面向对象的程序设计思想多年来一直是我们进行软件设计的有效的指导思想。由于我们天生理解大自然的机制就是面向对象的(比如我们到了某一个商店,我们会看到门店、售货员、货架、货架上的货物等等,这些都是一个一个的对象,我们认识整个商店也就是去认识商店中的每个对象。),而面向对象程序设计思想恰好与这一机制相一致,所以一个面向对象设计做得好的系统就很容易为我们所理解。
对于一个机器学习平台,应该如何实践面向对象程序设计思想呢?
面向对象的抽象
回顾前面两篇文章的内容,机器学习平台具备这样的架构:
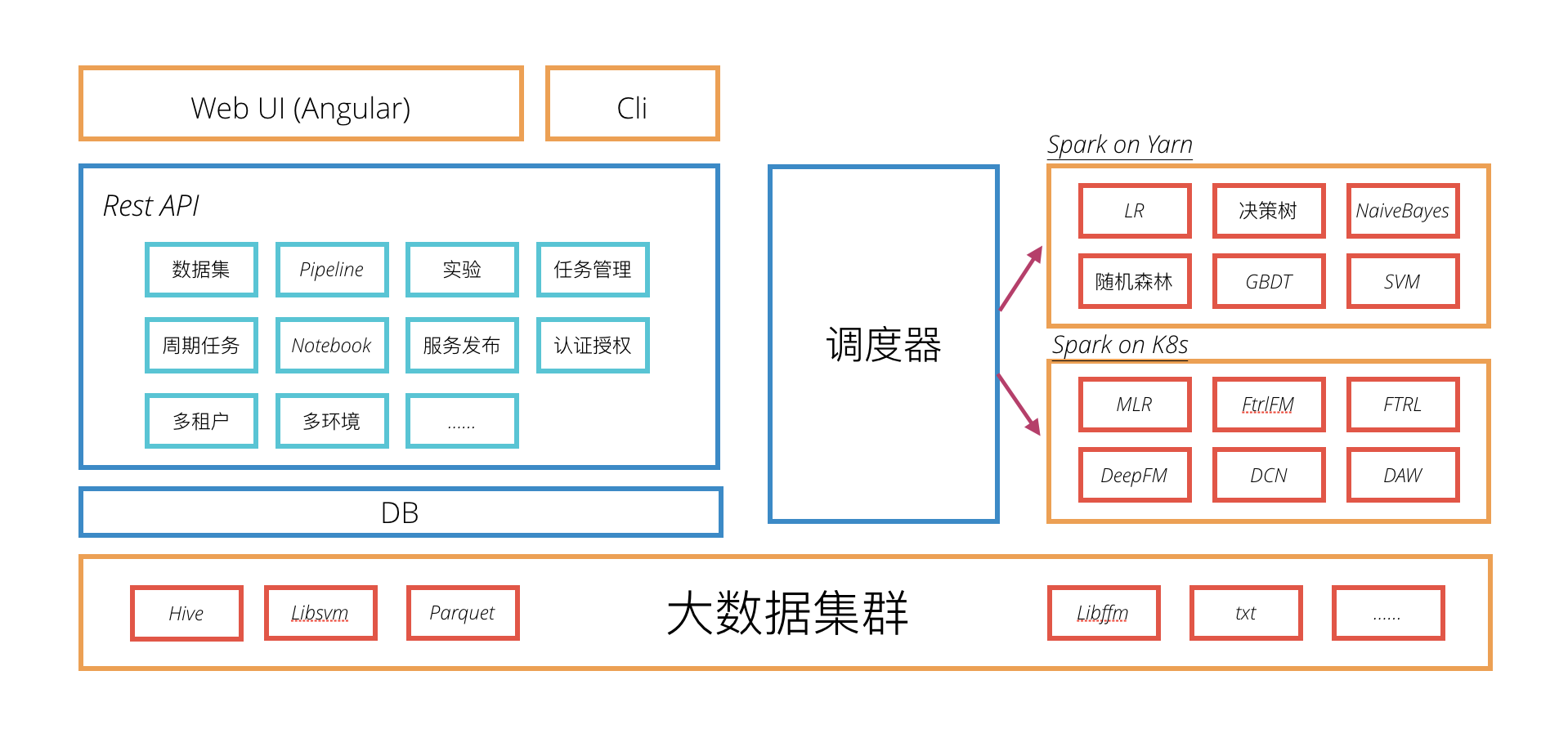
看了这个架构,一些重要的对象就自然的浮现了出来。比如数据集(DataSet)、Pipeline、实验(Experiment)、任务(Job)、周期任务(PeriodicalJob)、服务(Service)等。
经过前面关于微服务架构设计的分析,我们可以发现,随着系统的功能越来越复杂,这里的几个对象事实上都逐渐的发展为了某个大的模块或者某个候选的微服务。尽管如此,它们依然是这些模块或者微服务内的核心对象。
这里的对象抽象看似简单,但是如果缺乏经验,经常会出的一个问题是将这些对象与数据库存储的表强耦合在一起。这里的强耦合的表现就是:
- 从设计数据库开始,而不是先从面向对象设计开始
- 直接使用
ORM框架生成的对象作为核心对象使用 - 直接使用
ORM框架生成的对象操作器(如Spring的JPA中由接口继承而来的XXXRepository)作为领域服务来使用
使用框架生成的代码通常看起来已经可以完成大部分的工作了,这是一个很大的诱惑,如果我们没有保持克制,随意的去使用这些已有的功能,就会使得我们的代码大量的被ORM框架技术所侵入,从而变得臃肿且笨重,难以适应业务的变化。
