在一个大型企业中做数据工作,难免要跟各种不同种类的数据库打交道。Oracle,凭借其优异的性能,曾经是很多大型企业标配商业数据库,自然也是我们要重点应对的一种数据库。
Oracle的数据导入导出是一项基本的技能,但是对于懂数据库却不熟悉Oracle的同学可能会有一定的障碍。正好在最近的一个项目中碰到了这样一个任务,于是研究了一下Oracle的数据导入导出,在这里跟大家分享一下。
(本文以下内容假设大家熟悉Mysql PostgreSQL等常见的其他数据库,但是不了解Oracle)
Oracle的一些基本内容
表空间TableSpace
Oracle被设计用于管理大量的数据,当一些数据库的数据量太大,以至于一块磁盘存不下的时候该怎么办呢?
Oracle设计了表空间来应对这个问题,一个数据库可以包含多个表空间,一个表空间可以对应多个数据文件,而一张数据库表可以属于某一个表空间。这样一来,我们可以在不同的磁盘上面创建表空间,从而可以方便的用多块磁盘来存放数据了。这几个概念可以图示如下:
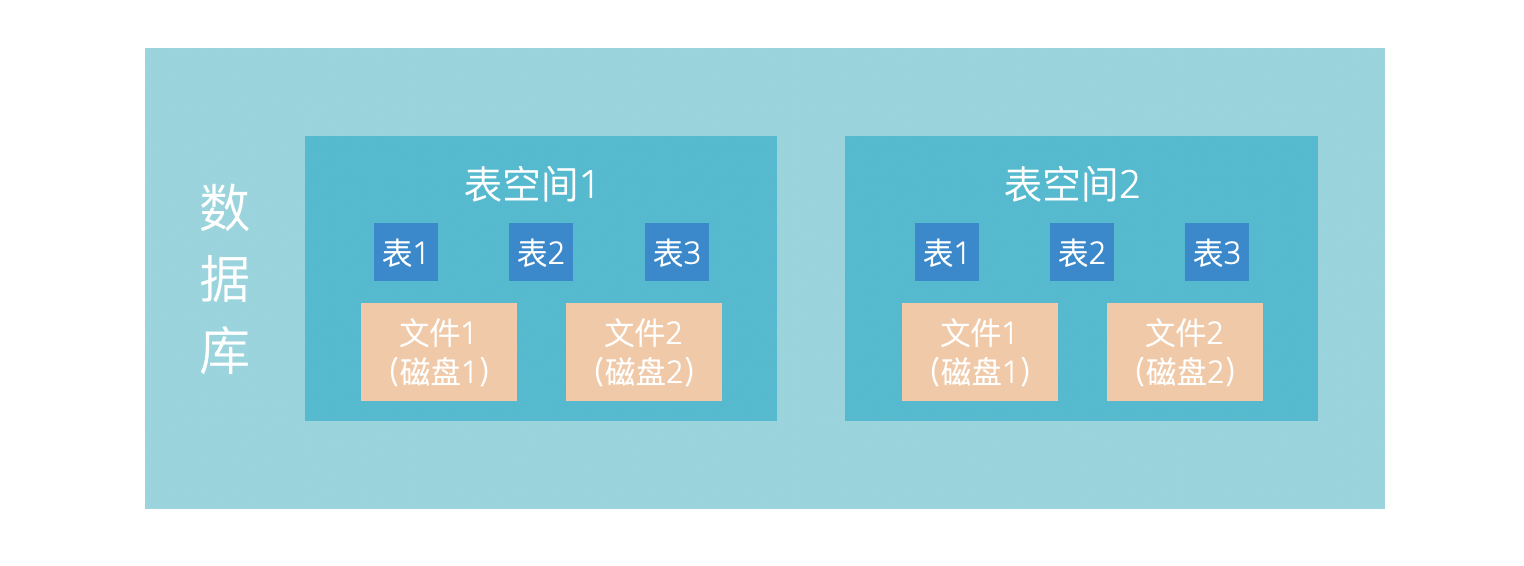
当然,表空间的意义远不止于解决多磁盘的问题,表空间其实是Oracle中的非常开创性的设计,它还可以应用于解决下面这些问题:
- 控制用户所能占用的空间配额
- 控制数据库所占用的磁盘空间
- 提高数据读写性能
- 提高数据安全性
对于一个大型数据库的数据导入导出工作,首先要做的一件事就是根据数据量大小来合理的规划表空间。
用户(User)与模式(Schema)
Oracle中的用户概念与其他数据库一致,都是用来连接数据库进行操作的。而Schema也与其他数据库中的schema概念一样,是一个数据表及其他对象的集合,用于进行统一管理。
但是Oracle中有一些特别的地方。在Oracle中,我们无法直接创建一个schema。当我们创建user的时候,会创建一个与此user同名的schema。这一点与其他数据库很不一样,需要注意。
虽然如此,通过授权还是可以实现一个用户访问另一个用户的schema。
数据导入导出工具
参考官方的文档可知,如果是从oracle到oracle进行数据导入导出,我们可以使用Data Pump Export/Import工具,也可以使用Export and Import Utilities工具进行数据导入导出。
Data Pump工具对应的命令行工具是expdp/impdp,其优势是速度快,但是使用上略显复杂(请参考后续实操部分)。
Export and Import Utilities工具对应的命令行工具是exp/imp,速度比Data Pump慢,官方更推荐使用Data Pump工具,但是这组工具使用上却更为简单。
如果是将Oracle数据同步到其他数据库或者基于hadoop的数据湖,则可以考虑使用数据平台常用的数据迁移工具sqoop,或者编写spark程序做数据导入导出。
字符集
Oracle支持多种字符集,这样一来,在数据导入导出的时候就需要关注字符集的转换,否则将可能出现乱码问题。
好在Oracle数据库足够聪明,内置了完善的字符集支持,可以自动完成大部分的字符集转换工作,尽量做到用户无感知。
在Oracle对Oracle的数据导入导出的过程中,将涉及到四处字符集:
- 源数据库字符集
- Export过程中用户会话字符集(通过NLS_LANG环境变量设定)
- Import过程中用户会话字符集(通过NLS_LANG环境变量设定)
- 目标数据库字符集
这四处字符集分别对应到数据导入导出的各个步骤,在执行某一个特定步骤时,expdp/impdp或exp/imp工具都可以自动的进行字符集转换。但是由于字符集情况比较复杂,事实上这类自动转换也不能完全处理所有情况。
比如,从GBK的数据库导入UTF8的数据库,导出的文件中的建表语句为..., some_column VARCHAR(100), ...时,导入过程可能发生错误数据长度过长(Value too long)的错误。此时需要手动修改建表语句,将上述字段改为..., some_column VARCHAR(100 CHAR), ...,以便以宽字节的方式来定义列长度。
