型
- col_desc: 字段描述
- s_table_name: 源表名,一般需要带上数据库名,只需要首行数据有值
- s_col_name: 源表字段名
- s_col_type: 源表字段类型
- trans_expr: 转换规则
sql表达式,这里的表达式可以支持任意的合法转换,比如函数调用,变量引用,码值映射,外键转换等(参考上图示例③) - comments: 任意的关于这一个转换的注释
- code_gen: 自定义代码
扩展性分析
我们对每一个字段设计了一个属性t_col_attr,用于对特殊字段进行标记。建模工具可以识别这个标记,然后根据标记的不同生成不同的代码。目前我们只关注代理键、自然键、分类字段,以后可以根据情况增加其他需要进行特殊处理的字段类型标记。
转换表达式trans_expr是一个非常通用的设计,利用这个表达式,可以给DWD的表添加任意可以通过源表计算得出的字段。这里的表达式可以根据不同的字段标记使用不同的语法,比如:
- 在示例图
3中,通过定义sql表达式实现主键的生成 - 在示例图中
3.1中,对应的目标字段是分类字段,则trans_expr的值为分类码值映射 - 在示例图中
3.2中,对应的目标字段是外键字段,则trans_expr的值为外键信息,包括对应的表和表间关联字段 - 在示例图中
3.3中,表达式为普通sql表达式,其中可以引用变量,因为最后生成的sql将会通过支持增强sql语法的驱动器来执行
code_gen列中可以定义任意代码,建模工具在生成sql代码时,可以根据代码插入点标记将自定义代码插入到生成的sql中。比如,如果在处理第一个分区(全量分区)时,为了加速整个计算过程,可以通过repartition提升并行度,此时code_gen的值可以是:
1 | after_read_source: -- target=func.repartition(source_table, 100) |
生成的代码会在具有after_read_source标记的地方插入自定义代码。
有了原表字段类型s_col_type和目标表字段类型t_col_type的设计,建模工具可以判断两个类型是否相同,如不同,则可以生成一条cast(xx as xx)的语句自动将类型转换为t_col_type指定的类型。
col_desc的设计可以鼓励建模人员弄清楚每一个字段的确切含义,然后将数据的相关背景知识记录下来。在这里,col_desc还可以充当元数据的作用。有了col_desc,我们可以根据此生成表的字段注释。
建模原则支持分析
有了上面的设计,我们来看一下之前定义的建模原则如何在这个设计下进行实现。
- 代理键生成:可以使用
trans_expr实现 - 外键列保留对应的业务键字段:可以通过添加列来实现
- 做了码值转换的字段保留原字段,命名为
original_{原字段}:通过t_col_attr及trans_expr来实现 - 处理
date/time的字段,生成外键列:可以使用trans_expr实现
可以看到,电子表格模板的设计具有非常大的灵活性,可以很好的支持前文定义的建模原则。
实现
有了上面的分析和设计,现在要实现这样的一个建模工具就不是难事了。回顾上述设计可以发现,这个设计其实是站在使用者的角度定义了建模工具所应该具备的功能,这正是TDD的基本思想,也就是说,这个设计其实是为建模工具定义的一个测试用例。
在实现时,按照DDD的思想,可以将电子表格中每一行定义为一个领域对象,可以称作TransitionDefinition。使用Python读取Excel电子表格,然后将表格的每一行转化为一个领域对象。代码的生成可以基于Jinja模板引擎来实现。有了领域对象,我们只需要编写Jinja模板,然后将领域对象渲染为最终的sql即可。
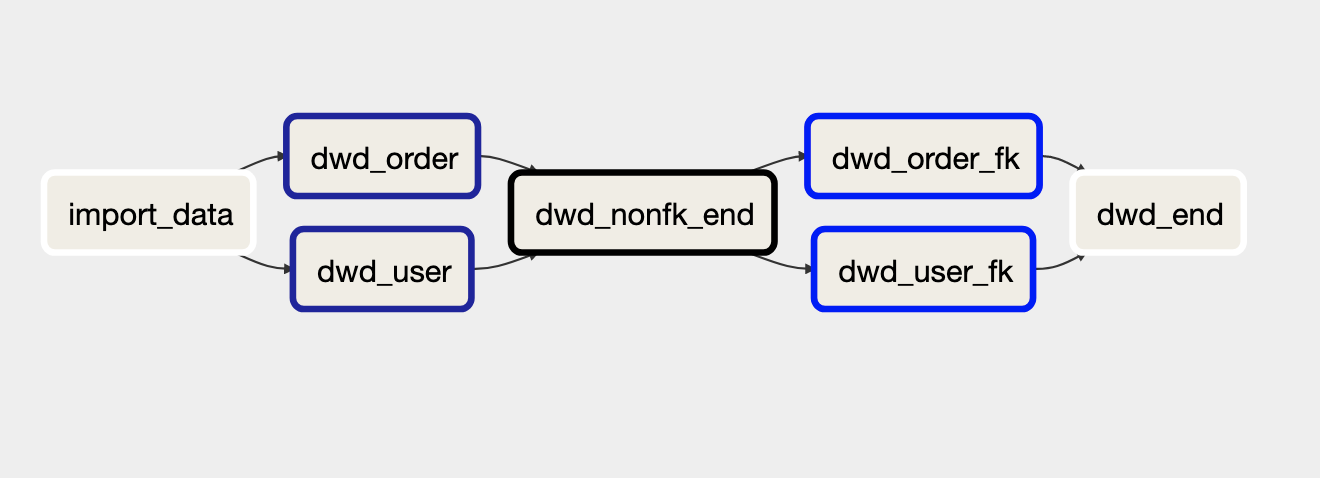
在实现时需要注意表间依赖问题。比如,上述示例中的订单表和用户表,由于订单表有一个外键指向用户表,我们需要首先构建用户表,再构建订单表。
这个问题比看起来的还要严重,因为可能产生循环依赖。如何解决呢?其实我们可以分两步完成构建过程,第一步处理非外键字段,第二步处理所有外键字段。由于外键实际上只依赖所引用的表的主键字段(业务键和代理键),只要这些字段有值就可以了。
还需要注意一个问题,那就是外键构建的任务可能无法并行完成,因为该任务会更新数据表(也可以考虑存储为不同的表,就没有任务并行问题了,不过此时会产生一份拷贝,从而牺牲一定的存储空间)。大多数调度器都提供了控制任务并行度的方法,比如Airflow的Pool机制。
将构建过程分为两步完成这一设计不仅很好的解决了表间依赖关系问题,还让最后的数据流水线更干净,如下图示例:
一个可运行的建模工具的实现应该不难,就不赘述了,可以作为大家的一个小练习。如果有兴趣,大家可以尝试进行实现。
总结
本文分享了一个数据仓库建模工具的设计和实现的例子。讨论了建模工具的方案设计,技术选型,交互界面(电子表格模板)设计,扩展性设计等话题。
DWD建模工具的引入,可以帮我们更高效的将DWD层构建好。由于这一层是其他数据应用构建时的最基础的数据来源,如果我们不能快速的完成,则将直接影响上层数据应用的开发。有了建模工具的支持,这一问题就不再是问题了。
在我们的实践中,得益于DWD建模原则的建立和建模工具的支持,我们将原来需要数周的建模时间缩短到了一周以内,大大提高了团队的效率。
在帮助我们的客户构建了多个数据相关应用之后,我们发现,数据平台构建过程中有很多工具可以复用,是值得抽象并沉淀下来的。在后续的文章中,我还将分享更多类似的数据工具。