举一个例子。我们都知道,ORM框架会建模对象间的关系,并在读取关联对象时自动生成一条查询语句到数据集中提取关联对象,这个特性非常好用。但当我们在操作一个比较大的列表时,这样的默认实现就可能会导致非常多的关联表查询发往数据库,这不是我们想要的,因为它会带来极大的性能影响(好的实现是一次性将所有要访问的数据取出)。更有甚者,如果我们的关联对象本身又有很多其他的关联对象,而我们还将其提取方式设置为了eager,那就会导致更多非预期的数据库查询发生。
在机器学习平台这个系统里面,Job将会关联Pipeline,而Pipeline又会关联其拥有的算子节点列表(PipelineNode),一旦我们想要获取一个Job的列表,并显示与其关联的Pipeline的节点PipelineNode的数量时,上面的问题就发生了。
由于ORM框架会诱惑程序员去使用这些便捷的功能,如果团队中有人没有意识到潜在的性能问题而随意使用,上述情况就会频繁发生。
如何避免这个问题呢?其实很简单,我们只需要把数据库或者ORM框架当做一个实现细节来对待就行了。既然是一个实现细节,在设计阶段就不应该做过多的考虑,甚至可以完全不管。那么进行面向对象系统设计的步骤就应该是:
- 抽取对象,为其选取一个好的名字
- 设计对象的属性和行为(只要能解决当前需求就行,后续根据需求渐进式的添加)
- 根据业务需求,设计对象的持久化服务对象及其方法
- 根据业务需求,设计业务级服务对象(以业务操作来命名,避免直接
CRUD)
以Job为例,上述每一步的输出可以是:
com.xxx.ml.platform.job.model.Job- 如:
Job.isRunningJob.isSparkJobJob.markAsFinished - 定义
JobRepository接口,及其行为比如:JobRepository.findByIdJobRepository.findByStatusJobRepository.save - 定义
JobService业务服务对象,及其行为比如:JobService.createJobJobService.terminateJob