实操练习
下面,为了打通整个数据导入导出流程,我们来完成一个数据导入导出的小练习。
我们将完成以下的任务:
- 构建一个oracle环境
- 生成数据并测试数据导入导出
- 比较
expdp/impdp和exp/imp工具的性能 - 用sqoop连接oracle数据库进行数据同步
- 用spark连接oracle数据库进行数据同步
构建oracle环境
oracle虽然是商业数据库,但是甲骨文公司为了降低其学习成本,发布了多个版本,其中的Express版本可以免费用于进行学习。虽然Express版本限制了数据库能使用的核数及数据文件的大小,但是用于完成我们的练习足够了。
如何构建一个oracle环境呢?当然最好使用docker了。恰好Oracle官方开源了对应的dockerfile,我们可以用它来快速构建一个镜像。
下面我们使用11g版本的oracle来完成此练习。
制作镜像
参考下面的命令可以完成镜像制作,并启动一个测试的oracle数据库。
1 | mkdir test |
在启动容器时,系统将生成一个随机,通过查看容器运行日志可以找到此密码。
运行docker logs test-oracle可以看到我们的密码是system/xxx
连接数据库进行操作
在命令行中连接oracle需要使用sqlplus工具,这个工具在容器中已经安装好了。如果想通过其他的主机连接oracle实例,sqlplus也提供了一个纯客户端版本。关于sqlplus的更多信息可以参考官方文档。
下面的命令可以连接到oracle并执行命令:
1 | # 激活默认生成的[HR用户](https://docs.oracle.com/cd/B13789_01/server.101/b10771/scripts003.htm) |
生成数据并测试数据导入导出
下面我们将生成一些测试数据,并测试数据导入导出。
为了简单,我们就用刚刚生成的hr.test表。并创建一个hrdev用户用于数据导入。
创建hrdev用户并配置权限
使用下面的命令可以完成此操作。
1 | sqlplus system/xxx@localhost |
创建目录并配置权限
通过expdp -help查看expdp的使用帮助可以看到,我们需要指定一个DIRECTORY才能进行数据导出。DIRECTORY在Oracle中是一个特殊的对象,是指映射到磁盘文件中的某个目录。用户还需要具有某个DIRECTORY对象的权限才能进行数据导入导出,因此还要完成相应的授权。
使用exp/imp工具则无需创建DIRECTORY对象,也无需相应的授权,故要简单不少。
通过以下命令可以创建一个目录并配置好权限。
1 | mkdir /tmp/test |
使用expdp/impdp进行数据迁移并验证迁移结果
1 | # 用expdp导出数据(仅test表) |
通过读取数据表hrdev.test的数据可以查看数据导入是否成功。
1 | sqlplus hrdev/hrdev@localhost |
使用exp/imp进行数据迁移并验证迁移结果
删除之前的hrdev.test表,然后我们来尝试使用exp/imp工具做数据迁移。
1 | # 用exp导出数据 |
使用上述类似的命令可以验证数据是否导入成功。
1 | sqlplus hrdev/hrdev@localhost |
到这里我们就完成了expdp/impdp和exp/imp工具的基本导入导出使用。
比较expdp/impdp和exp/imp工具的性能
expdp/impdp具有更好的性能,但是使用却颇为麻烦,其性能究竟比exp/imp工具好上多少呢?我们可以做一个小测试。
生成测试数据
下面的命令可以生成一个较大的测试数据表。
1 | sqlplus system/06d94313bc6a23ca@localhost |
测试性能