完成这样的设计之后,我们就获得了一些单纯的业务对象,而非一个个数据库表的直接映射了。那么数据库表的映射要如何完成呢?以Job为例,我们可以基于ORM框架很容易的实现一个JobRepository。首先我们要新建立一个对应的数据库实体映射对象并生成对应的数据操作对象(如JobDAO),然后将JobRepository接口的实现部分代理到JobDAO的接口,再完成数据库实体映射对象到业务对象的拷贝就完成了。
有人说,这样岂不是多写了一个模型,还得多写一些对象间拷贝的代码?是的,从最终结果上来看,确实多写了一个模型来完成ORM框架所需要的数据库映射,但是这个模型的代码其实非常简单,它不包含任何的业务逻辑,只是单纯的数据。对象属性拷贝的代码更是简单,甚至可以用反射机制来自动完成。
这里的少量新代码是值得的,因为它给我们带来了巨大的灵活性,避免了我们的系统直接依赖于某一个特定的ORM框架。这些灵活性比如:
- 可以轻易的替换
ORM框架 - 可以轻易的替换存储实现,比如从关系型数据库替换为
MongoDB这样的文档型数据库 - 对象的属性可以允许与数据库字段有差异,比如当对象
A中的某个属性b是一个其他对象B的实例,而B又不值得新建一个数据库表来存储时,我们就可以手动的将b序列化为一个Json格式的数据在数据库中进行存储 - 可以灵活的使用业务语言进行命名,这也就避免了
ORM框架的命名规范侵入到系统设计里
领域驱动设计方法在当下已经成为了一个指导我们进行设计的重要方法,其中推荐的一个实践就是"领域对象不应该有除标准库外的任何依赖"。采用上述面向对象设计的做法就可以实现核心对象(这里的核心对象其实就是领域对象)没有任何除标准库外的依赖。
识别扩展点并进行面向对象抽象
机器学习平台最大的扩展点莫过于算子和算法模型了。从业务的角度出发,应该支持尽量多的算子和算法模型,以便开发机器学习模型的工程师可以在进行特征处理和算法选择时开箱即用。