运行下面的命令可以完成一个简单的性能测试。
1 | time exp hrdev/hrdev file=test.dmp compress=y feedback=1000000 tables=test1 # 耗时1m30s |
在我的测试环境中进行测试,将相应的任务耗时标记在了上述脚本中。可以看到expdp/impdp相比exp/imp工具确实可以带来约几倍到几十倍的性能提升。所以在数据量很大exp/imp工具太慢时,还是可以考虑使用expdp/impdp工具的。
另外expdp/impdp还支持PARALLEL参数,以便进行并行导入导出,由于Express版本不支持PARALLEL,所以在我们的测试环境中并不能完成此测试。理论上expdp/impdp应该会比上述结果更快。
用sqoop连接oracle数据库进行数据同步
使用sqoop将数据导入到hive可以通过一下命令来实现:
1 | sqoop import --table TEST --connect jdbc:oracle:thin:@xxx.xxx.xxx.xxx:21521:XE --username hrdev --password hrdev \ |
在使用上述命令之前,需要注意:
- 将连接oracle的jar包下载到sqoop的库目录中(我使用的hdp数据平台,此目录为
/usr/hdp/current/sqoop-server/lib/ojdbc6.jar) - 如果此命令卡住无反应,可能是sqoop运行过程中在等待用户输入密码,参考这里,添加
beeline-hs2-connection.xml文件可以解决
使用sqoop除了可以进行数据迁移,还可以进行方便的执行一些sql命令,比如创建表、查询数据量大小都可以实现。它就是sqoop eval了,通过查询它的帮助文档可以了解更多。
由于sqlplus命令行工具最多只能输入2499个字符,所以一些创建表的语句会无法执行。此时,使用sqoop eval就可以执行这些语句。
用spark连接oracle数据库进行数据同步
spark是大数据开发中常用的工具,其生态相对成熟,可以很容易的实现类似sqoop的并行数据迁移。
使用spark进行oracle数据读取,只需要下面这几行代码:
1 | spark: SparkSession = SparkSession.builder.enableHiveSupport().appName("data-migration").getOrCreate() |
用spark进行数据迁移时需要注意,当我们指定了partition相关参数时,数据迁移并不一定可以得到加速。
在我们的测试过程中发现,当导入一个超过100G的数据表且指定了分区参数时,任务执行过程中出现了大量的executor超过内存限制被Yarn杀掉的情况。而无分区进行数据迁移时,executor对内存几乎没有任何要求。
从这里的现象可以大致分析出,spark在无分区时使用了流式的数据处理机制,无需占用过多内存,但是一旦引入分区则对内存就提出了更多的要求。(测试spark版本为2.3.2)。
总结
本文总结了Oracle的数据导入导出相关工作,分享了一些实操经验。
参考
官方数据导入导出文档:
- https://docs.oracle.com/cd/E17781_01/server.112/e18804/impexp.htm#BABCJCBD
- https://oracle-base.com/articles/10g/oracle-data-pump-10g
- https://docs.oracle.com/cd/E11882_01/server.112/e22490/dp_import.htm#SUTIL929
字符集转换:https://my.oschina.net/u/2291124/blog/392174
表空间:https://www.cnblogs.com/fnng/archive/2012/08/12/2634485.html