按照前面的面向对象设计思路,这里的核心对象可以是Operator和AlgorithmModel对象。同时,我们将支持不同类型的这两类对象。比如对于下面这样的特征处理流程,里面就涉及归一化 分桶 独热编码等等算子。
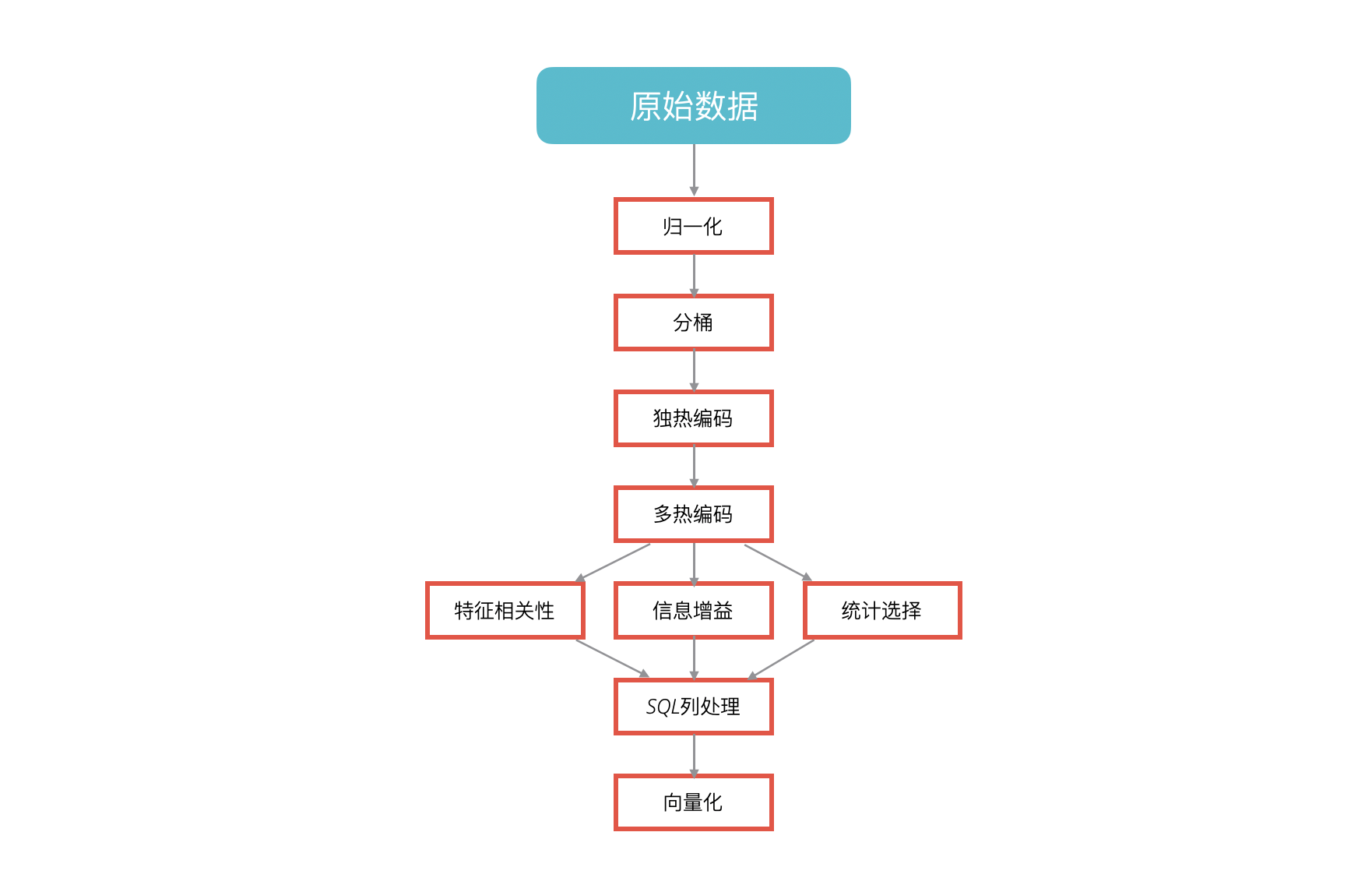
此时,从面向对象设计来看,一个自然的想法就是抽象出一个继承关系了。于是就可以得出下面这样的继承树:
1 | Operator |
对于AlgorithmModel,同样可以得出类似下面这样的继承树:
1 | AlgorithmModel |
到这里,很容易产生的一个疑问就是:这些对象如何存储到数据库里面呢?如果我们没有从面向对象的角度出发进行系统设计,而是优先考虑如何在数据库中存储这些数据,那么我们很有可能就只是得出了一个Operator或AlgorithmModel对象。缺乏继承树抽象将给系统带来非常大的问题,可以预见,不同的算子或算法模型将存在差异(如不同的算法需要的参数不同),如果只有一个Operator或AlgorithmModel抽象而没有继承树,处理这些差异的代码就只能放在Operator或AlgorithmModel对象中。这将导致Operator或AlgorithmModel的逻辑非常复杂,最终导致难以维护的代码。
那么,当有了继承树的时候,如何将这些数据有效的存入数据库呢?难道要对每一个子类都建立一张数据库表吗?其实完全没有必要,由于数据库存储只是一个实现细节,那么数据库里面可以只有operator和algorithm_model表。我们可以在超类Operator或AlgorithmModel中定义一个抽象的获取需要保存的属性的方法,这个方法将返回一个列表,由子类实现,就可以了。
既然算子和算法是系统最大的两个扩展点,我们就需要让添加算子和算法变得足够轻松。有了上述面向对象的抽象,我们就可以将很多公共的逻辑放到父类中去实现,这样添加一个一般的算子和算法就可以很快实现了。
从这里的分析可以发现,好的面向对象设计给系统带来了巨大的灵活性,它使得系统非常易于理解和修改。我们的平台也正是因为建立了这样的设计,才得以快速的演进。
使用TDD辅助进行复杂的模块设计
除了上面简单的面向对象设计,整个系统中还存在一些比较复杂的场景。比如,对于API模块而言,它的作用是作为一个后端服务来管理前端系统界面上面的配置,我们还需要一个Scheduler调度器模块来负责将任务调度到计算平台上面去执行。
这里我们以一个典型的场景为例来描述一下需求。比如用户配置了一条特征处理Pipeline,调度器需要将其打包为一个调度平台上面可以运行的任务,然后发送到调度平台上运行。在运行过程中,用户可以随时查看任务的执行状态,打印的日志等内容。同时,用户可以随时中断任务的执行。当任务结束时,系统需要记录任务的状态,包括结束时间、运行时长等,还需要转存任务日志以便用户可以随时进行查询,对于有后续任务的情况,还需要以适当的方式处理后续任务(调度起来或者设置为失败)。
用一张状态图来描述一个任务的状态转换,可以得到下图:
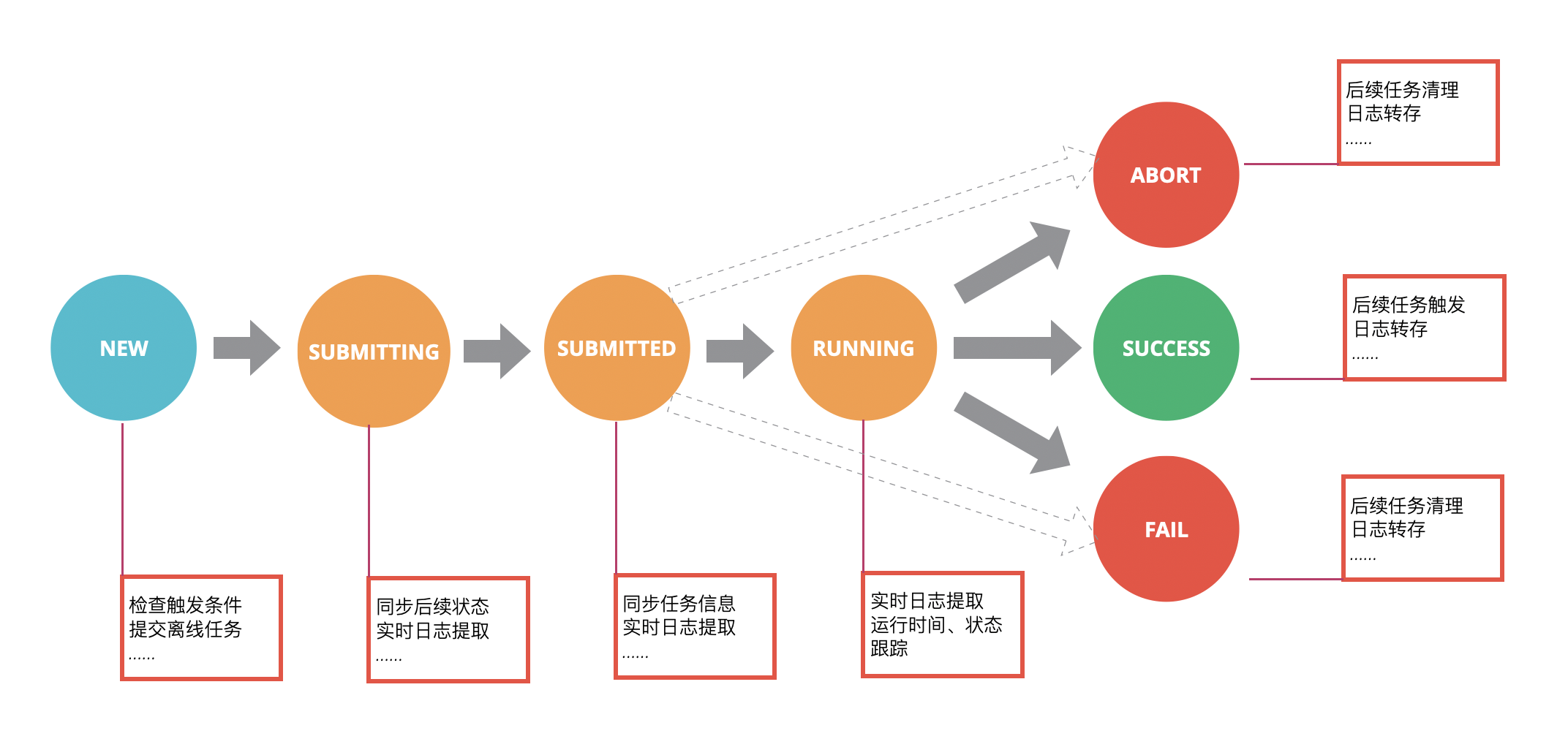
调度器的基本运行机制是:
- 从数据库获取待执行的新任务,并调度到计算平台(如
Yarn或Kubernetes)上面运行 - 从数据库获取其他状态的任务,并针对不同的状态执行对应的操作
- 向计算平台获取任务状态,同步到数据库中以便让用户及时查询,同时执行该状态对应的操作
可以看到,这里的业务逻辑是比较复杂的,如果没有合适的抽象,我们很可能会写出很多重复而难以维护的代码。
如何进行设计才能有效的将问题简化呢?其实看到上面的状态图,我们就应该可以想到:是不是可以用有限状态机来进行抽象?
这是一个基本的想法,如何去实现呢?对于这样的复杂场景,就需要TDD来指导我们进行设计了。
我们先从测试的角度来考虑整个系统应该如何运行。对于一个一般的有限状态机,它应该可以让使用者注册一系列状态转换处理器,以便当某个任务到达某一状态时就运行起来。于是,我们可以编写以下测试代码:
1 | JobStarter jobStarter = mock(JobStarter.class); |
有了这样的测试代码,实际上我们的整个系统设计就呼之欲出了。它将包含这样几个对象:JobStarter JobLogFetcher JobStatusFetcher JobFsm等。不仅如此,每个对象所需要定义的接口也都在测试代码里面定义好了。
从这里的设计来看,TDD在其中发挥的作用可谓非常明显。它辅助我们为对象取好了名字,为对象定义好了行为,同时连行为应该具有的函数签名也定义出来了。而且当回头来看这里得出的系统设计时,我们将发现这里定义的接口不多不少,恰好够用,且各处的命名均符合使用业务语言命名的推荐实践。这正是TDD辅助进行系统设计所带来的功效!
为什么TDD可以指导我们进行复杂系统设计?这是因为使用TDD时,我们完全是站在如何使用这些(将要设计出来的)API的角度来编写(测试)代码的。既然是这样,我们最终获得的API设计也因此变得易于使用。
这里的逻辑也可以这样来理解,比如,我们的需求是拧一颗螺丝,如果我们直接去做设计,而不是采用TDD的方法,我们很可能会去找来一个万用螺丝刀。而如果采用TDD的方法,我们会先确定螺丝的类型(梅花还是十字)和大小(为了能编写测试,自然需要先确认需要对接的接口),然后再根据需求去实现一个对应的恰好合适的螺丝刀。对于生活使用时,万用螺丝刀可能更好,但对于软件开发而言,万用螺丝刀的开发和维护成本可能要数倍于一个刚好合适的螺丝刀,且万用螺丝刀通常还没有专用的螺丝刀简单好用。
类似这样的例子,在我们的系统里面还有很多,就不详述了。
总结
在机器学习平台架构设计上,采用面向对象设计思想,我们获得了一个灵活易用的系统。总结起来,有以下三点经验:
- 进行系统设计时,应当把数据库
ORM技术当做一个实现细节,而非让这些技术主导了设计过程 - 识别系统的扩展点,专门为其做出合适的设计
- 采用
TDD的方式来指导复杂系统的设计
如果想了解更多,欢迎留言一起探讨。